Missing Data in R
Princeton University
2024-02-11
Today
MCAR, MAR, NMAR
Screening data for missingness
Diagnosing missing data mechanisms in R
Missing data methods in R
- Listwise deletion
- Casewise deletion
- Nonconditional and conditional imputation
- Multiple imputation
- Maximum likelihood
Reporting

Missing data mechanisms
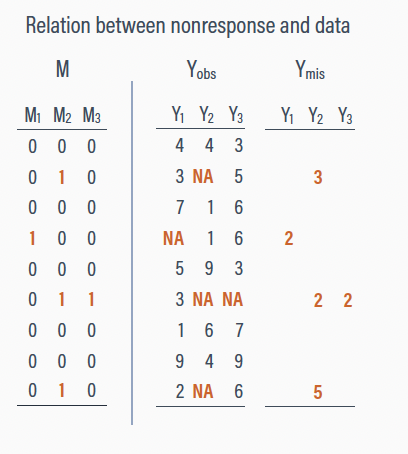
Most of modern missing data theory comes from the work of statistician Donald B. Rubin
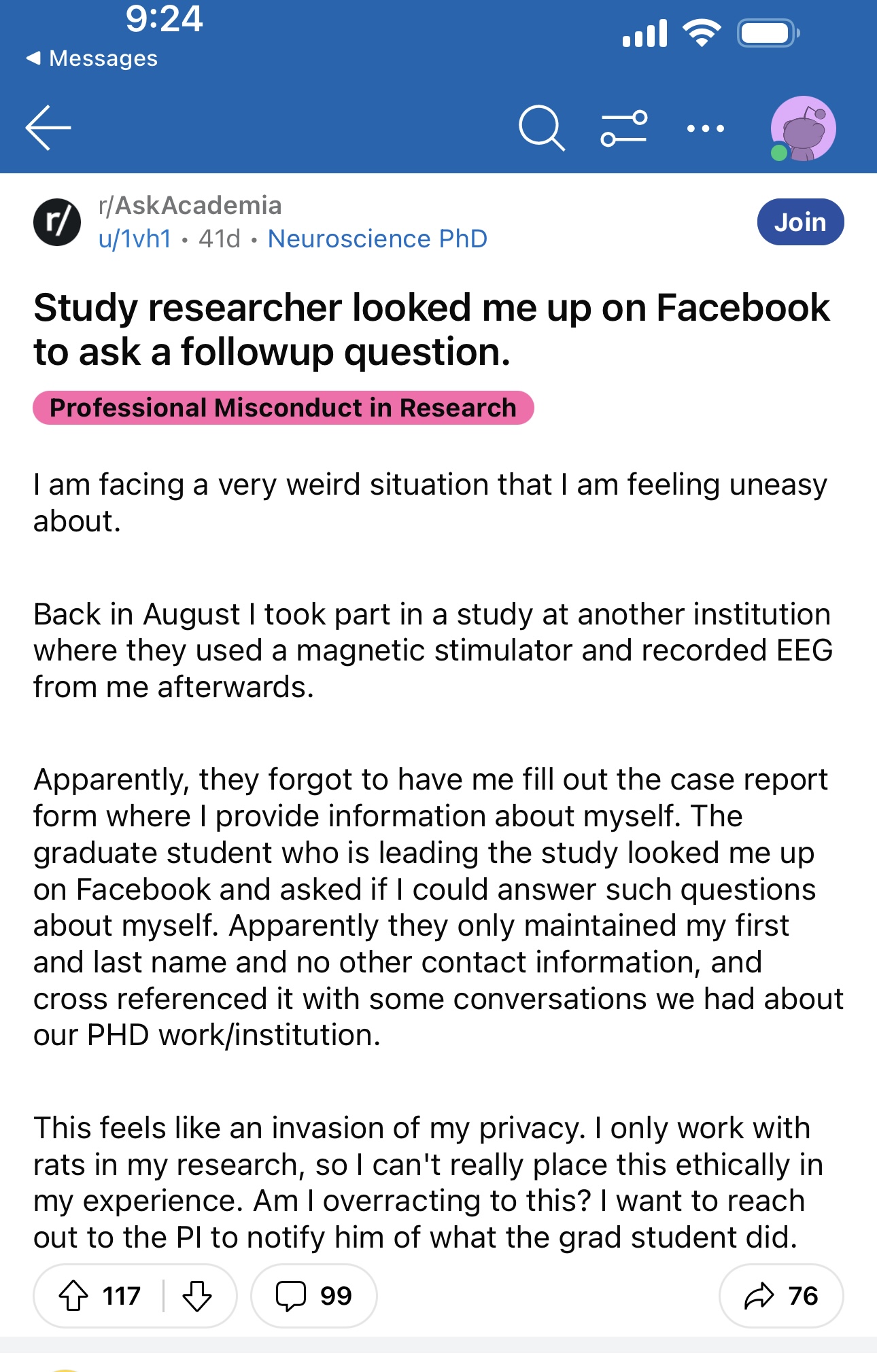
Rubin proposed we can divide an entire data set \(Y\) into two components:
\(Y_\text{obs}\) the observed values in the data set
\(Y_\text{mis}\) the missing values in the data set
\[Y = Y_\text{obs} + Y_\text{mis}\]
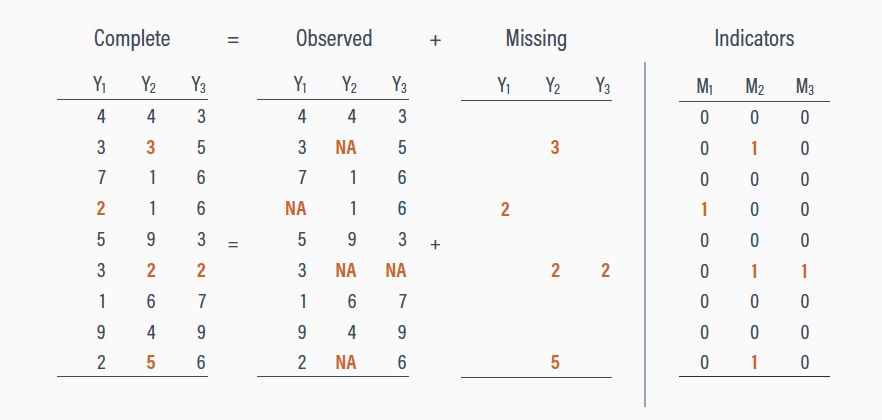
Missing completely at random (MCAR)
The probability of missingness is unrelated to the data
MCAR is purely random missingness
