Multilevel Modeing (with R) Part 1
Princeton University
2024-01-31
Why multilevel modeling?
- Let’s look at the relationship between SES and math achievement
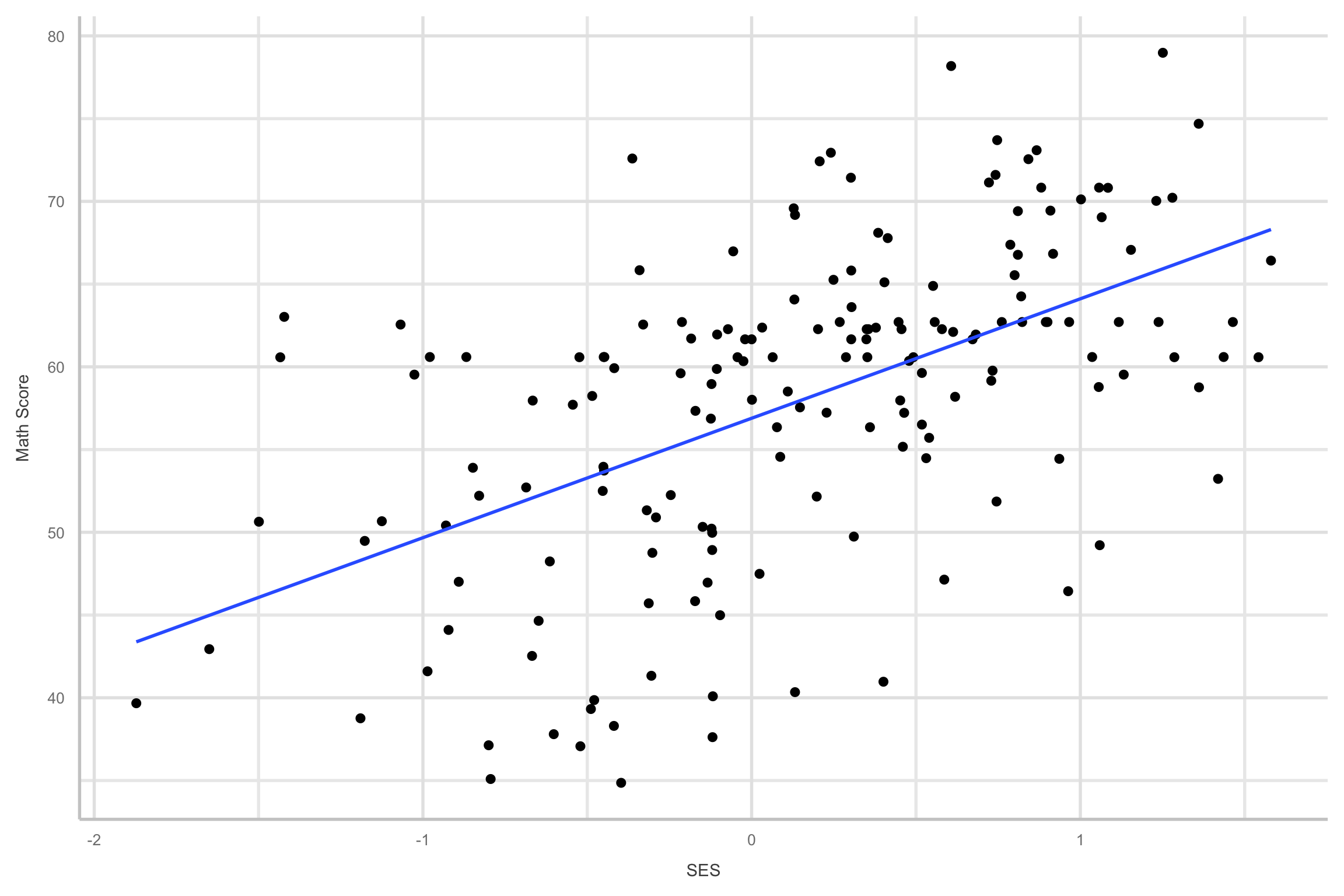
Why multilevel modeling?
- However, if we introduce grouping we tell a slightly different story
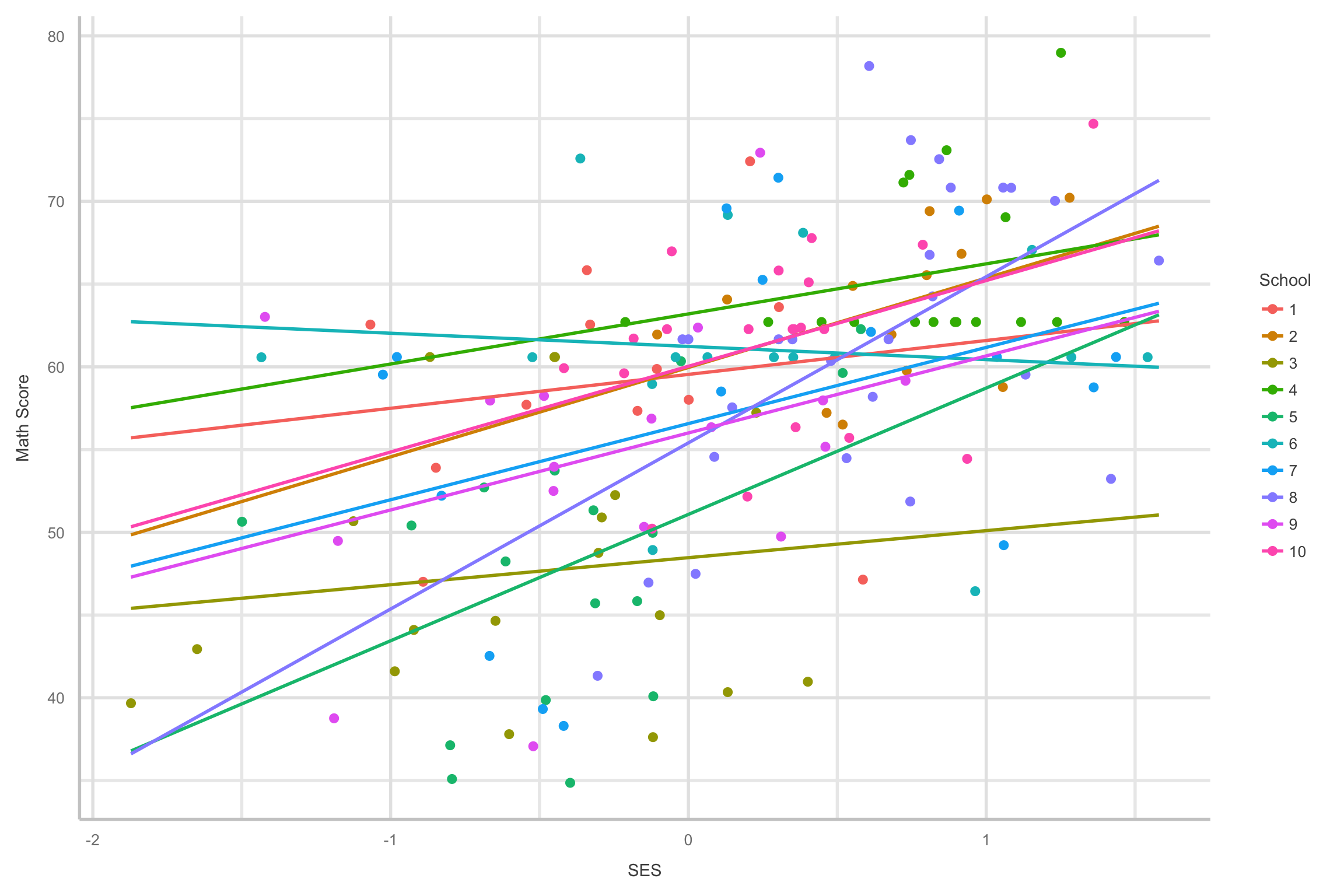
Why multilevel modeling?
