Generalized Linear Madness: Binary Outcome Models/Logistic Regression
Princeton University
2024-02-19
Bye bye linear model

Linear models are not appropriate for this type of data
Makes impossible predictions (values not between 0, 1)
Non-normality of residuals
- \(\hat{p}\) or (1-\(\hat{p}\))
Heteroskedasticity
- Variance is influenced by \(\hat{p}\)
Bernoulli distribution
Distribution of a single, discrete binary outcome \[y\sim Bernoulli(p)\]
A Bernoulli distribution generates a 1 (“success”) with probability p
And a 0 (“failure”) with probability 1−p=q
- \(\mu\) = E(X)=p
- \(\sigma^2(X)=p(1-p)\)
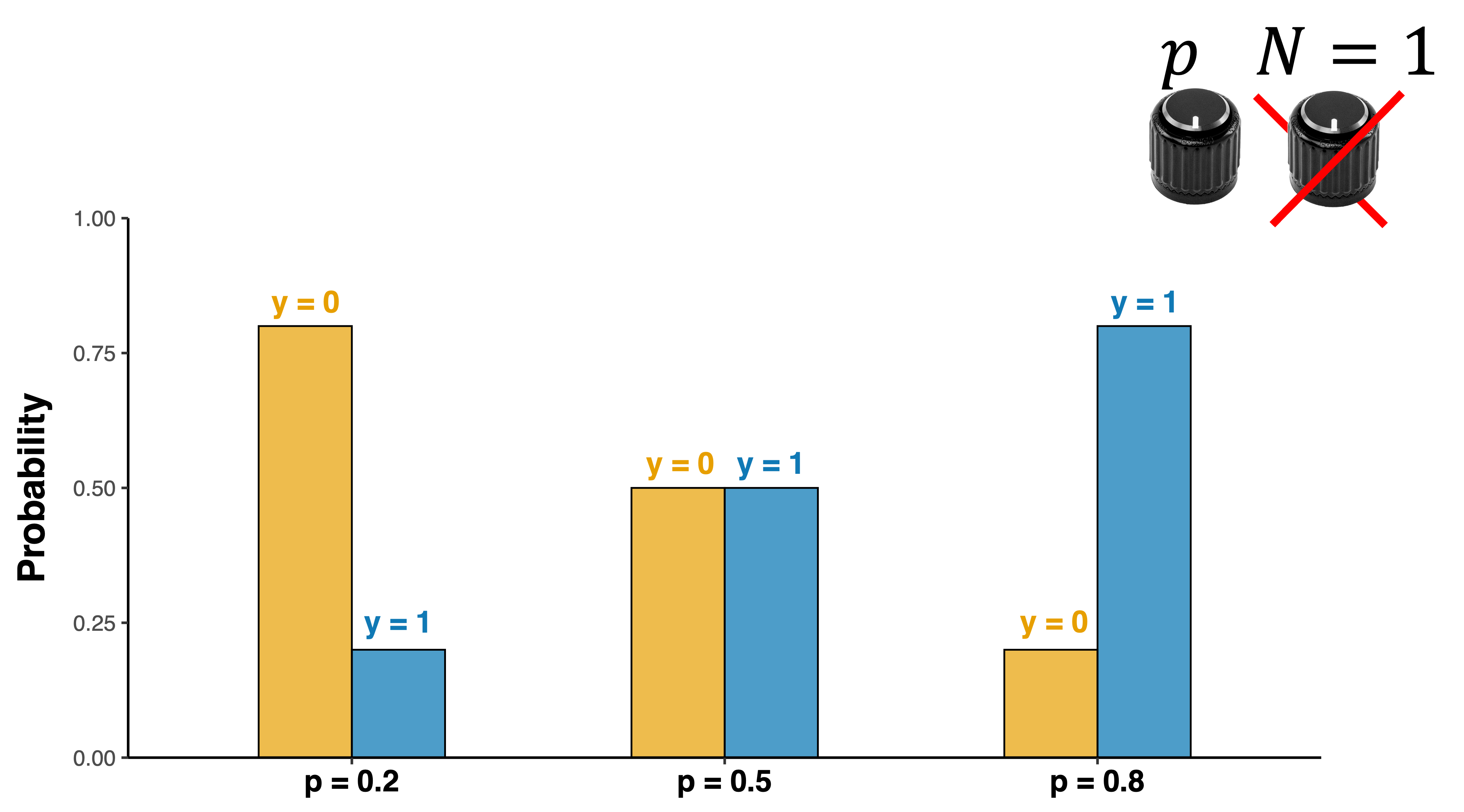