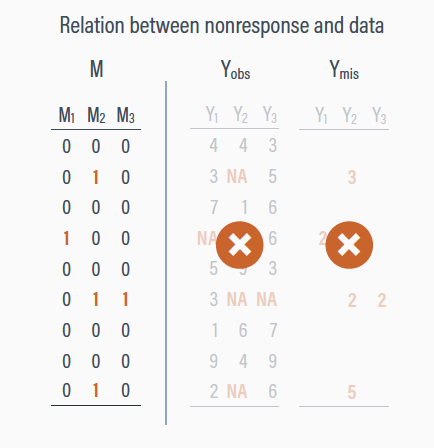
Conditionally missing at random (CMAR)
Systematic missingness related to the observed scores
The probability of missing values is unrelated to the unseen (latent) data
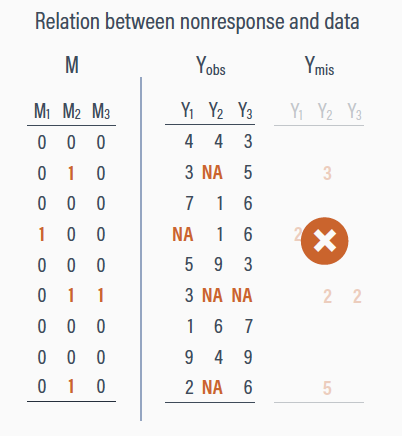
Not missing at random (NMAR)
Systematic missingness
The probability of missing values is related to the unseen (latent) data
EDA

Missing patterns
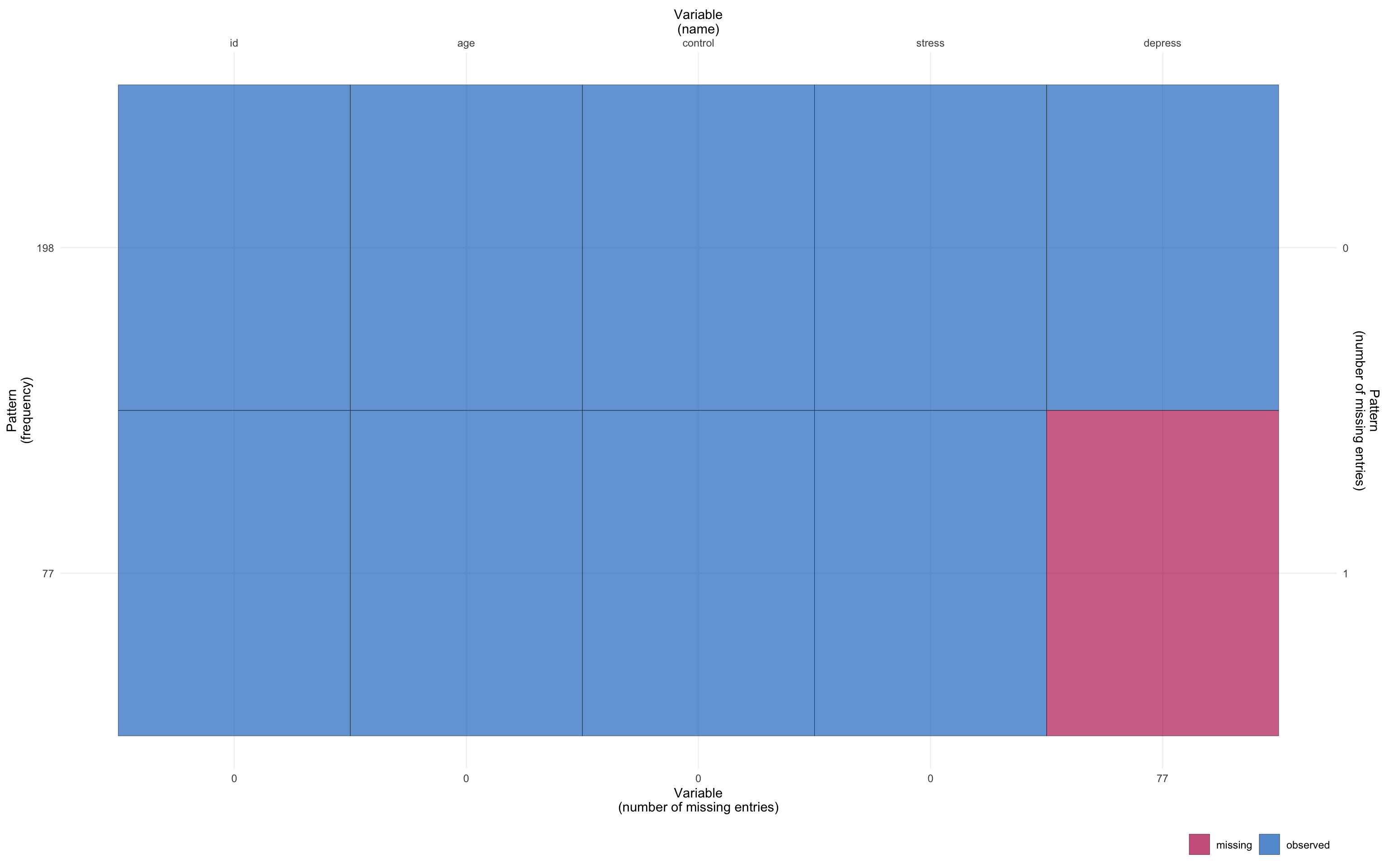