Simpson’s paradox
![]()

- A phenomenon in which a trend appears in several groups of data but disappears or reverses when the groups are combined
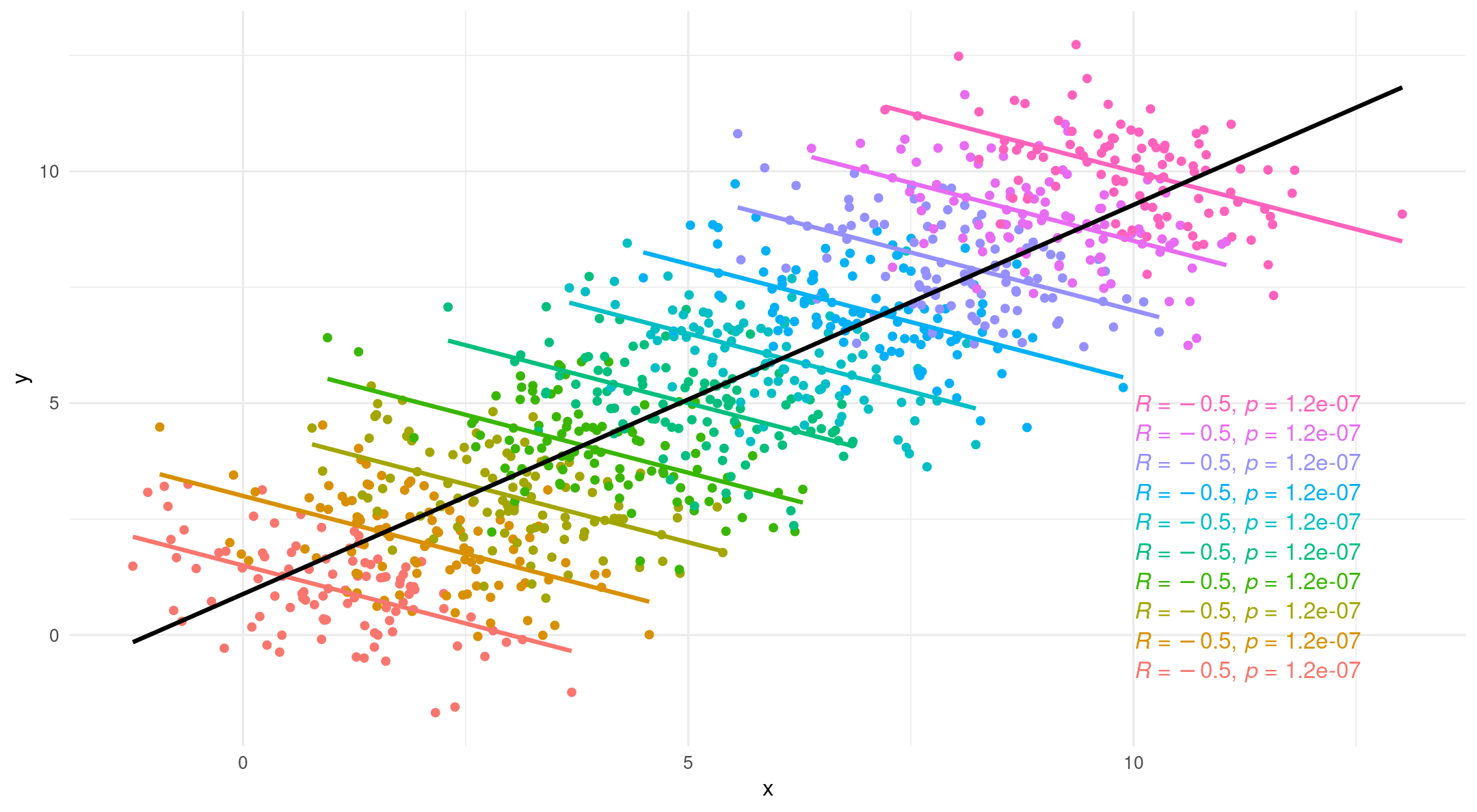
Why multilevel modeling?
The word we live in is highly interdependent!
- Biological, psychological, social processes occur at multiple levels
Why multilevel modeling?

What is multilevel modeling?
Chelsea Parlett-Pelleriti
An elaboration on regression
- just extra errors!
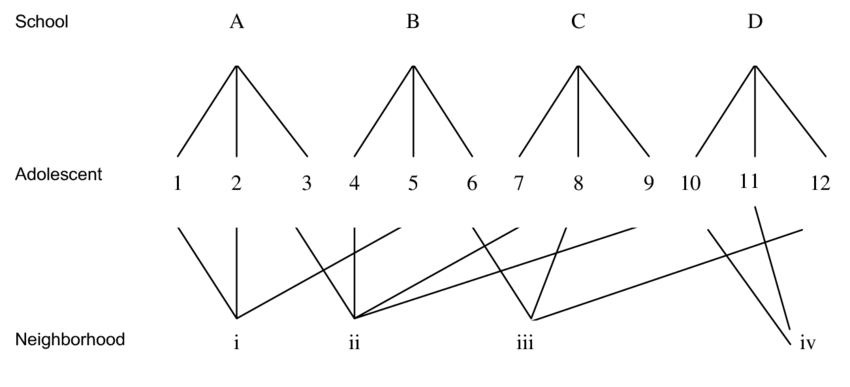
What is a “hierarchy?”