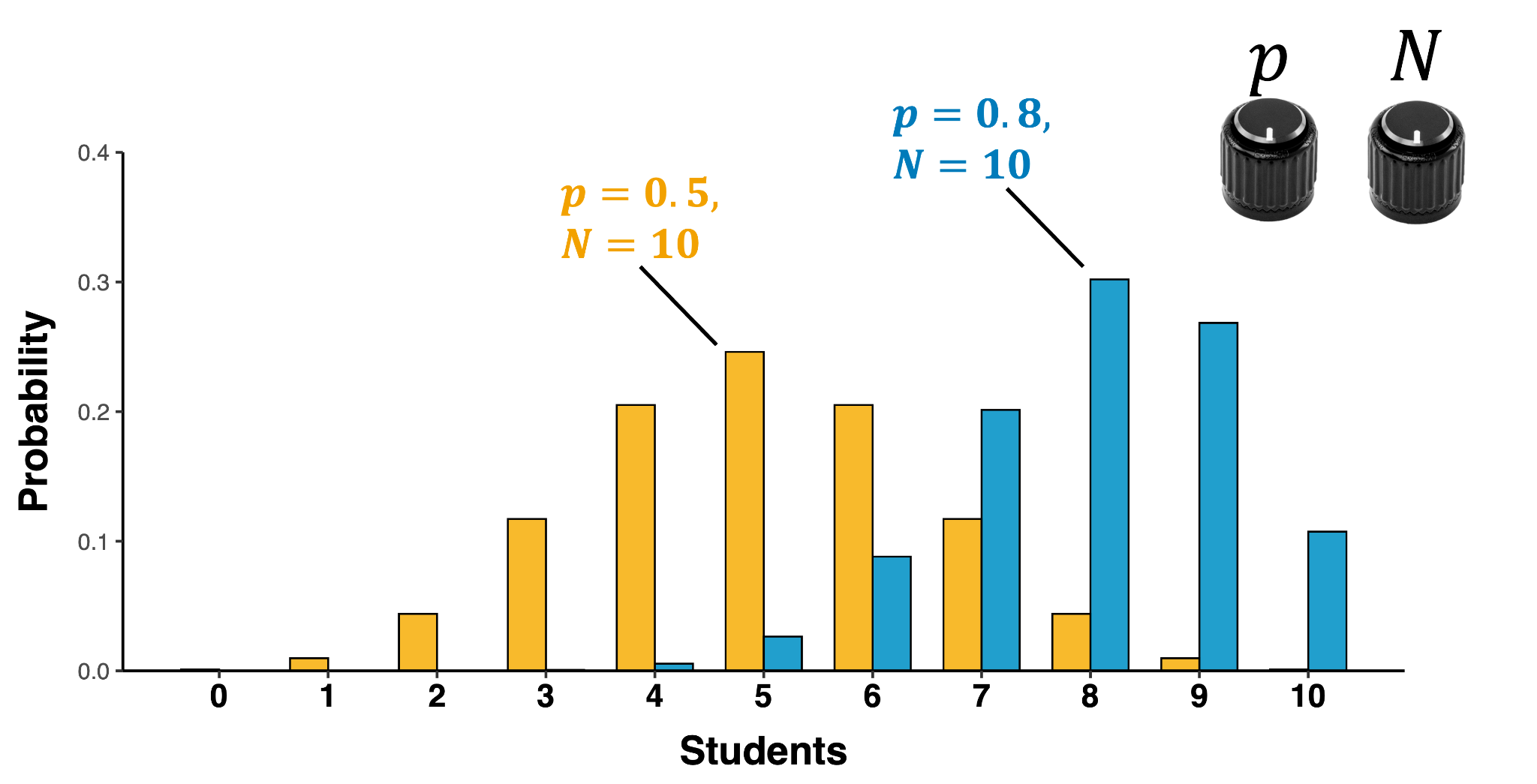
Binomial distribution
Distribution of discrete counts of independent outcomes over a certain set of trials
\[y\sim binomial(N,p)\]
- N = number of trials
- p = probability of “y = 1”
- \(\mu\) = E(X)=np$
- \(\sigma^2(X)=np(1-p)\)
- \(\sigma(X)\)=\(\sqrt{np(1-p)}\)
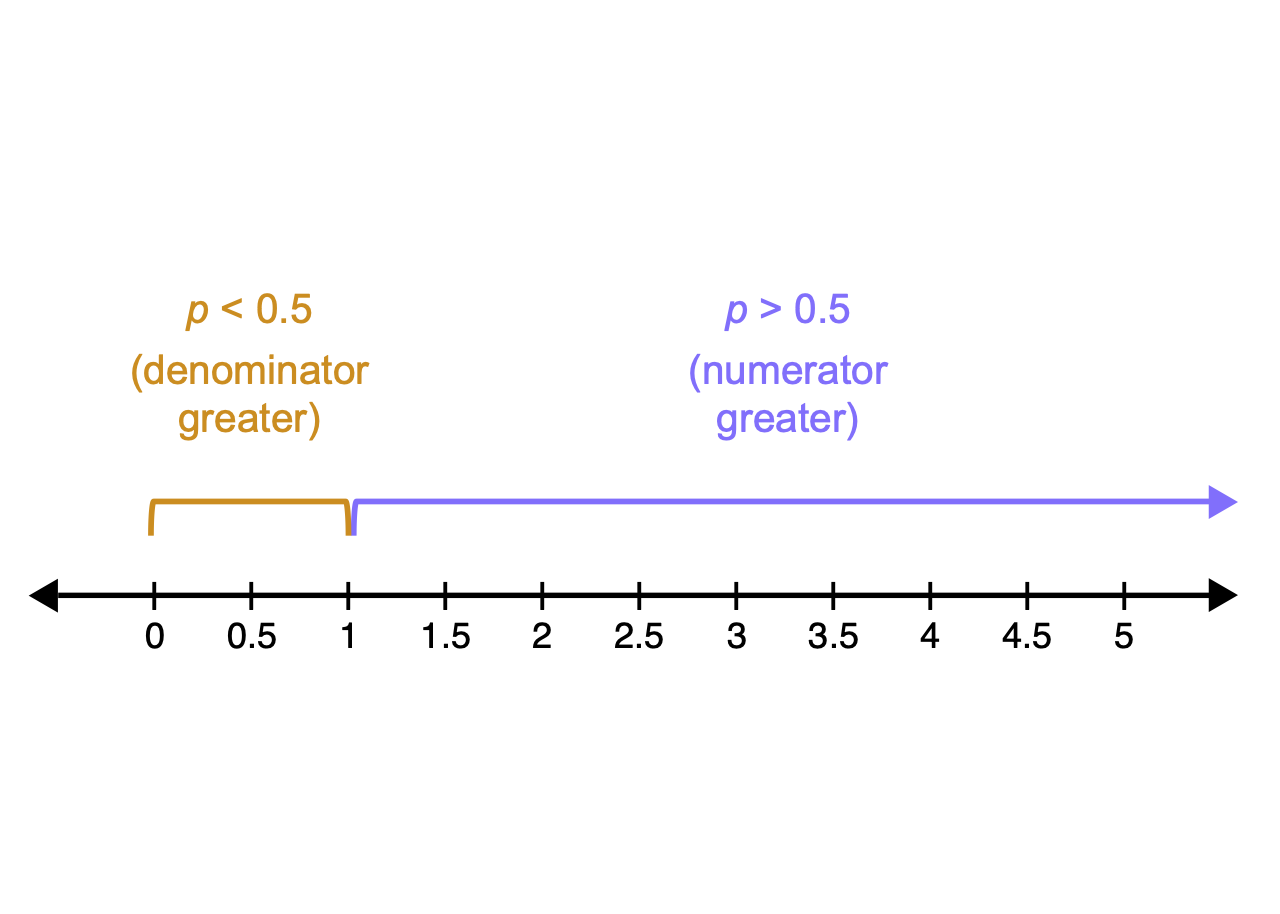
