The data for this assignment comes from an online Ipsos survey that was conducted for the FiveThirtyEight article “Why Many Americans Don’t Vote”. You can read more about the survey design and respondents in the README of the GitHub repo for the data.
Respondents were asked a variety of questions about their political beliefs, thoughts on multiple issues, and voting behavior. We will focus on using the demographic variables and someone’s party identification to understand whether a person is a probable voter.
The variables we’ll focus on were (definitions from the codebook in data set GitHub repo):
ppage: Age of respondent
educ: Highest educational attainment category.
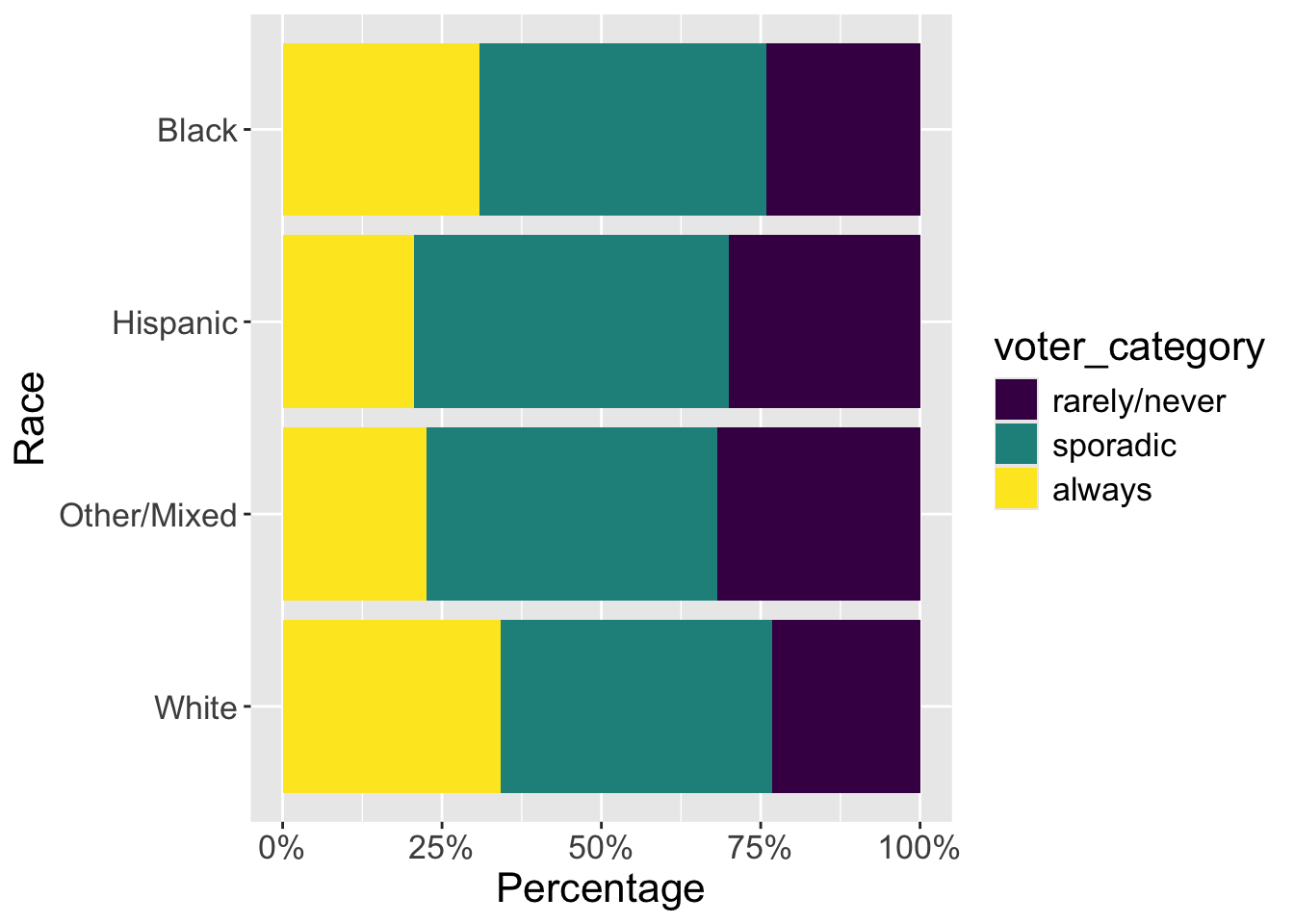
race: Race of respondent, census categories. Note: all categories except Hispanic were non-Hispanic.