Clustering = Nesting = Grouping = Hierarchies
Key idea: More than one dimension sampling simultaneously
“Nested” designs
Repeated-measures and longitudinal designs
Any complex mixed design
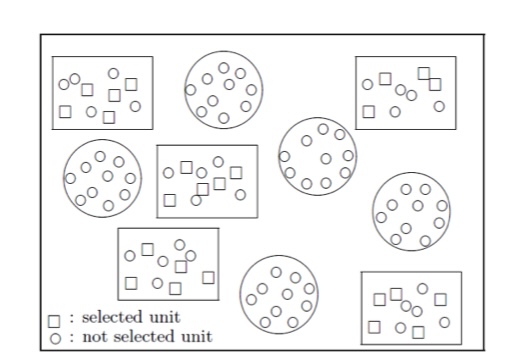
Nested designs

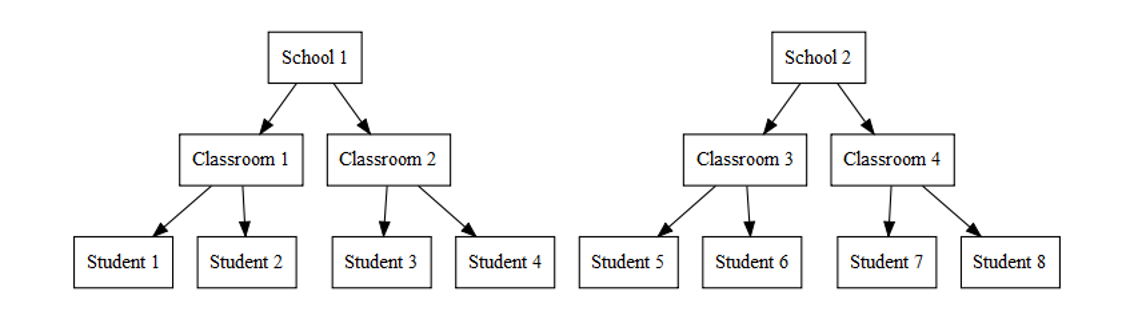
Two-level Hierarchy
- Nested designs
For now we will focus on data with two levels:
- Level one: most basic level of observation
- Level two: groups formed from aggregated level-one observation
Three-level Hierarchy