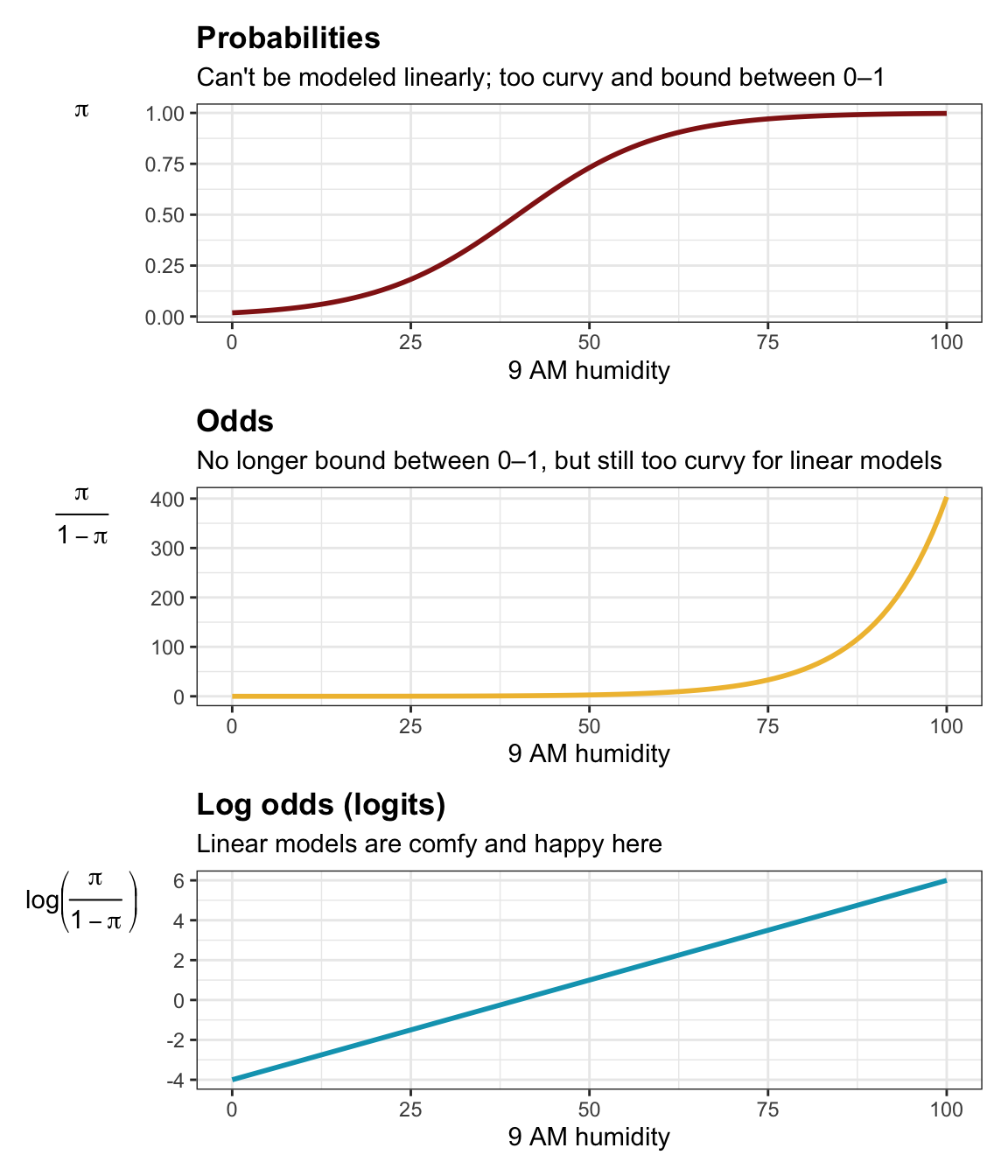
Logit Link
Step 2
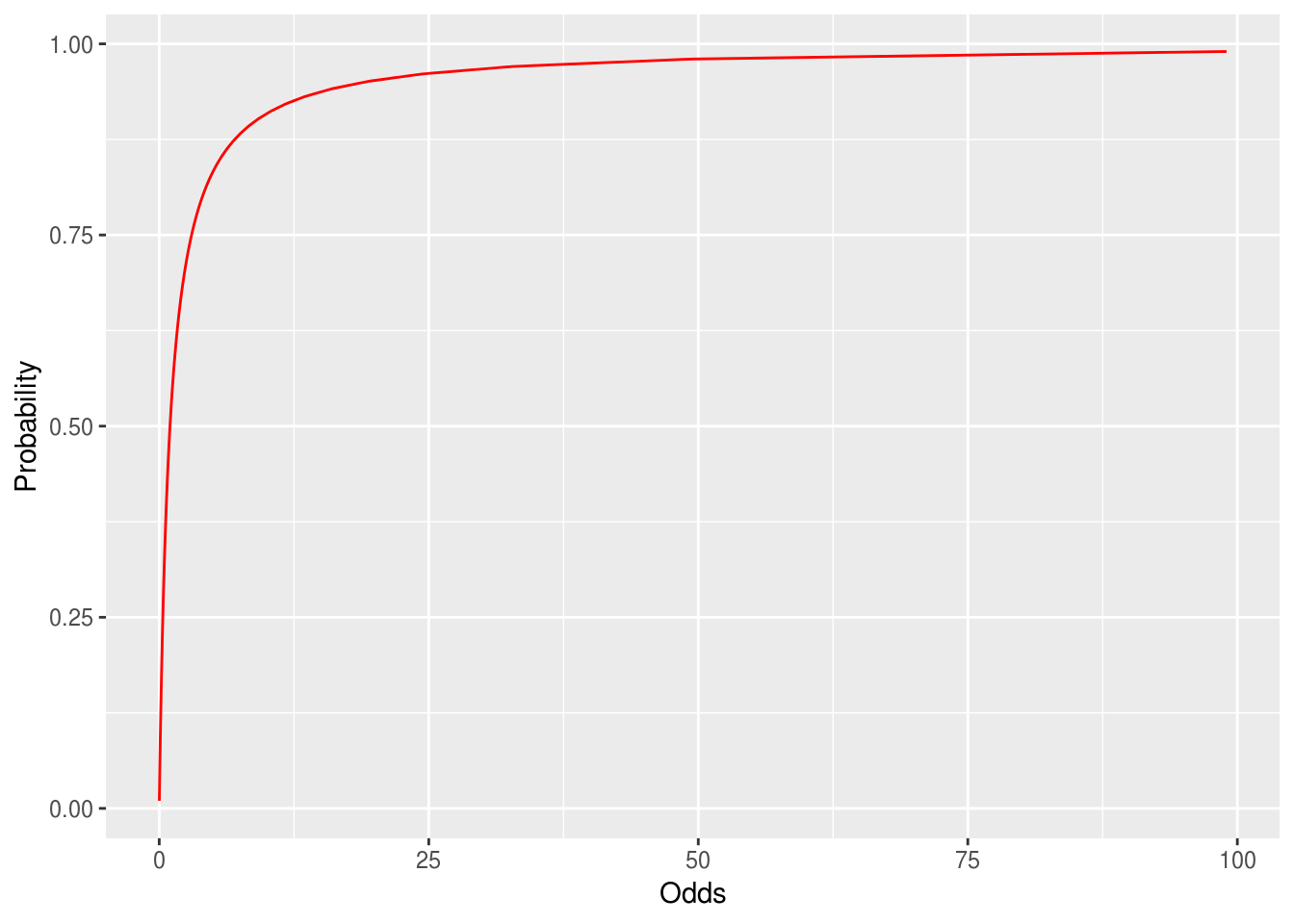
When we convert a probability to odds, odds always > 0
Asymmetric
Curvy
- Problematic for linear model
Solution: take log of the odds
\[logit = log(\frac{p}{1-p})\]
Logit link
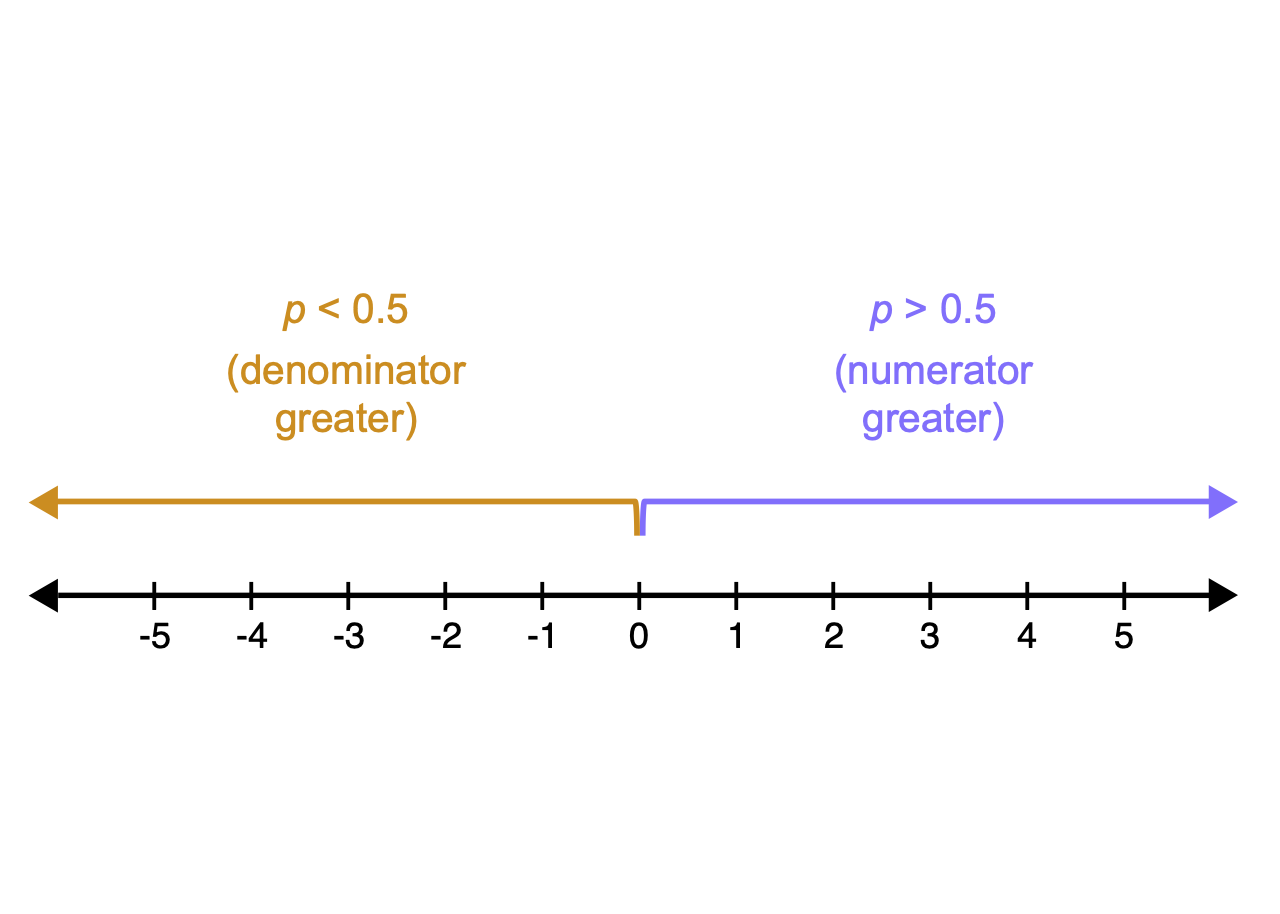