gender: Gender of respondent
income_cat: Household income category of respondent
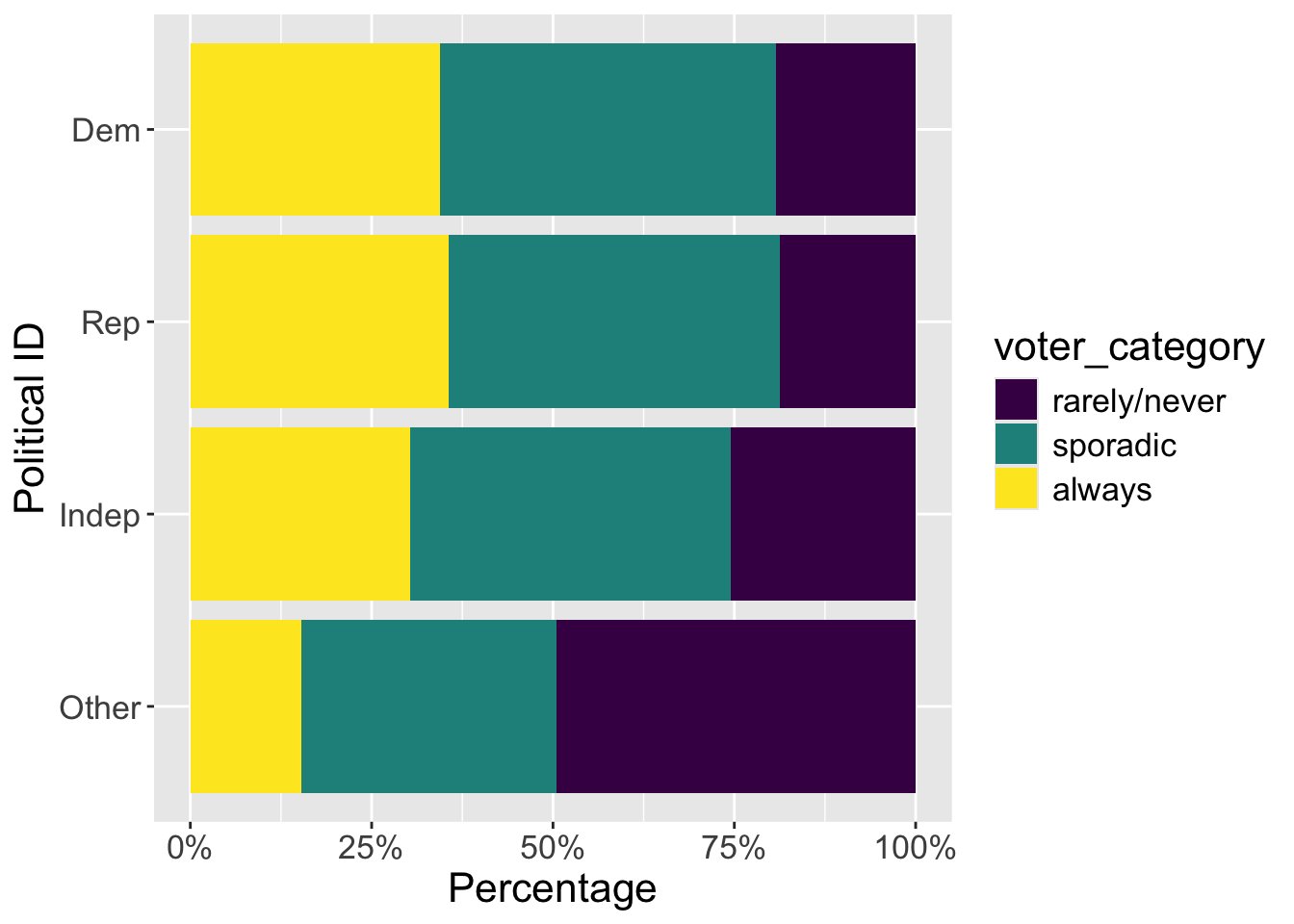
Q30: Response to the question “Generally speaking, do you think of yourself as a…”
1: Republican
2: Democrat
3: Independent
4: Another party, please specify
5: No preference
-1: No response
voter_category: past voting behavior:
always: respondent voted in all or all-but-one of the elections they were eligible in
sporadic: respondent voted in at least two, but fewer than all-but-one of the elections they were eligible in
rarely/never: respondent voted in 0 or 1 of the elections they were eligible in
You can read in the data directly from the GitHub repo:
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ dplyr::recode() masks car::recode()
✖ purrr::some() masks car::some()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Rows: 5836 Columns: 119
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (5): educ, race, gender, income_cat, voter_category
dbl (114): RespId, weight, Q1, Q2_1, Q2_2, Q2_3, Q2_4, Q2_5, Q2_6, Q2_7, Q2_...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Lab
The variable Q30 contains the respondent’s political party identification. Make a new variable that simplifies Q30 into four categories: “Democrat”, “Republican”, “Independent”, “Other” (“Other” also includes respondents who did not answer the question).