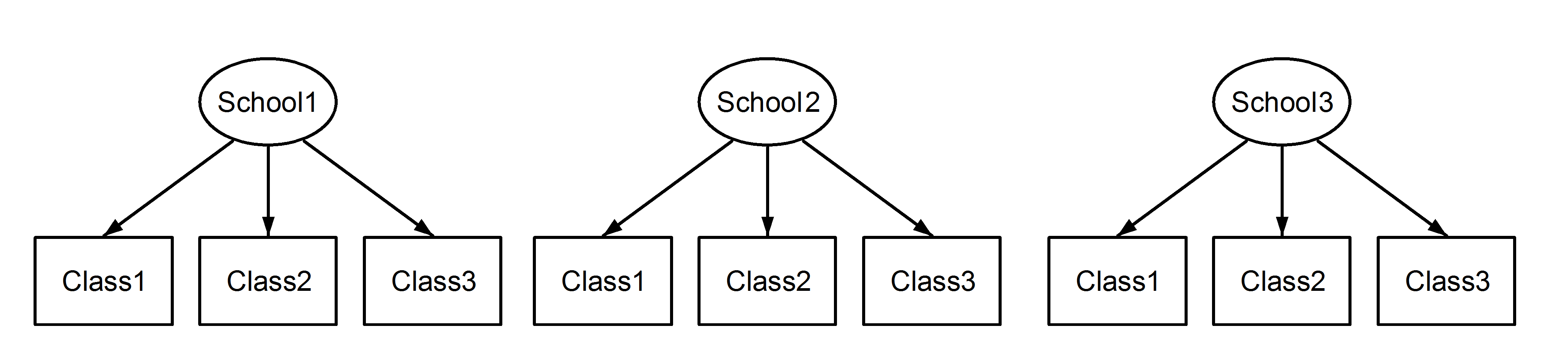
Crossed vs. nested designs
Crossed designs (sometimes called cross-classified)
- When lower units do not belong to only one higher level unit
Repeated designs
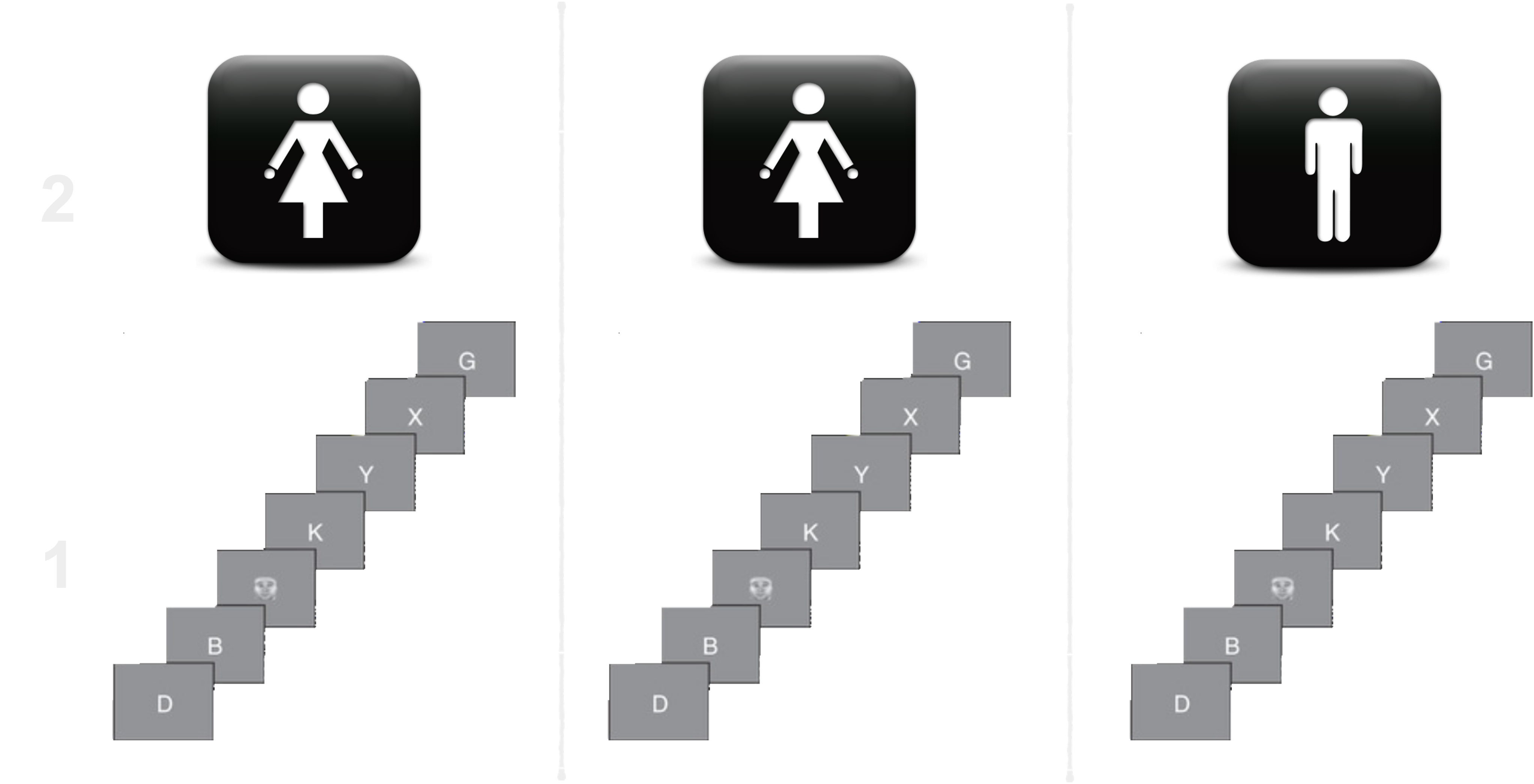
Repeated designs
Repeated designs
Repeated designs
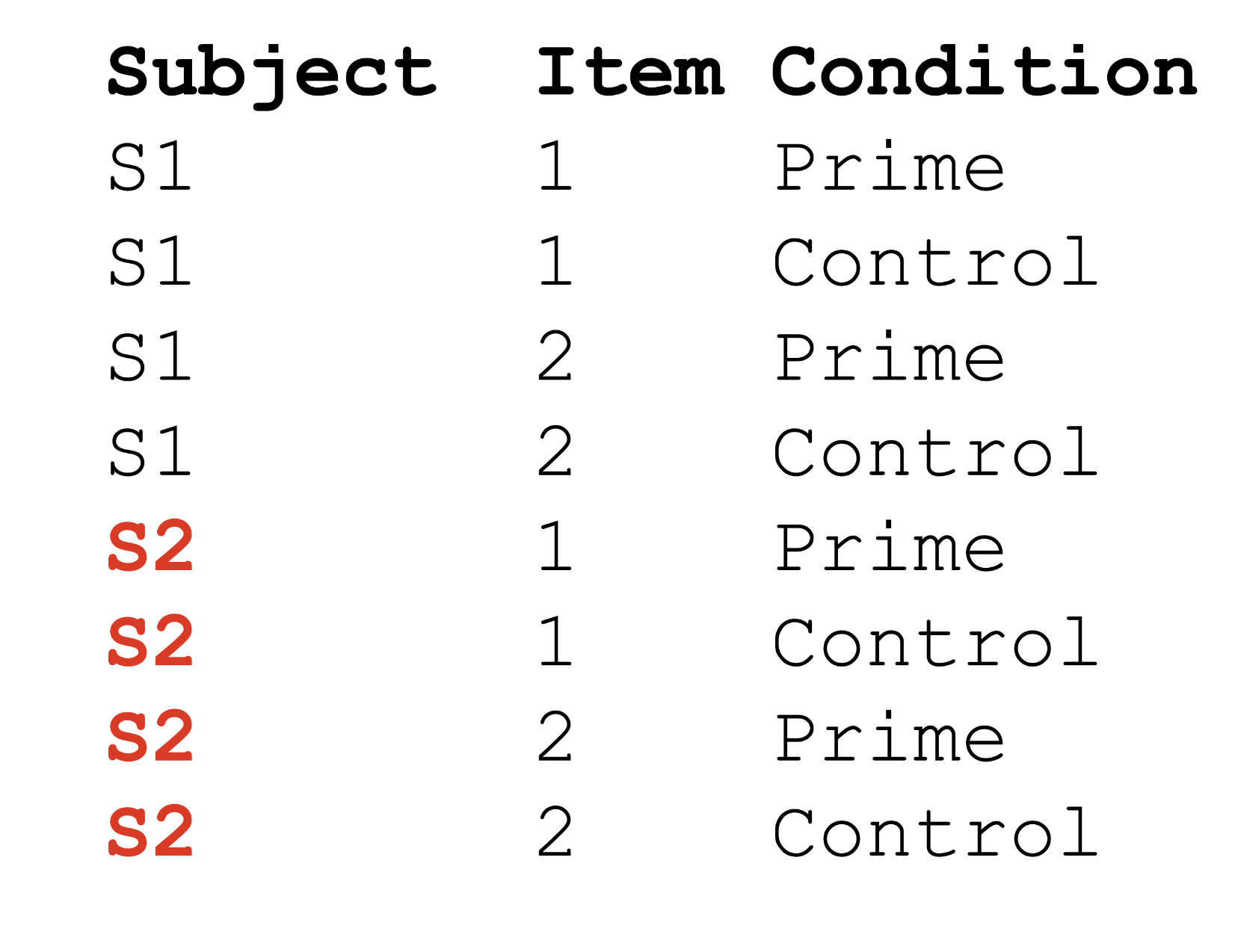
Repeated designs
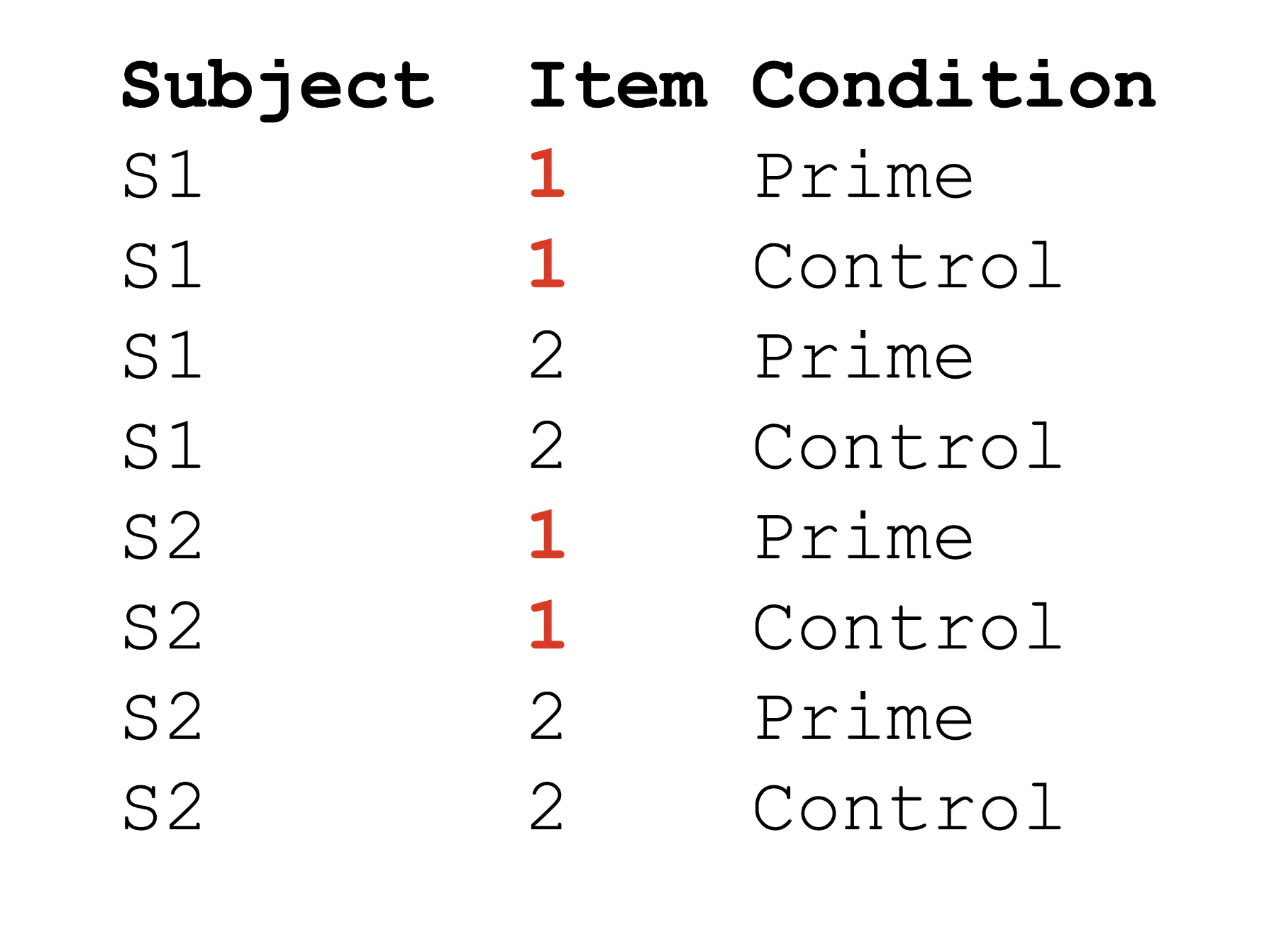
Repeated designs
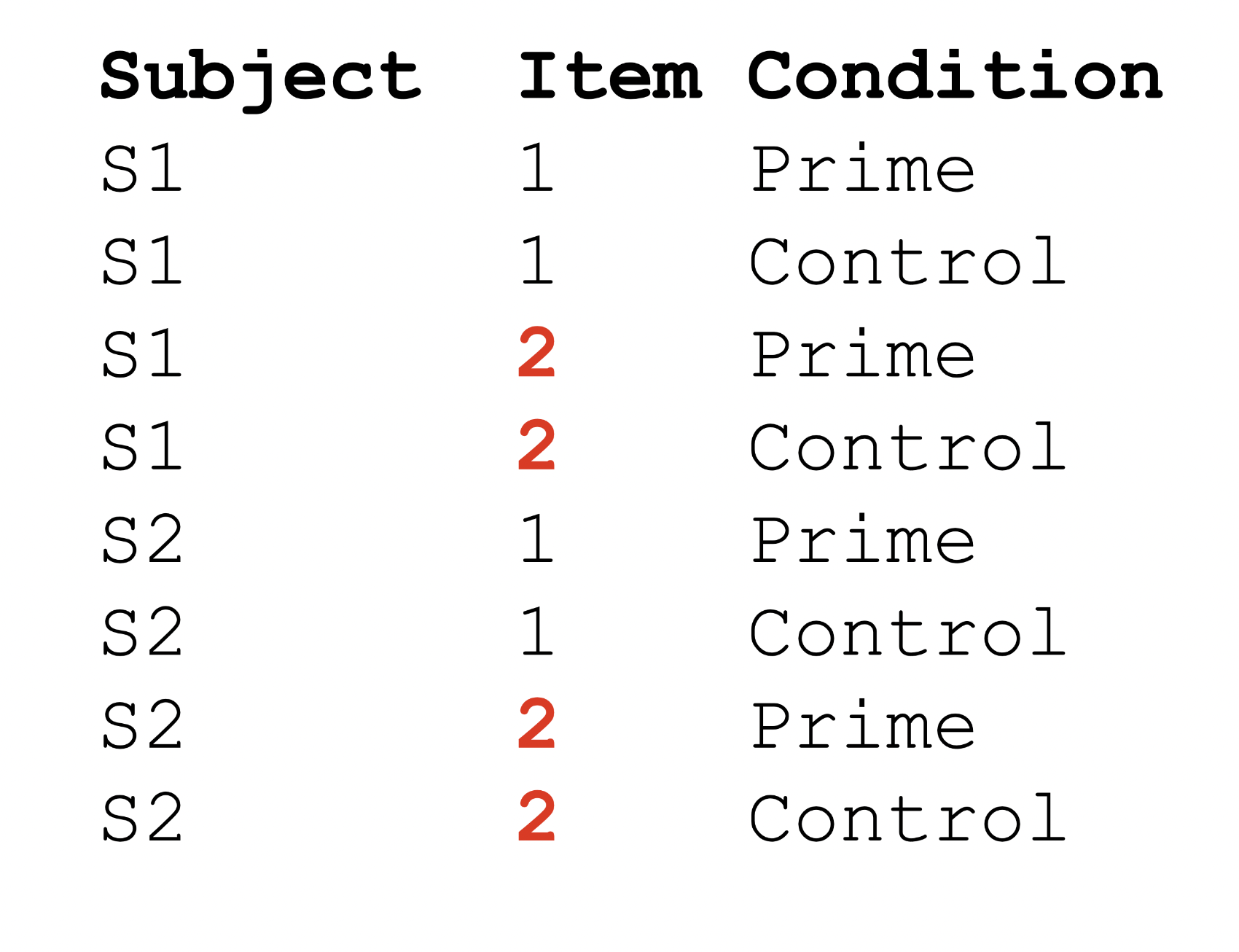
Longitudinal designs
Why MLM is Awesome