This log odds conversion has a nice property
It converts odds of less than one to negative numbers, because the log of a number between 0 and 1 is always negative
Our data is now linear!
and symmetric
However…
- We need a function that scrunches the output of the linear predictor into a range appropriate for this parameter
Squiggles
We need a function that scrunches the output of the linear predictor into a range appropriate for this parameter
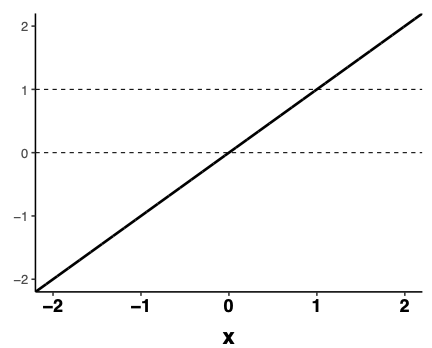
A squiggle (logistic or Sigmoid curve) to the rescue!
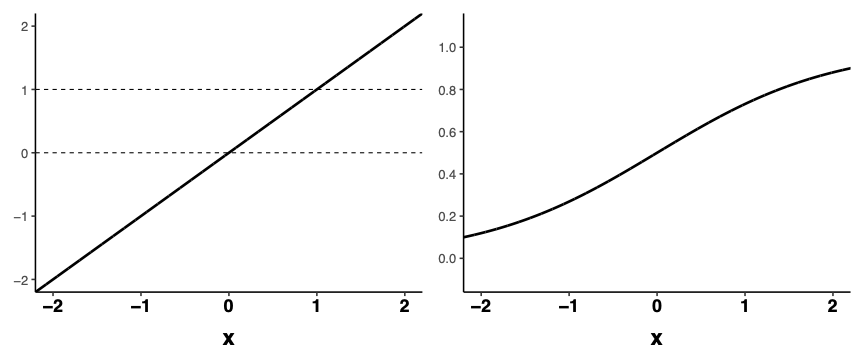
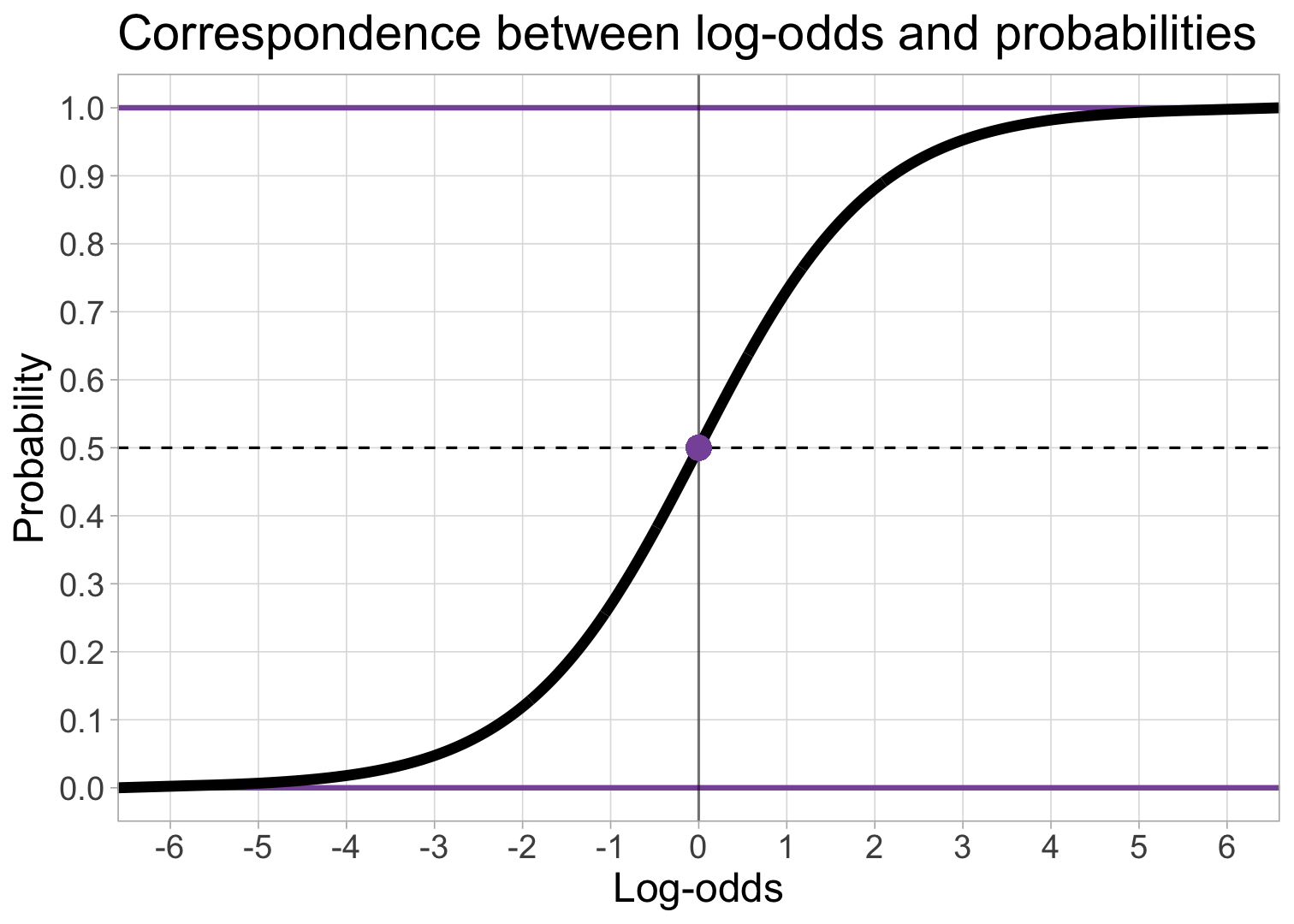
Logistic transform