The variable voter_category identifies the respondent’s past voter behavior. Relevel the variable to make rarely/never the baseline level, followed by sporadic, then always
# center varvoter_data$ppage <- datawizard::center(voter_data$ppage)
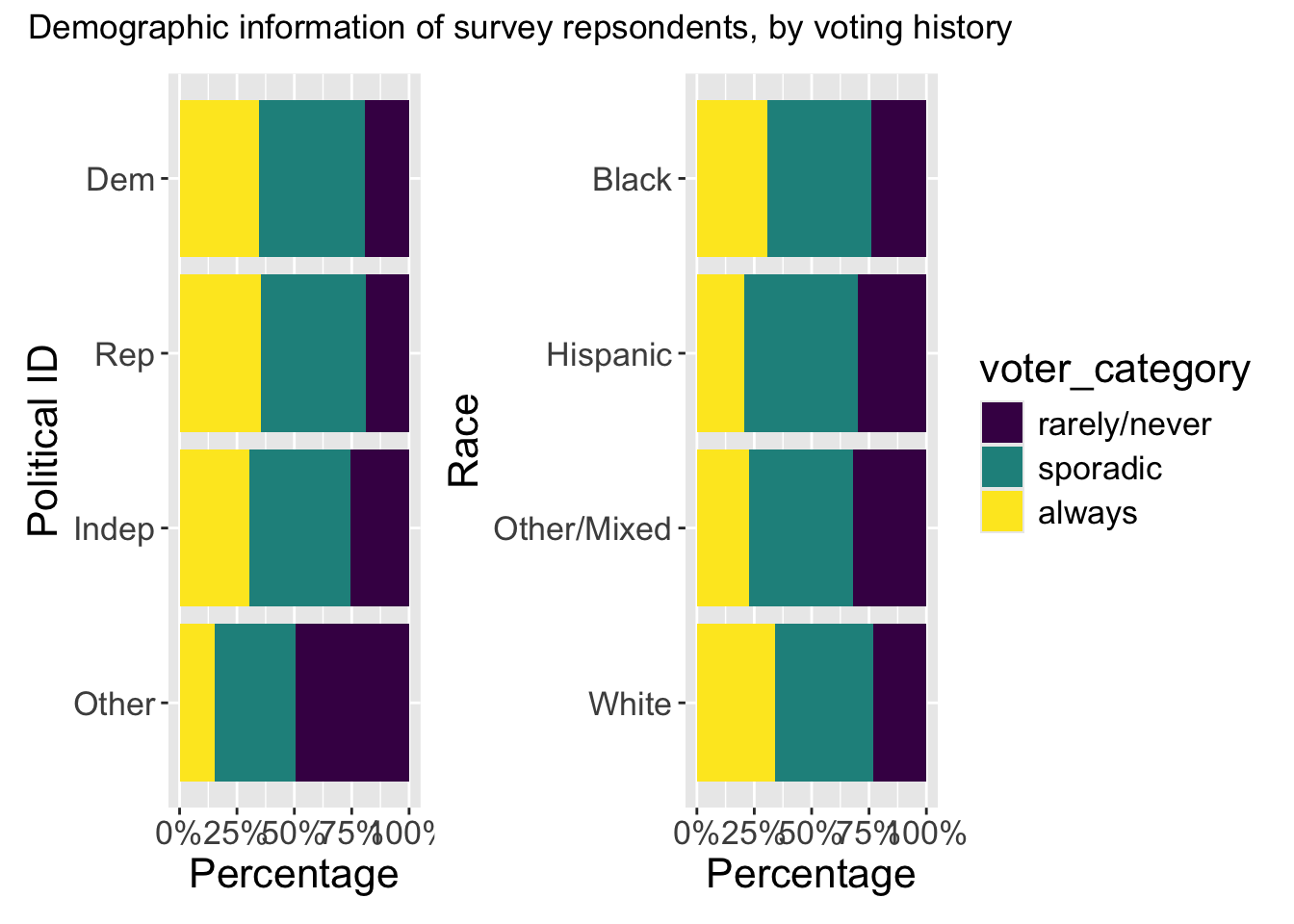
In the FiveThirtyEight article, the authors include visualizations of the relationship between the voter category and demographic variables such as race, age, education, etc. Select two demographic variables. For each variable, try to replicate the visualizations and interpret the plot to describe its relationship with voter category. Have fun with it: https://www.mikelee.co/posts/2020-02-08-recreate-fivethirtyeight-chicklet-stacked-bar-chart-in-ggplot2.
# librarylibrary(ggplot2)library(viridis)
Loading required package: viridisLite
library(cowplot)
Attaching package: 'cowplot'
The following object is masked from 'package:patchwork':
align_plots
The following object is masked from 'package:ggeffects':
get_title
The following object is masked from 'package:lubridate':
stamp
library(patchwork)p_id+ p_race +plot_layout(guides ="collect") +plot_annotation(title ='Demographic information of survey repsondents, by voting history')
Fit a model using mean-centered age, race, gender, income, and education to predict voter category. Show the code used to fit the model, but do not display the model output.