- Interdependence
- You can model the relationships between cases (regression for repeated observations)
- Missing data
- Uses ML for missing data
- Power
- Deaggregated data
- Take into account within and between variance
- Flexibility

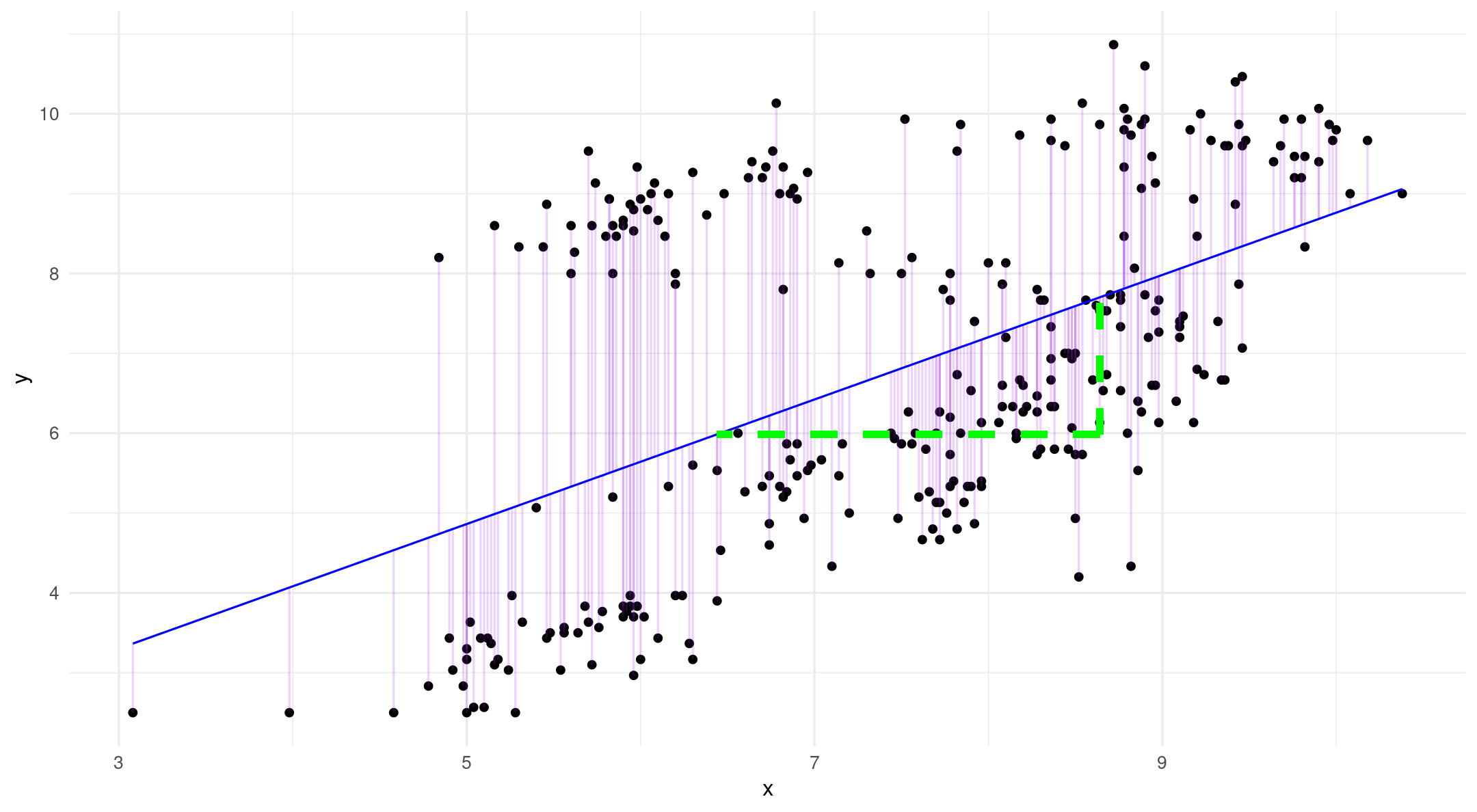
Single-level (fixed) regression
Blue = fixed
Red = random
\[y_i = \color{blue}{b_{0_{\text{(intercept)}}} + b_{1_{\text{(slope)}}} x_i} + \color{red}{ e_{i_{\text{(error)}}}}\]
\[ e_{i_{\text{(error)}}} = y_i - \hat{y}_i \]