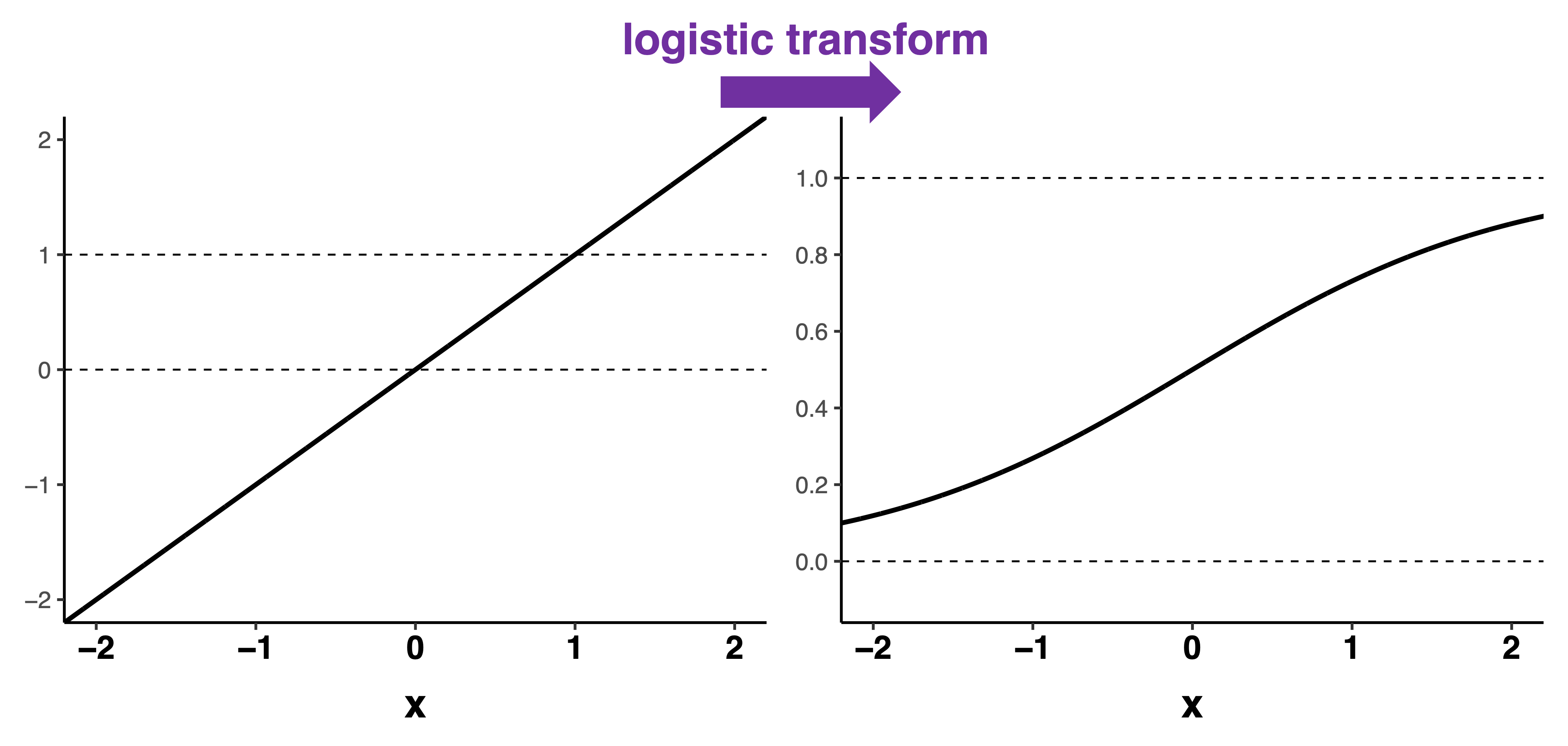
\[p(logit)=\frac{e^{logit}}{1+e^{{logit}}}\]
Slope and intercept parameters
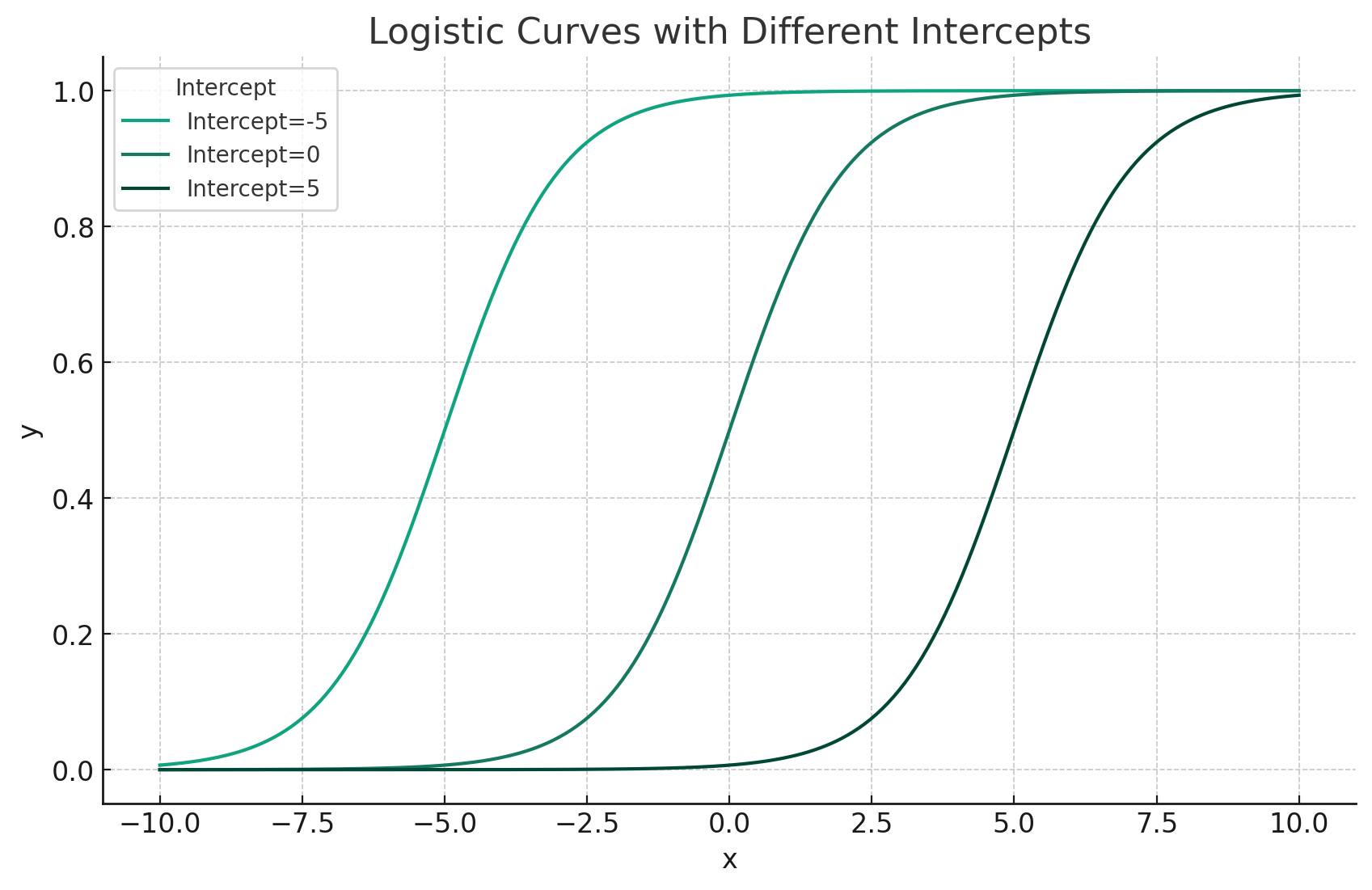
- Intercept moves curve left or right
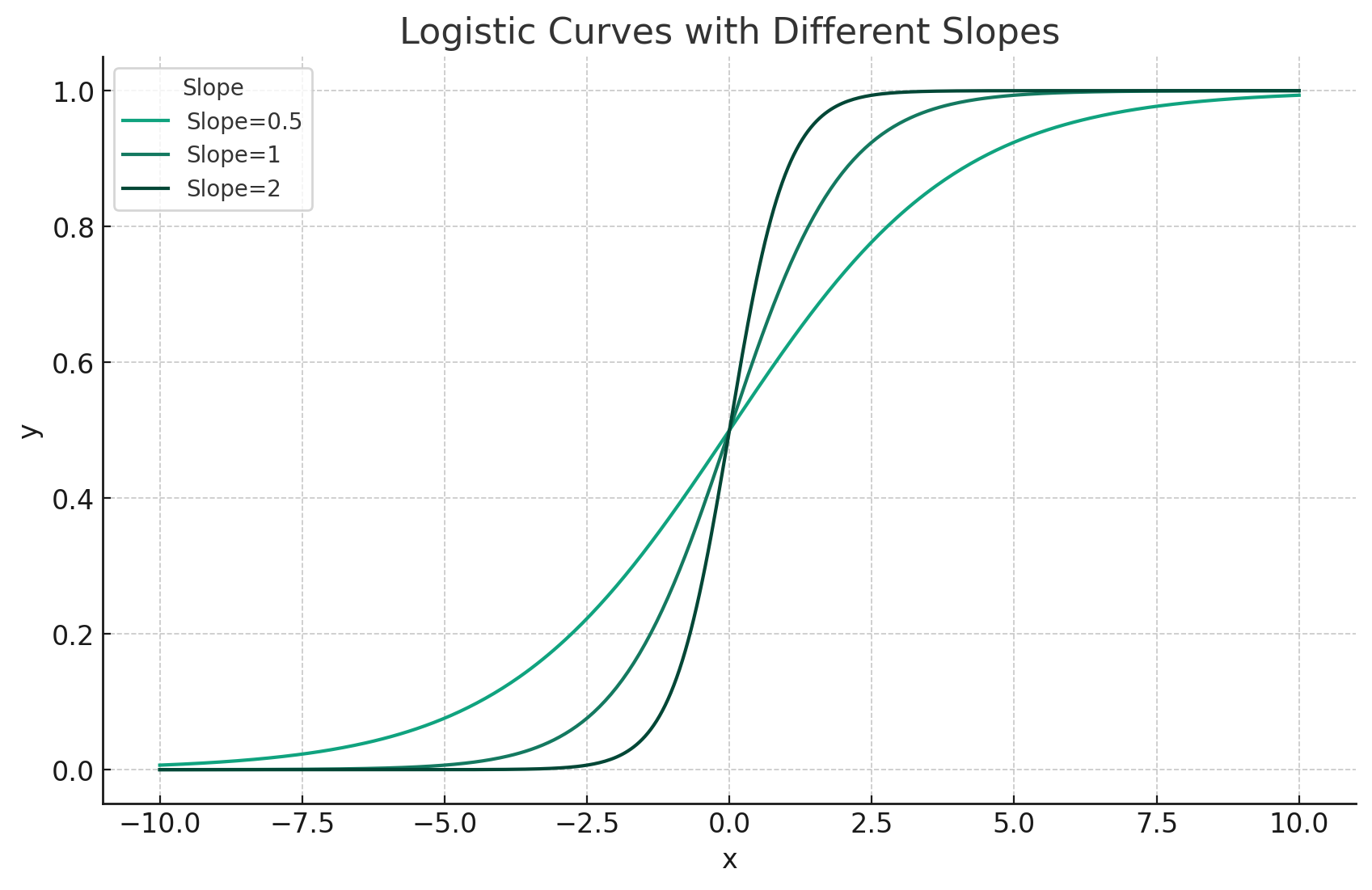
- Slope determines the steepness of the curve
All together
Andrew Heiss