ppage, \(\chi^2(2)\) = 666.41, educ, \(\chi^2(4)\) = 252.81, p < .001, and pol \(\chi^2(6)\) = 171.91, p < .001
mm_use %>%tidy() %>%kable()
y.level
term
estimate
std.error
statistic
p.value
sporadic
(Intercept)
1.5221680
0.0822932
18.4968772
0.0000000
sporadic
ppage
0.0457443
0.0023031
19.8621499
0.0000000
sporadic
educHigh school or less
-1.0372010
0.0877549
-11.8192889
0.0000000
sporadic
educSome college
-0.3864438
0.0904127
-4.2742199
0.0000192
sporadic
polRep
-0.0388733
0.0964455
-0.4030594
0.6869045
sporadic
polIndep
-0.3802996
0.0941814
-4.0379495
0.0000539
sporadic
polOther
-0.9621902
0.1042842
-9.2266187
0.0000000
always
(Intercept)
1.3124074
0.0867341
15.1313876
0.0000000
always
ppage
0.0590465
0.0025373
23.2711612
0.0000000
always
educHigh school or less
-1.4771769
0.0984861
-14.9988400
0.0000000
always
educSome college
-0.4481505
0.0969629
-4.6218753
0.0000038
always
polRep
-0.0020977
0.1027836
-0.0204086
0.9837174
always
polIndep
-0.4879135
0.1025275
-4.7588553
0.0000019
always
polOther
-1.4043029
0.1287482
-10.9073562
0.0000000
Marginal Effects Political Group - Emmeans
multi_an <-emmeans(mm_use, ~ pol|voter_category)# uses baseline as contrast of interest# can change this to get other baselines# use trt.vs.ctrl" #ref = newbaselinecoefs =contrast(regrid(multi_an, "log"),"trt.vs.ctrl1", by="pol")update(coefs, by ="contrast") %>%kable(format ="markdown", digits =3)
contrast
pol
estimate
SE
df
t.ratio
p.value
sporadic - (rarely/never)
Dem
0.963
0.064
14
15.001
0.000
always - (rarely/never)
Dem
0.608
0.067
14
9.051
0.000
sporadic - (rarely/never)
Rep
0.925
0.071
14
13.089
0.000
always - (rarely/never)
Rep
0.606
0.074
14
8.233
0.000
sporadic - (rarely/never)
Indep
0.600
0.069
14
8.660
0.000
always - (rarely/never)
Indep
0.144
0.075
14
1.933
0.217
sporadic - (rarely/never)
Other
0.054
0.081
14
0.673
0.866
always - (rarely/never)
Other
-0.723
0.105
14
-6.873
0.000
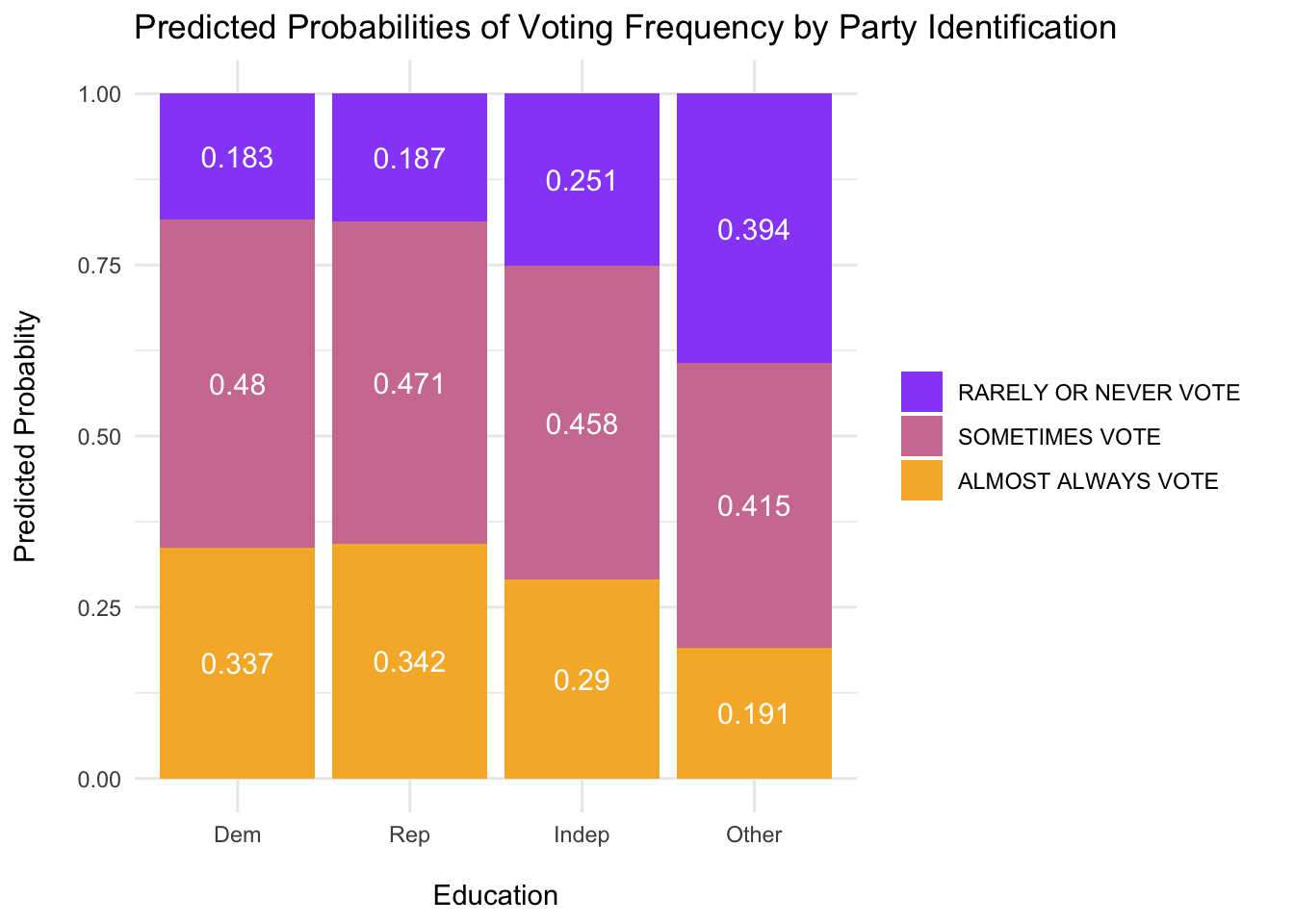
For every political party listed, voting is more likely. That is, Democrats (sporadic - (rarely/never) 2.6195433, Republicans(sporadic - (rarely/never 2.5092904, and Independents (sporadic - (rarely/never1.8221188 were more likely to sporadically vote compared to rarely/never. Voters affiliated with a political party were also more likely to always vote compared to never/rarely vote (Democrats:1.8367542; Republicans: 1.8404314; Independents: 1.1502738 ). The exception here is Other. Others were more likely to rarely vote compared to always vote (0.4852942