Random intercept
- Varying starting point per higher level/group variable
\[ y_{ij} = (\color{blue}{b_{0j_{\text{(intercept)}}}} + \color{red}{U_{0j_{\text{(random intercept)}}}}) + \color{blue}{b_{1_{\text{(slope)}}} x_{ij}} + \color{red}{e_{ij_{\text{(error)}}}} \]
\[ U_{0j} = b_{0j} - b_0 \]
- Between-group variation
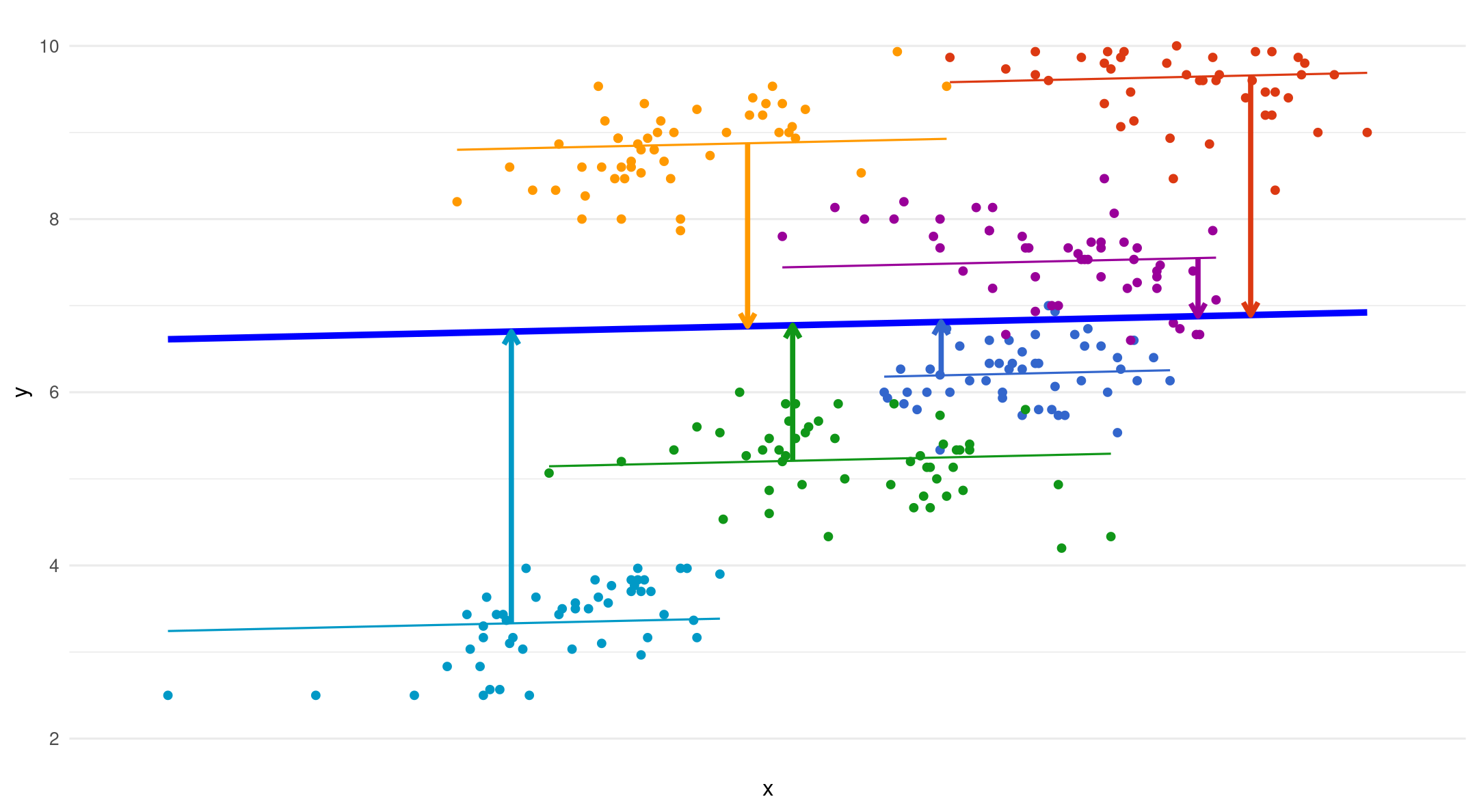
i = individual observation j = group
Random intercepts