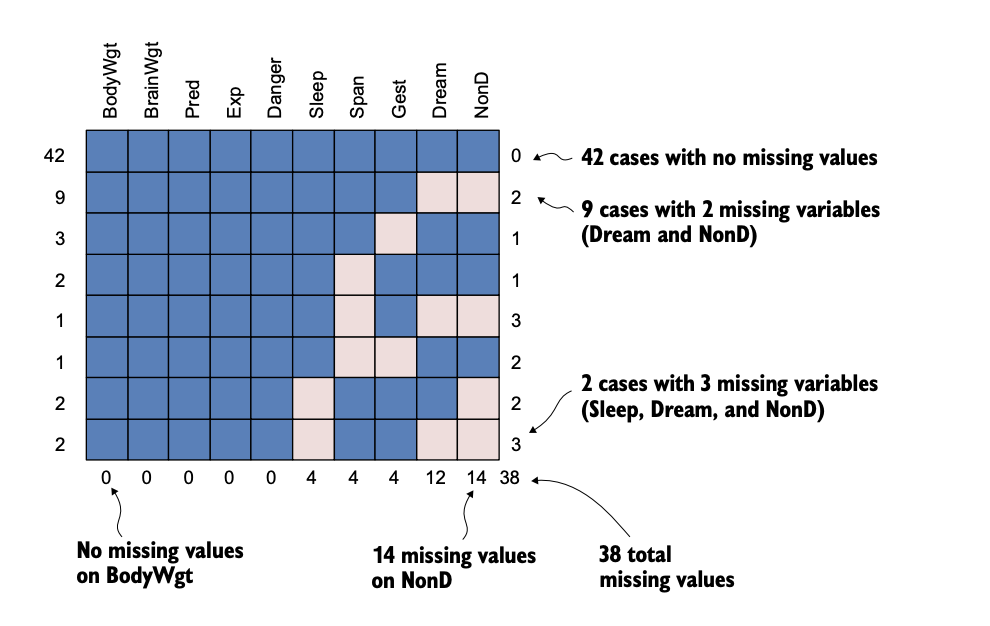
Missing patterns
Univariate: one variable with missing data
Monotone: patterns in the data can be arranged
- Associated with a longitudinal studies where members drop out and never return
Non-monotone: missingness of one variable does not affect the missingness of any other variables
- Look for islands of missingness
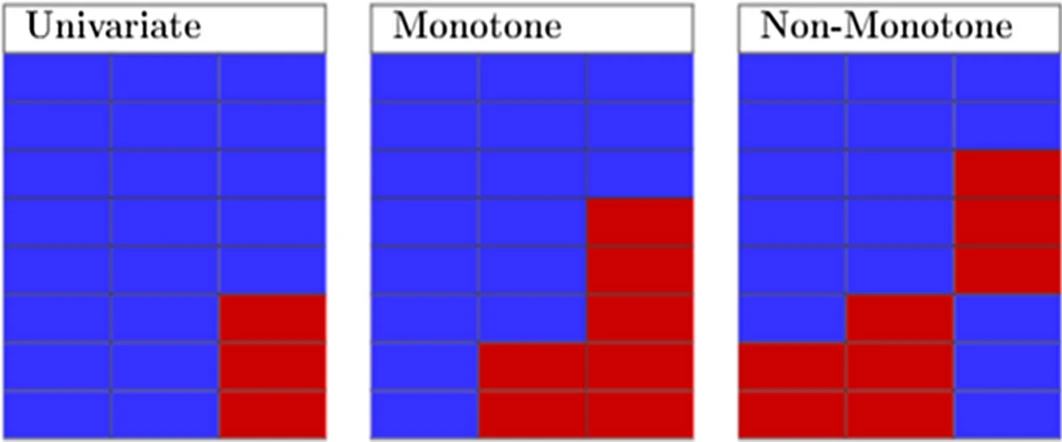
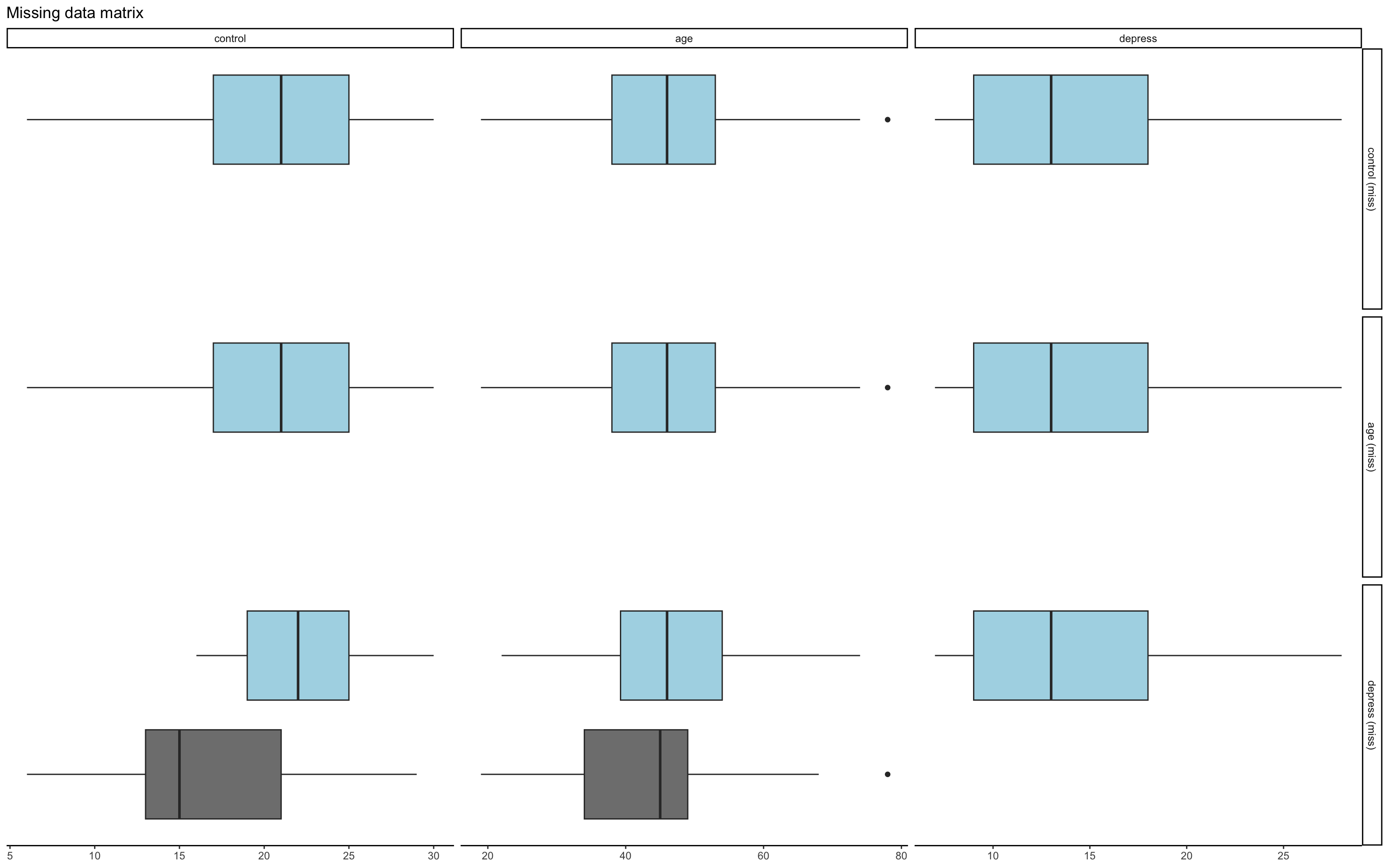
Is it MCAR or MAR?