Marginal Effects of Education - Emmeans
multi_an <-emmeans(mm_use, ~ educ|voter_category)# uses baseline as contrast of interest# can change this to get other baselines# use trt.vs.ctrl" #ref = newbaselinecoefs =contrast(regrid(multi_an, "log"),"trt.vs.ctrl1", by="educ")update(coefs, by ="contrast") %>%kable(format ="markdown", digits =3)
contrast
educ
estimate
SE
df
t.ratio
p.value
sporadic - (rarely/never)
College
1.101
0.068
14
16.299
0.000
always - (rarely/never)
College
0.781
0.070
14
11.193
0.000
sporadic - (rarely/never)
High school or less
0.112
0.057
14
1.974
0.167
always - (rarely/never)
High school or less
-0.629
0.068
14
-9.296
0.000
sporadic - (rarely/never)
Some college
0.728
0.067
14
10.811
0.000
always - (rarely/never)
Some college
0.352
0.071
14
4.951
0.001
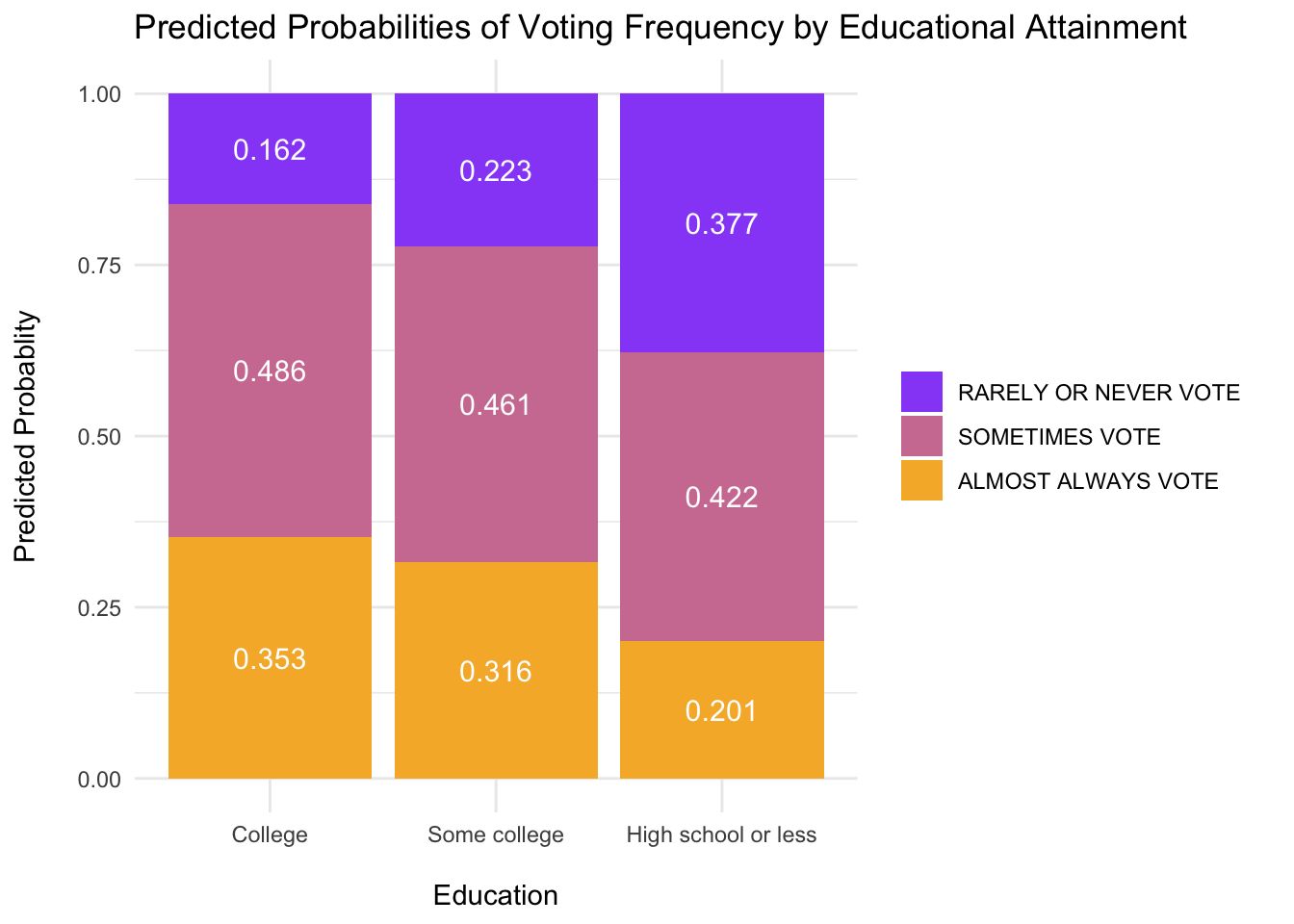
College educated (OR = 3.004166), High school or less (OR = 1.1185129), and Some college (OR = 1.1185129) were more likely to sporadically vote compared to rarely/never. College educated voters (OR = 1.1185129), and some college (OR = 1.1185129) were always more likely to vote compared to rarely/never. High school or less (OR = 0.5331247) were less likely to always vote compared to rarely/never.
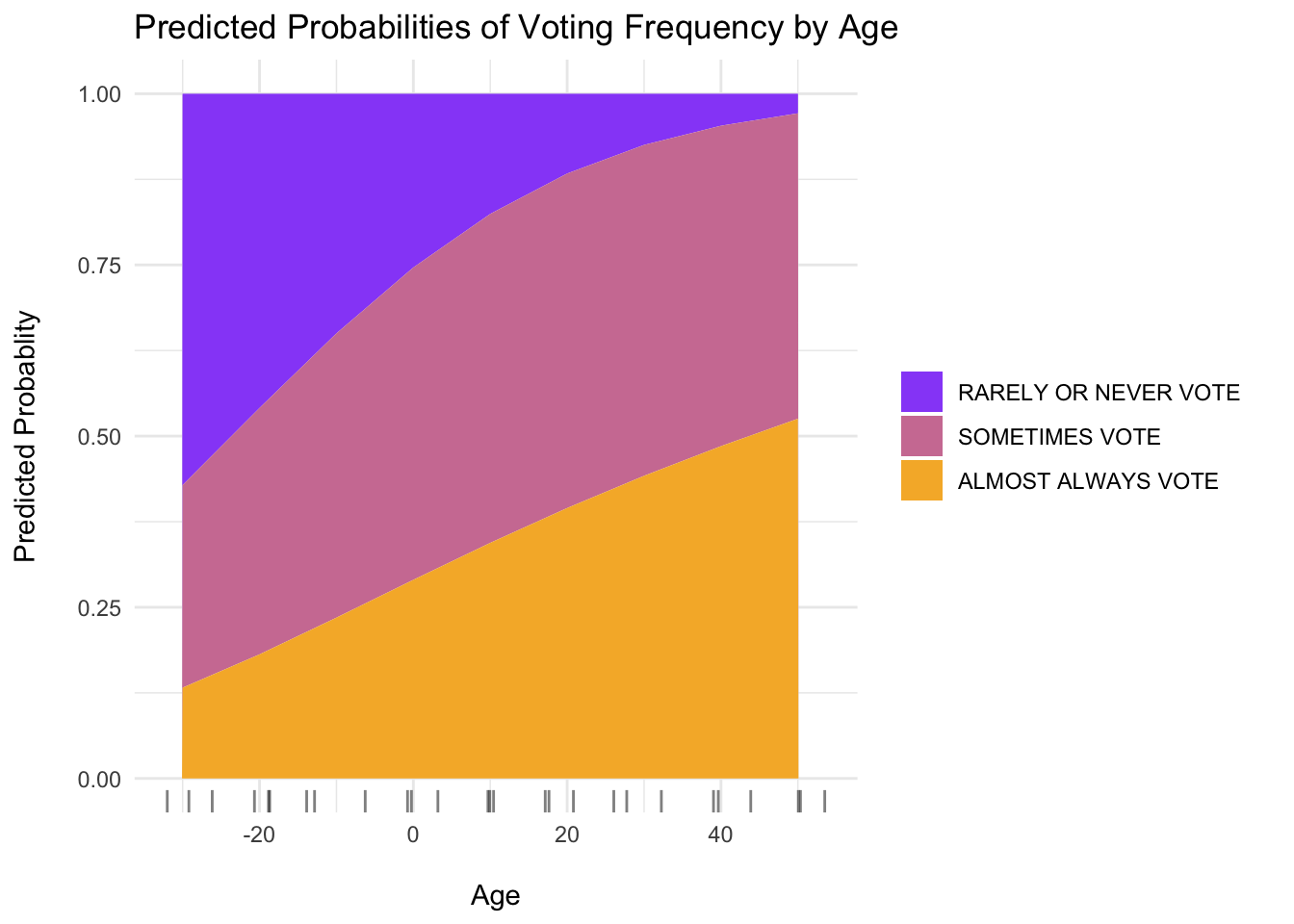
Next, plot the predicted probabilities of voter category as a function of Age and Party ID
ggemmeans(mm_use, terms =c("ppage")) %>%ggplot(., aes(x = x, y = predicted, fill = response.level)) +geom_area() +geom_rug(sides ="b", position ="jitter", alpha = .5) +labs(x ="\nAge", y ="Predicted Probablity\n", title ="Predicted Probabilities of Voting Frequency by Age") +scale_fill_manual(name =NULL,values =c("always"="#F6B533", "sporadic"="#D07EA2", "rarely/never"="#9854F7"),labels =c("RARELY OR NEVER VOTE ", "SOMETIMES VOTE ", "ALMOST ALWAYS VOTE "),breaks =c("rarely/never", "sporadic", "always") ) +theme_minimal()
Data were 'prettified'. Consider using `terms="ppage [all]"` to get
smooth plots.