\[ y_{ij} = ({b_{0j_{\text{(intercept)}}} + U_{0j_{\text{(random intercept)}}}}) + b_{1_{\text{(slope)}}} x_{ij} + \color{red}{ e_{ij_{\text{(error)}}}} \]
Within-group variation
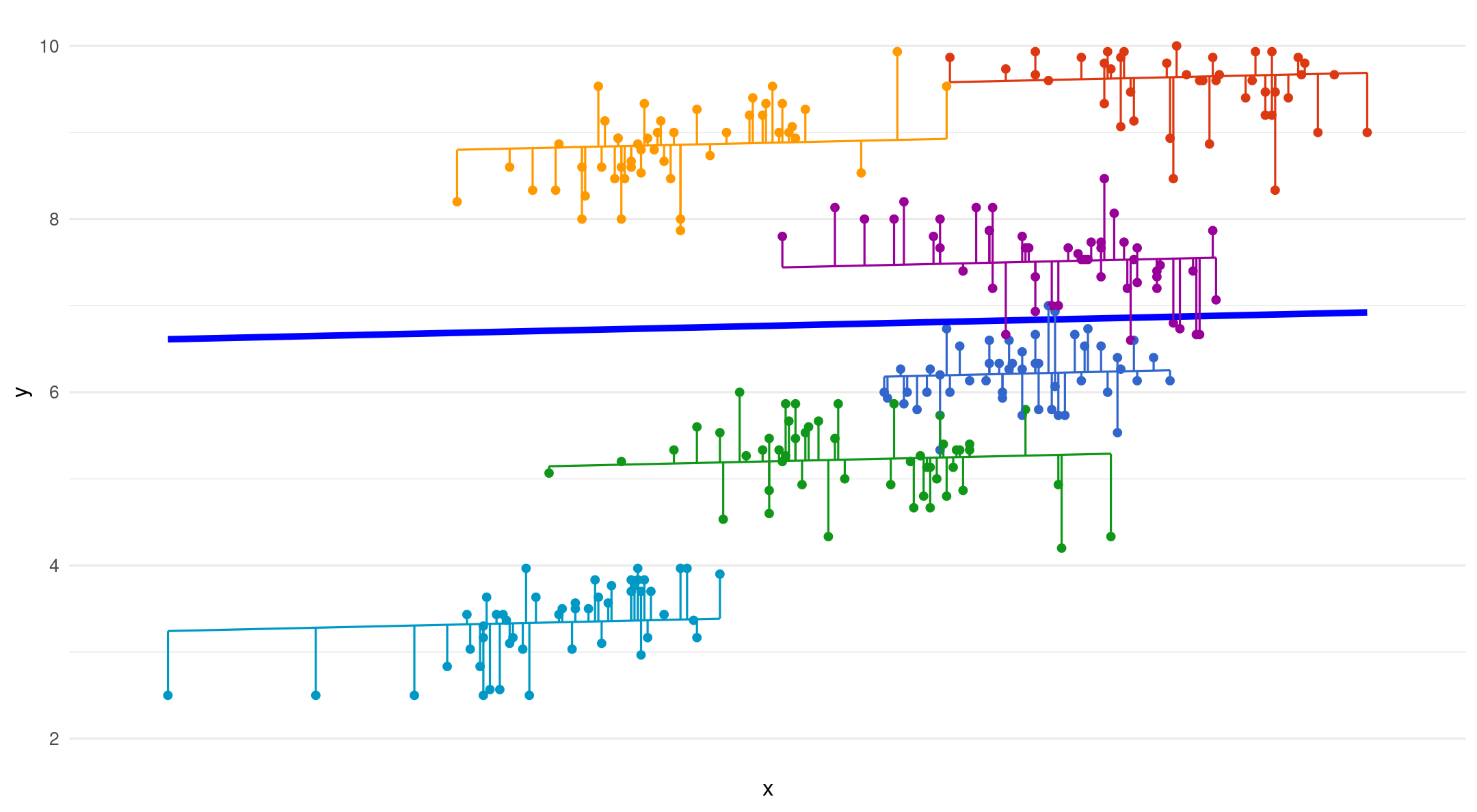
Random intercepts - fixed slope
- Varying starting point (intercept), same slope for each group
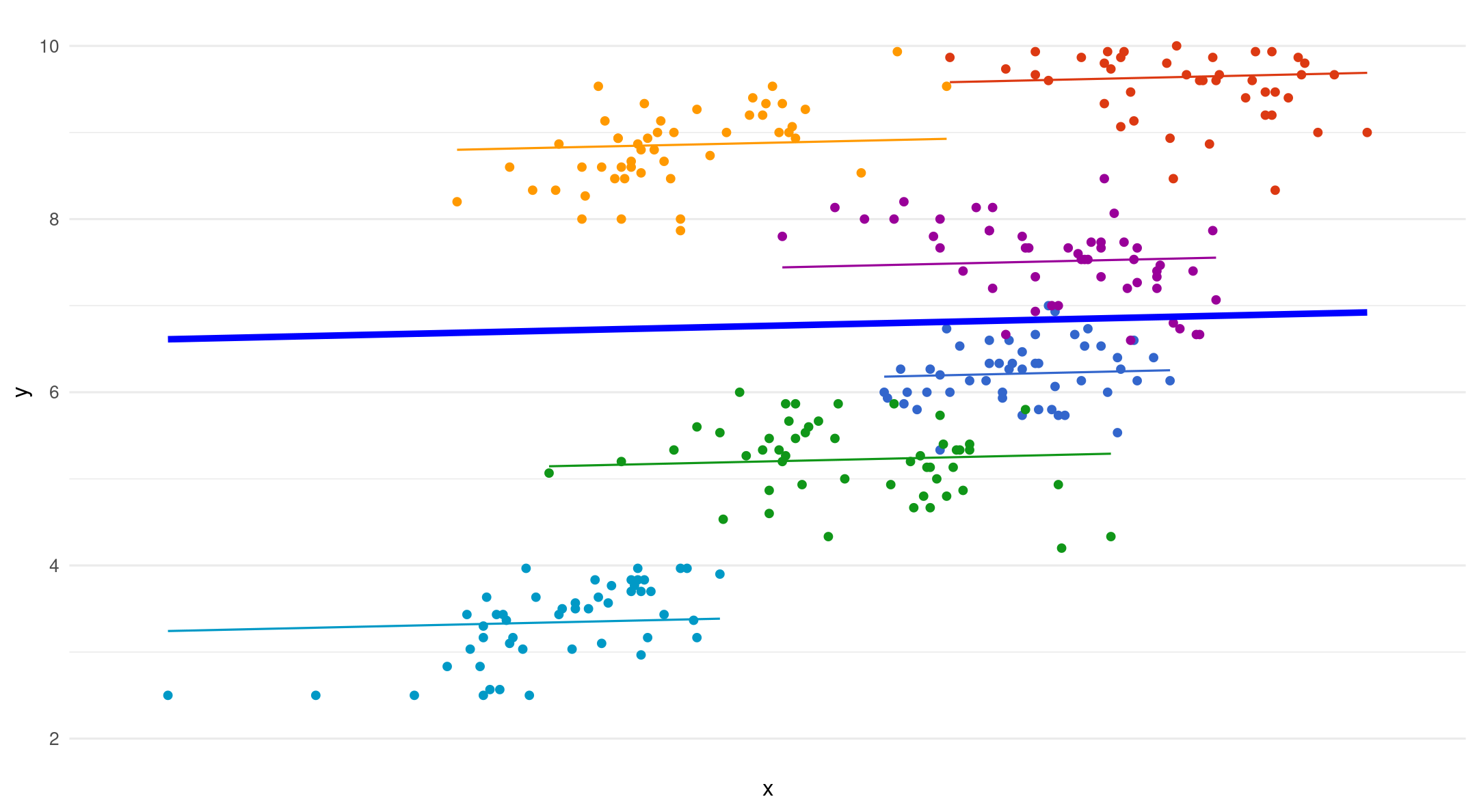
Random Intercepts - Random slopes
- Varying starting point (intercept), varying slope for each group
\[ y_{ij} = (\color{blue}{b_{0j_{\text{(intercept)}}}} + \color{red}{U_{0j_{\text{(random