Is it MCAR or MAR?
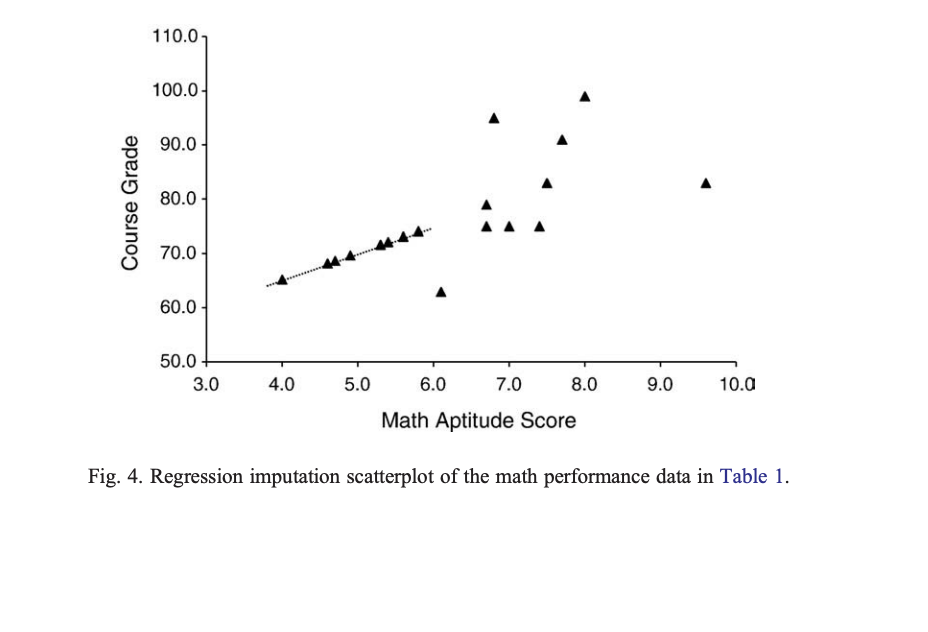
Conditional imputation (regression)
- Run a regression using the complete data to replace the missing value
All the other related variables in the data set are used to predict the values of the variable with missing data
Missing scores have the predicted values provided to replace them
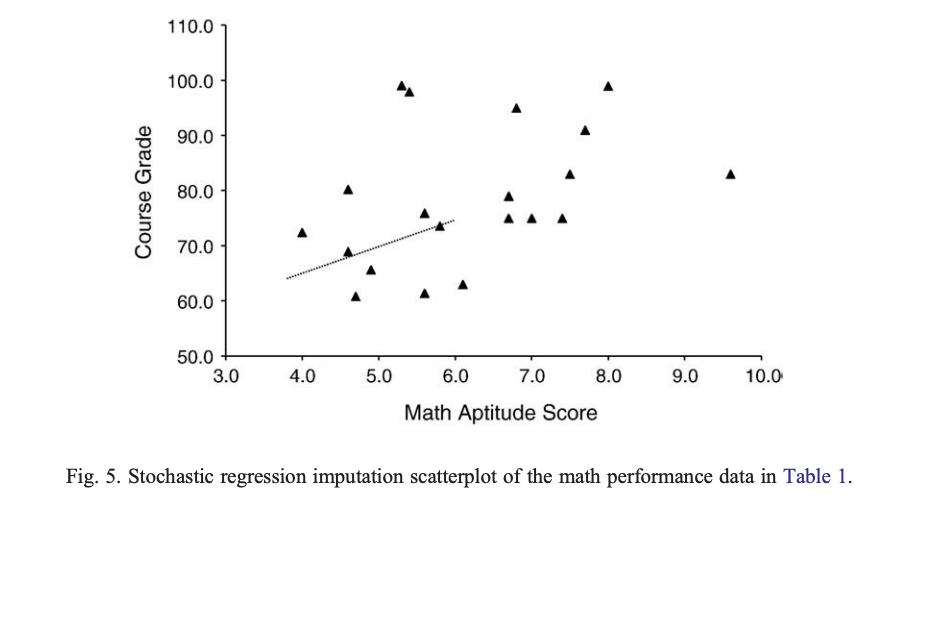
Stochastic Regression
- Regression imputation with added error variance to predicted values
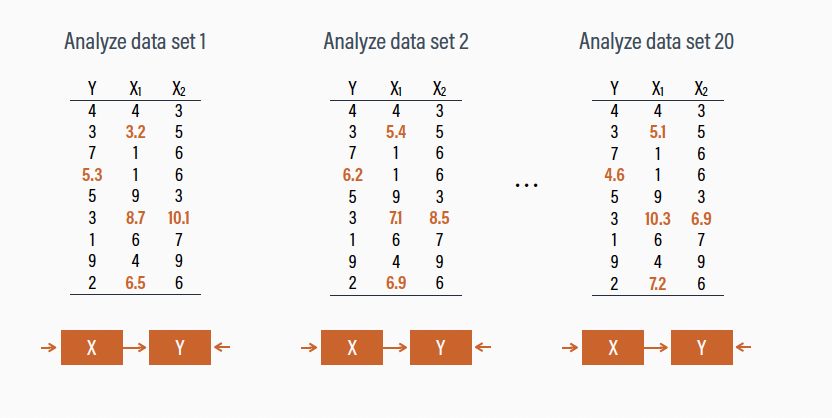
Multiple Imputation
Instead of using one value as a true value (which ignores uncertainty and variance), we use multiple values
Basically doing conditional imputation several times
- Several steps
- We make several multiply imputed data sets with the
mice()function
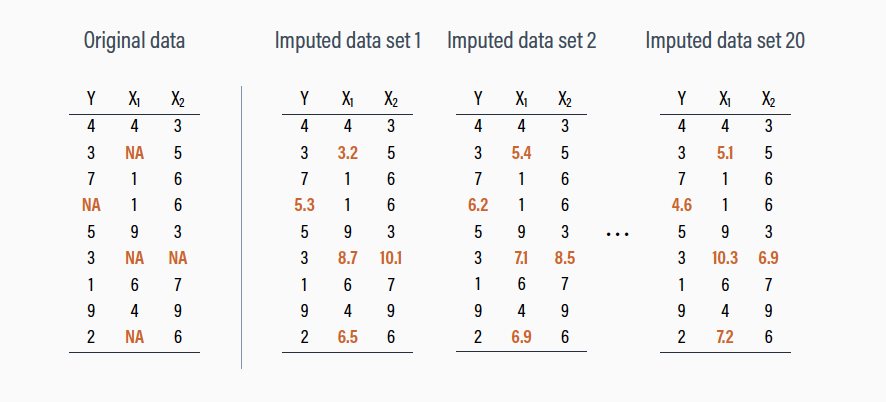
Multiple Imputation