ggemmeans(mm_use, terms =c("educ")) %>%ggplot(., aes(x = x, y = predicted,fill = response.level)) +geom_bar(stat ="identity" ) +geom_text(aes(label =round(predicted, 3)), color="white", position =position_fill(vjust =0.5), size =4) +labs(x ="\nEducation", y ="Predicted Probablity\n", title ="Predicted Probabilities of Voting Frequency by Educational Attainment") +scale_fill_manual(name =NULL,values =c("always"="#F6B533", "sporadic"="#D07EA2", "rarely/never"="#9854F7"),labels =c("RARELY OR NEVER VOTE ", "SOMETIMES VOTE ", "ALMOST ALWAYS VOTE "),breaks =c("rarely/never", "sporadic", "always") ) +theme_minimal()
ggemmeans(mm_use, terms =c("pol")) %>%ggplot(., aes(x = x, y = predicted,fill = response.level)) +geom_bar(stat ="identity" ) +geom_text(aes(label =round(predicted, 3)), color="white", position =position_fill(vjust =0.5), size =4) +labs(x ="\nEducation", y ="Predicted Probablity\n", title ="Predicted Probabilities of Voting Frequency by Party Identification") +scale_fill_manual(name =NULL,values =c("always"="#F6B533", "sporadic"="#D07EA2", "rarely/never"="#9854F7"),labels =c("RARELY OR NEVER VOTE ", "SOMETIMES VOTE ", "ALMOST ALWAYS VOTE "),breaks =c("rarely/never", "sporadic", "always") ) +theme_minimal()
## Write-up
Differences between political groups and voting behavior - Emmeans
multi_an <-emmeans(mm_use, ~ pol|voter_category)# uses baseline as contrast of interest# can change this to get other baselines# use trt.vs.ctrl" #ref = newbaselinecoefs =contrast(regrid(multi_an, "log"),"trt.vs.ctrl1", by="pol")update(coefs, by ="contrast") %>%kable(format ="markdown", digits =3)
contrast
pol
estimate
SE
df
t.ratio
p.value
sporadic - (rarely/never)
Dem
0.963
0.064
14
15.001
0.000
always - (rarely/never)
Dem
0.608
0.067
14
9.051
0.000
sporadic - (rarely/never)
Rep
0.925
0.071
14
13.089
0.000
always - (rarely/never)
Rep
0.606
0.074
14
8.233
0.000
sporadic - (rarely/never)
Indep
0.600
0.069
14
8.660
0.000
always - (rarely/never)
Indep
0.144
0.075
14
1.933
0.217
sporadic - (rarely/never)
Other
0.054
0.081
14
0.673
0.866
always - (rarely/never)
Other
-0.723
0.105
14
-6.873
0.000
# get difference between yes-no and fair-excellentcontrast(coefs, "revpairwise", by ="contrast") %>%kable(format ="markdown", digits =3)
contrast1
contrast
estimate
SE
df
t.ratio
p.value
Rep - Dem
sporadic - (rarely/never)