intercept)}}}}) + (\color{blue}{b_{1_{\text{(slope)}}} x_{ij}} + \color{red}{U_{1j_{\text{(random slope)}}}}) + \color{red}{e_{ij_{\text{(error)}}}} \]
Important
- Only put a random slope if it changes within cluster/group
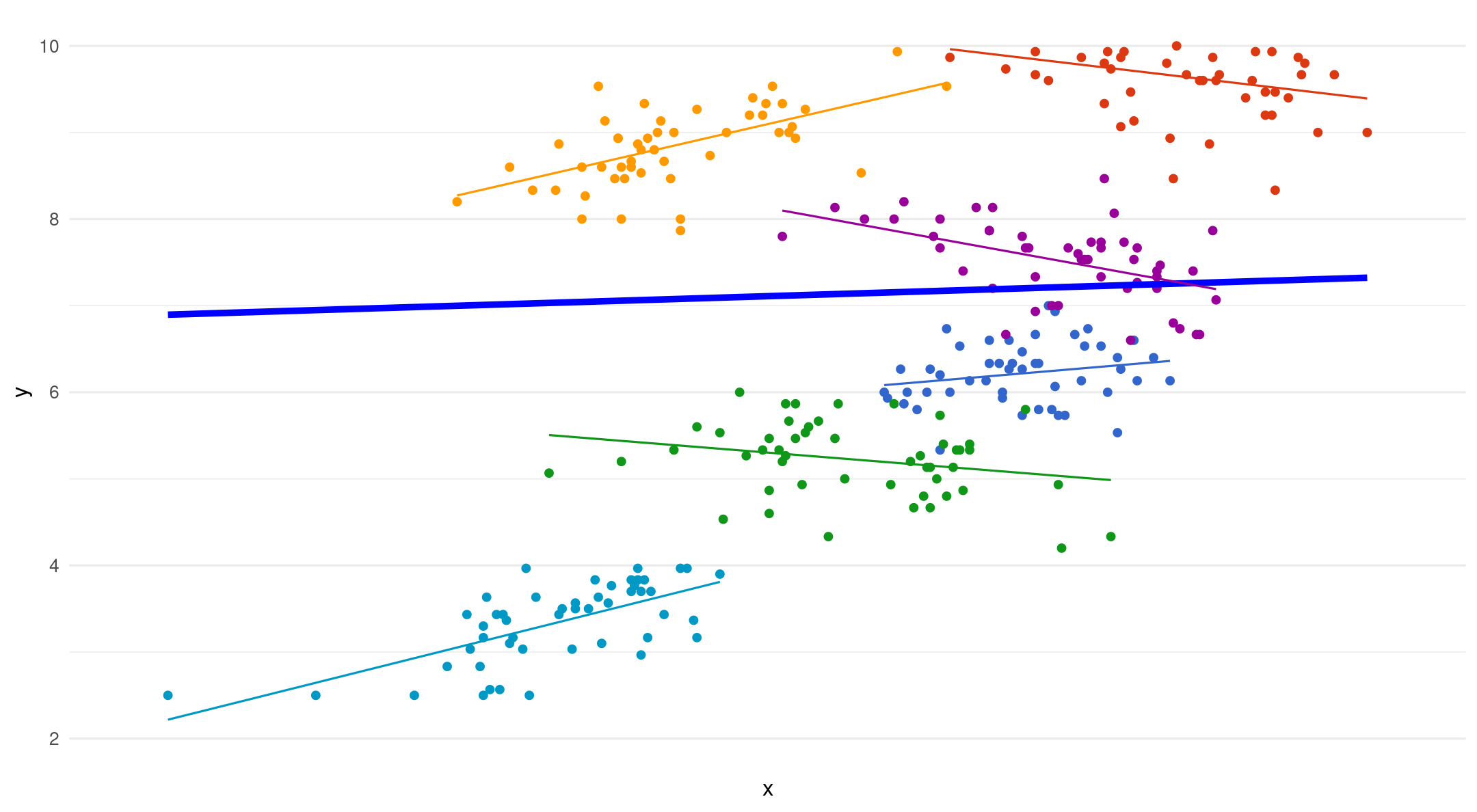
Random slopes
- The dotted lines are fixed slopes. The arrows show the added error term for each random slope
\[ U_{1j} = b_{1j} - b_1 \]
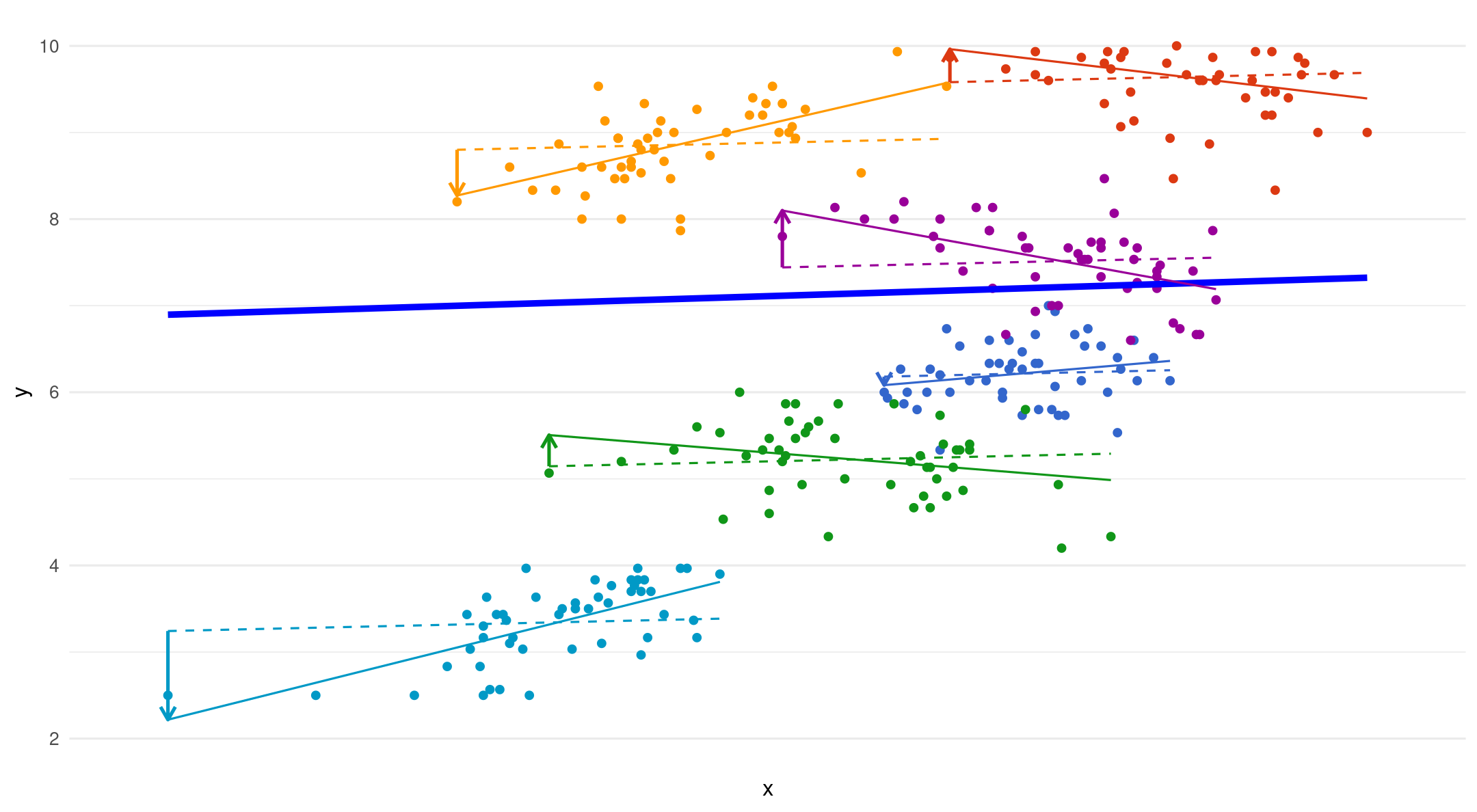
All together
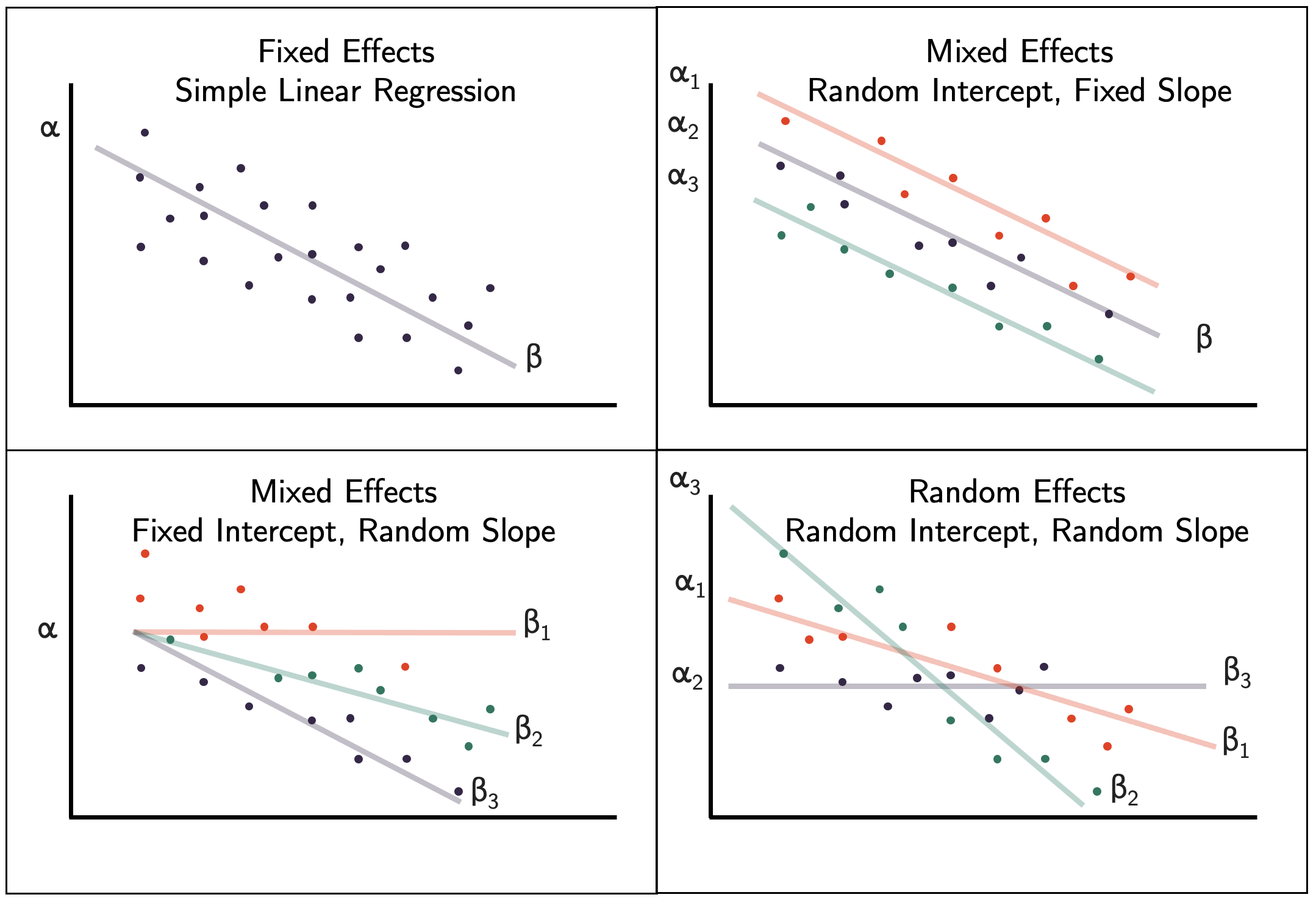
Syntax cheat sheet