- We fit our model of choice to each version of the data with the
with()function
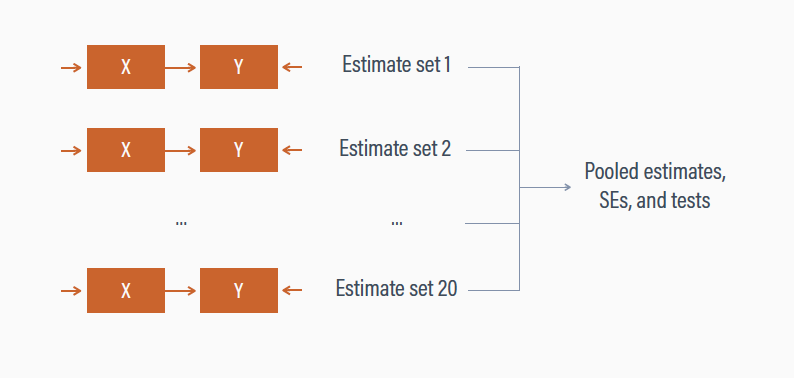
Multiple Imputation
- We then pool (i.e., combine) the results with the
pool()function
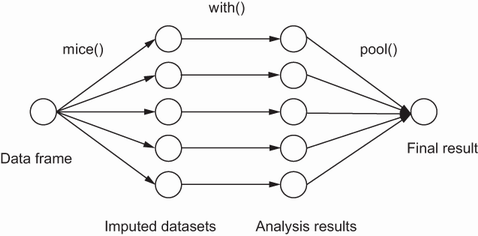
Multiple Imputation
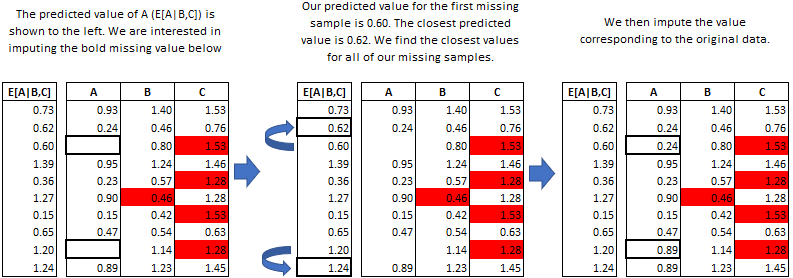
PMM
Predictive mean matching
- For each missing value, a regression model is fitted using the observed (complete) data, where the variable with missing data is the outcome and other variables are predictors
- For a record with a missing value, the fitted model predicts a mean based on the available data
- PMM identifies a set of “donors” from the observed data. These donors are the cases whose predicted means are closest to the predicted mean of the case with the missing value
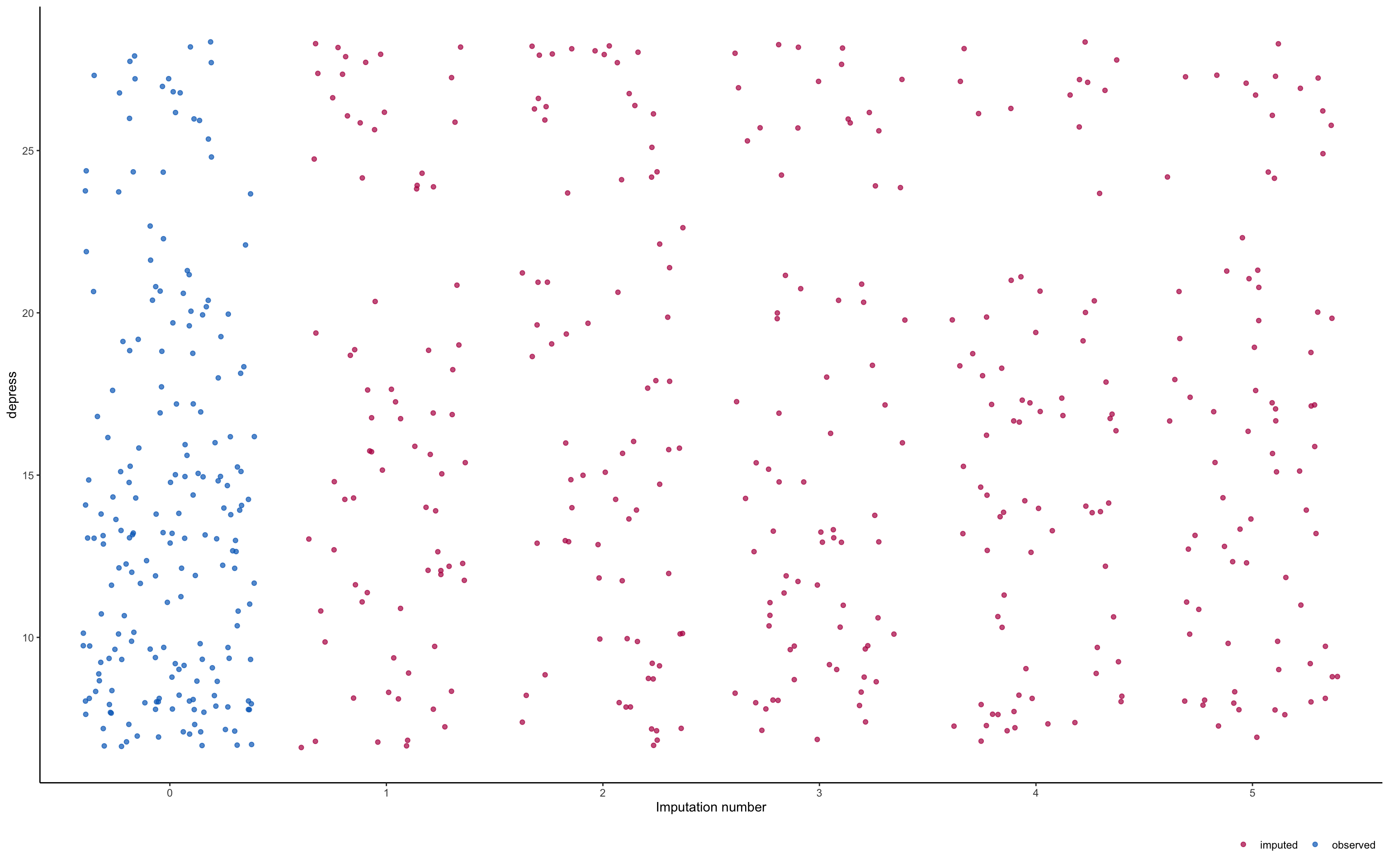
Plot Imputations
- Make sure they look similar to real data