-0.039
0.094
14
-0.412
0.976
Indep - Dem
sporadic - (rarely/never)
-0.363
0.091
14
-3.974
0.007
Indep - Rep
sporadic - (rarely/never)
-0.324
0.098
14
-3.323
0.023
Other - Dem
sporadic - (rarely/never)
-0.909
0.102
14
-8.934
0.000
Other - Rep
sporadic - (rarely/never)
-0.871
0.106
14
-8.183
0.000
Other - Indep
sporadic - (rarely/never)
-0.546
0.106
14
-5.176
0.001
Rep - Dem
always - (rarely/never)
-0.002
0.098
14
-0.018
1.000
Indep - Dem
always - (rarely/never)
-0.464
0.097
14
-4.755
0.002
Indep - Rep
always - (rarely/never)
-0.462
0.103
14
-4.464
0.003
Other - Dem
always - (rarely/never)
-1.331
0.124
14
-10.725
0.000
Other - Rep
always - (rarely/never)
-1.329
0.128
14
-10.400
0.000
Other - Indep
always - (rarely/never)
-0.867
0.129
14
-6.739
0.000
Differences between education level and voting behavior - Emmeans
multi_an <-emmeans(mm_use, ~ educ|voter_category)# uses baseline as contrast of interest# can change this to get other baselines# use trt.vs.ctrl" #ref = newbaselinecoefs =contrast(regrid(multi_an, "log"),"trt.vs.ctrl1", by="educ")update(coefs, by ="contrast") %>%kable(format ="markdown", digits =3)
contrast
educ
estimate
SE
df
t.ratio
p.value
sporadic - (rarely/never)
College
1.101
0.068
14
16.299
0.000
always - (rarely/never)
College
0.781
0.070
14
11.193
0.000
sporadic - (rarely/never)
High school or less
0.112
0.057
14
1.974
0.167
always - (rarely/never)
High school or less
-0.629
0.068
14
-9.296
0.000
sporadic - (rarely/never)
Some college
0.728
0.067
14
10.811
0.000
always - (rarely/never)
Some college
0.352
0.071
14
4.951
0.001
# get difference between yes-no and fair-excellentcontrast(coefs, "revpairwise", by ="contrast") %>%kable(format ="markdown", digits =3)
contrast1
contrast
estimate
SE
df
t.ratio
p.value
High school or less - College
sporadic - (rarely/never)
-0.989
0.087
14
-11.414
0.000
Some college - College
sporadic - (rarely/never)
-0.372
0.088
14
-4.212
0.002
Some college - High school or less
sporadic - (rarely/never)
0.616
0.087
14
7.086
0.000
High school or less - College
always - (rarely/never)
-1.410
0.096
14
-14.696
0.000
Some college - College
always - (rarely/never)
-0.429
0.093
14
-4.599
0.001
Some college - High school or less
always - (rarely/never)
0.981
0.097
14
10.150
0.000