ML
Implicit imputation
Each participant contributes their observed data
Data are not filled in, but the multivariate normal distribution acts like an imputation machine
The location of the observed data implies the probable position of the unseen data, and estimates are adjusted accordingly
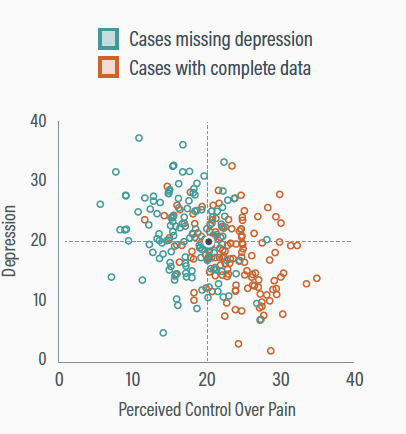
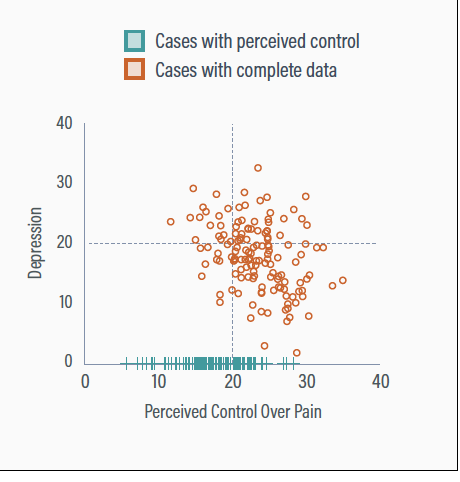
Chronic pain illustration
Participants with low perceived control are more likely to have missing depression scores (conditionally MAR)
The true means are both 20
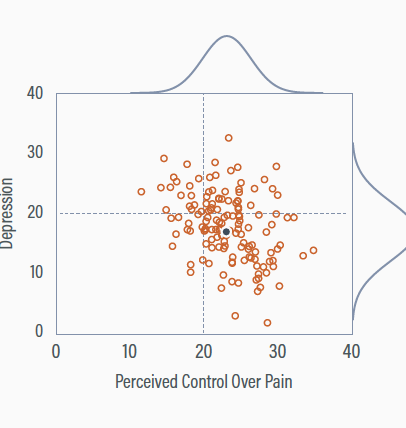
Deleting incomplete information
Deleting cases with missing depression scores gives a non-representative sample
The perceived control mean is too high (Mpc = 23.1), and the depression mean is too low (Mdep = 17.2)
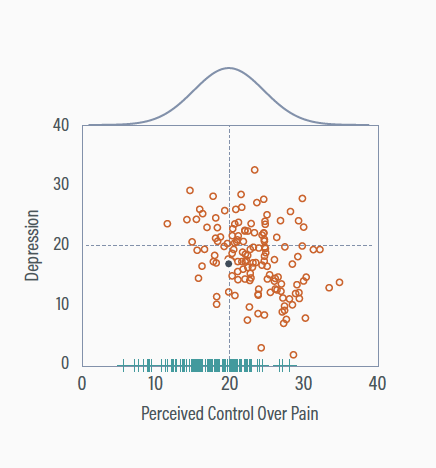
Partial data
Incorporating the partial data gives a complete set of perceived control scores
The partial data records primarily have low perceived control scores
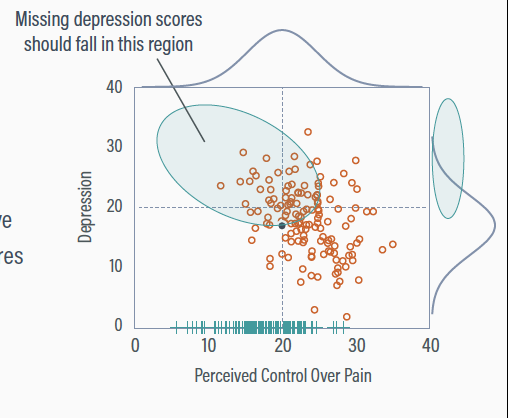
Adjusting perceived control
Adding low perceived control scores increases the variable’s variability
The perceived control mean receives a downward adjustment to accommodate the influx of low scores
Implicit Imputation
Maximum likelihood assumes multivariate normality
In a normal distribution with a negative correlation, low perceived control scores should pair with high depression
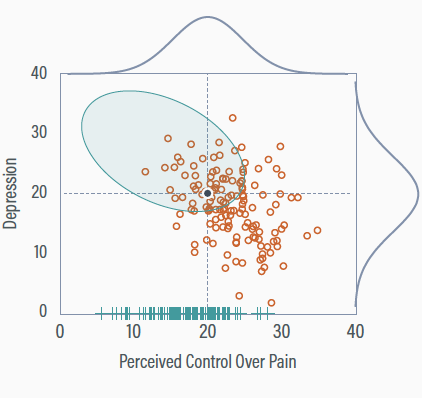
Adjusting Depression Distribution
Maximum likelihood intuits the presence of the elevated but unseen depression scores
The mean and variance of depression increase to accommodate observed perceived control scores at the low end
Distinguish between NMAR and MAR