A multinomial model was estimated using the nnet package in R to investigate whether political party identification (Democrat, Independent, Republican, Other), education (high school or less, some college, college degree), and age (grand mean centered; M = 51.69) influence voting frequency (rarely or never vote, vote sporadically, almost always vote). All three predictors were significantly associated with voting frequency: party identification, \(\chi^2\) (6) = 171.91, p < .001; education, \(\chi^2\) (4) = 252.81, p < .001; and age, \(\chi^2\) (2) = 666.41, p < .001, \(R^2_{mcfadden}\) = .09. The odds of Independents (and those who support other parties or none) voting sporadically (versus rarely or never) were lower. Specifically, independents were times less likely compared to Democrats, lower compared to Republicans. Others were 0.4029269 times lower compared to Democrats, lower compared to Republicans. The odds that Republicans, relative to Democrats, voted sporadically was negligible. The pattern of results is similar when comparing the odds of always voting versus rarely or never voting. Supporters of all other parties in our data had lower odds of always voting compared to Democrats (Independents: OR = 0.6287636; Other: OR = 0.2644773) and Republicans (Independents: OR = 0.6300223; Other: OR = 0.2671353.
Those with high school and some college education were more likely to rarely vote compared to sporadically vote compared to college educated persons (High School: OR = 0.3719485, p < .001) and some college (OR = 0.6893542, p < .001) or always (High School: OR = 0.2441433, p < .001) and (some college: OR = 0.6511599, p < .001). Stated a bit differently, college voters were more likely to vote than those with a high school or some college education. We also see that those with some college education vs. High school or less were more likely to sporadically vote (Some College: OR = 1.8515072, p < .001) or always vote (Some College: OR = 2.667122, p < .001) compared to rarely/never vote.
For each one-year increase in age beyond 52 (the mean), the odds of voting sporadically (versus rarely or never) were 1.05 times higher (p < .001) relative to the baseline voter. They were 1.06 times higher for always voting (versus rarely or never).