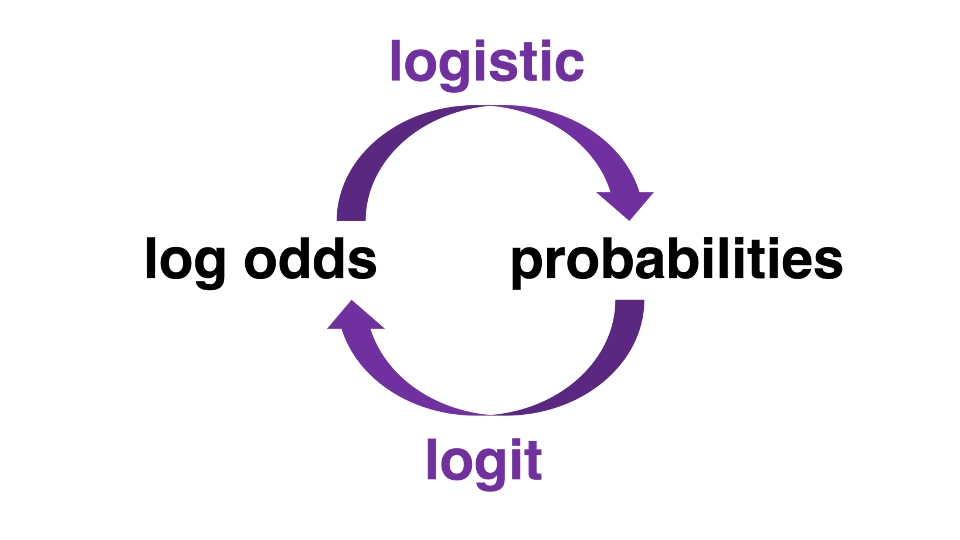
Probabilities, Odds, and Log Odds
Probabilities, Odds, and Log Odds
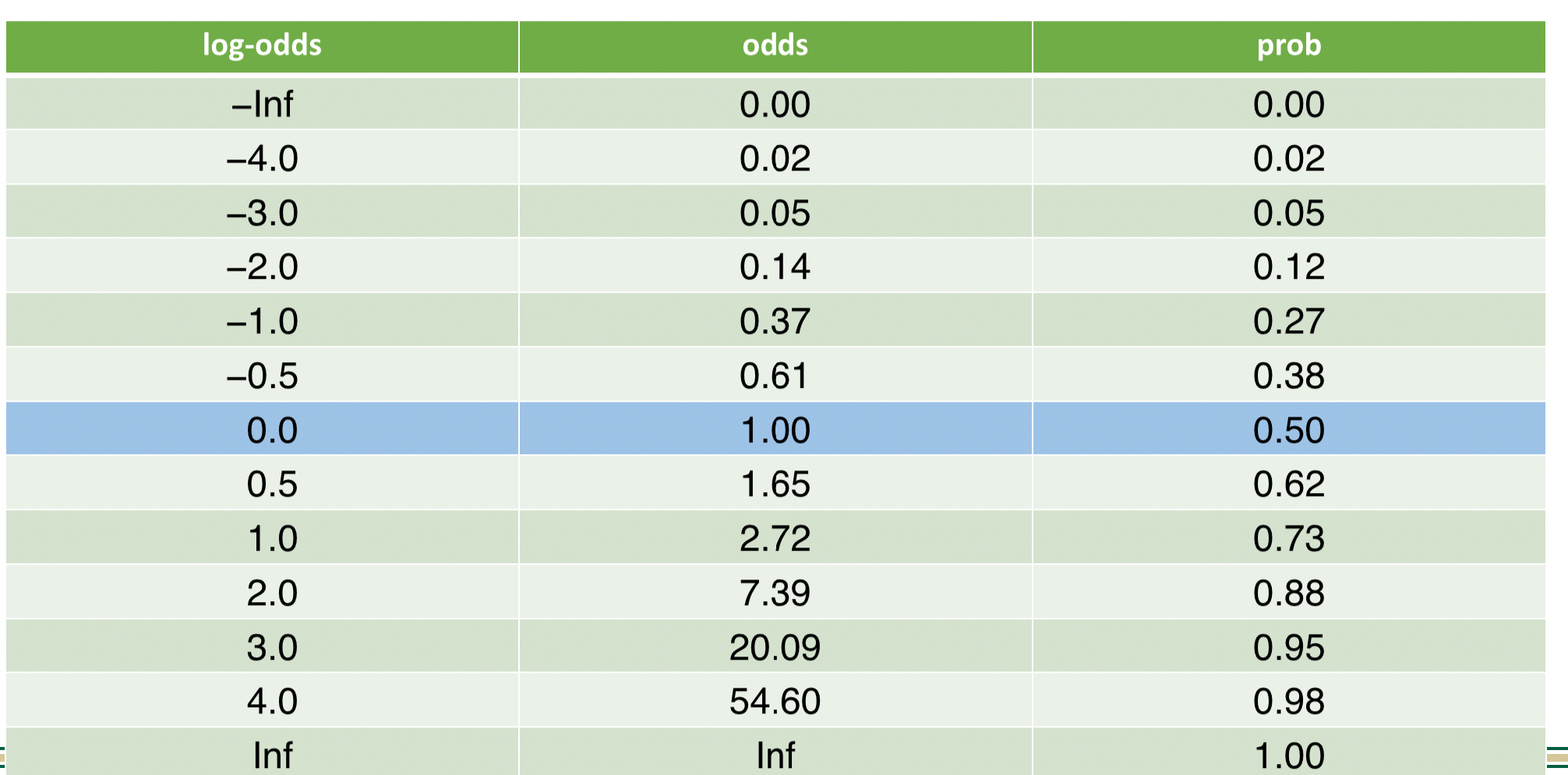
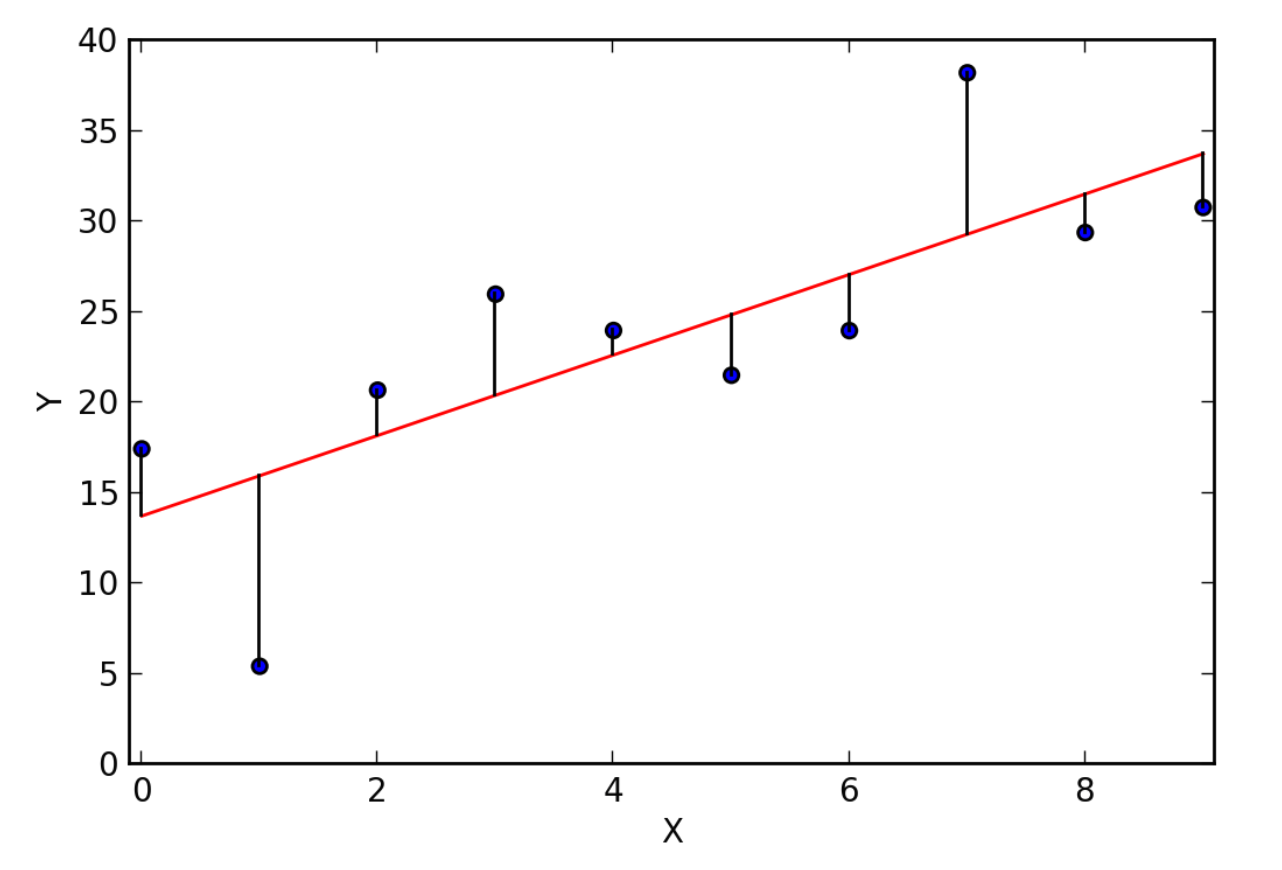
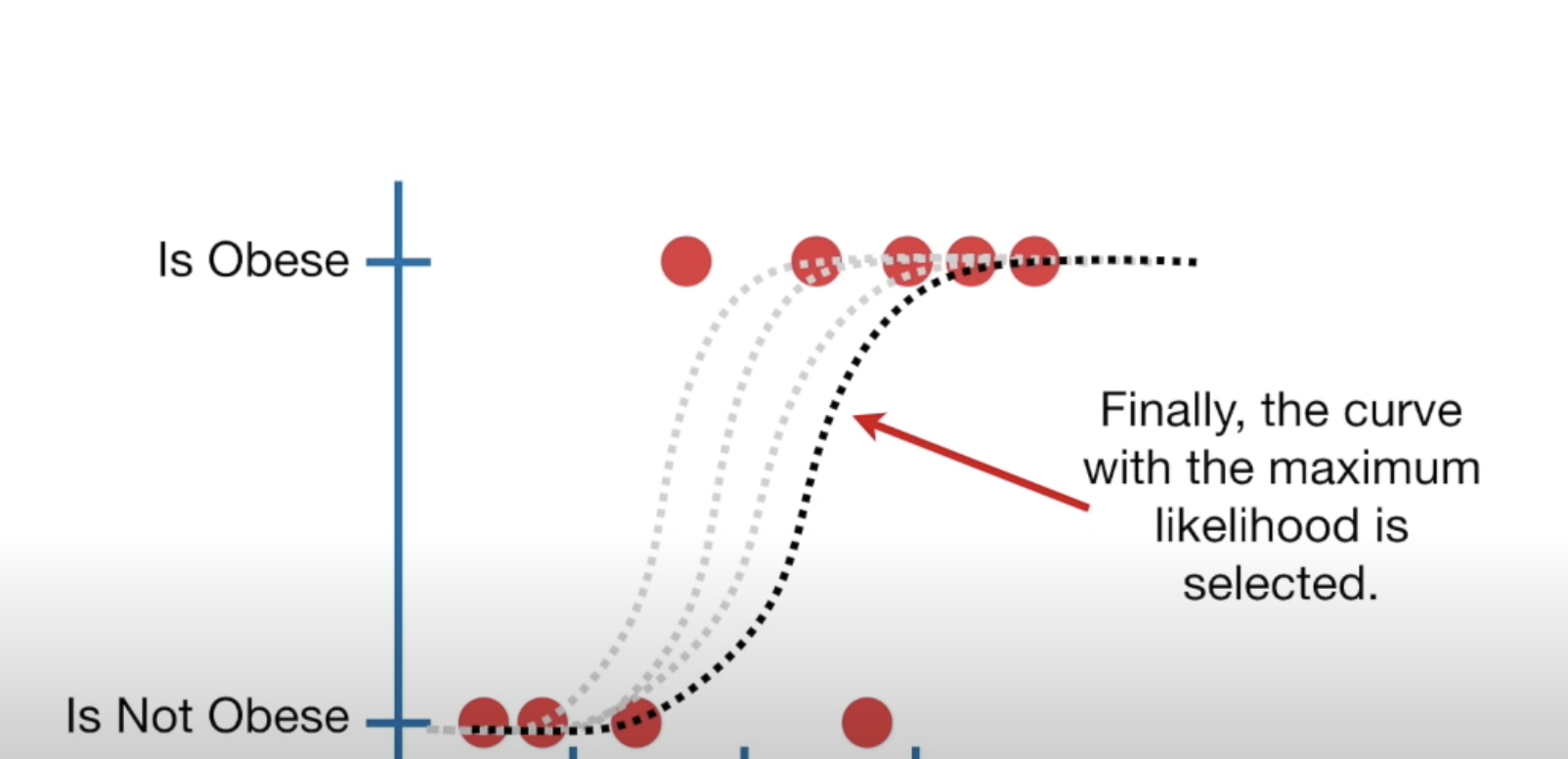
Best fitting squiggle
- In standard linear regression we use least squares to find the best fitting line
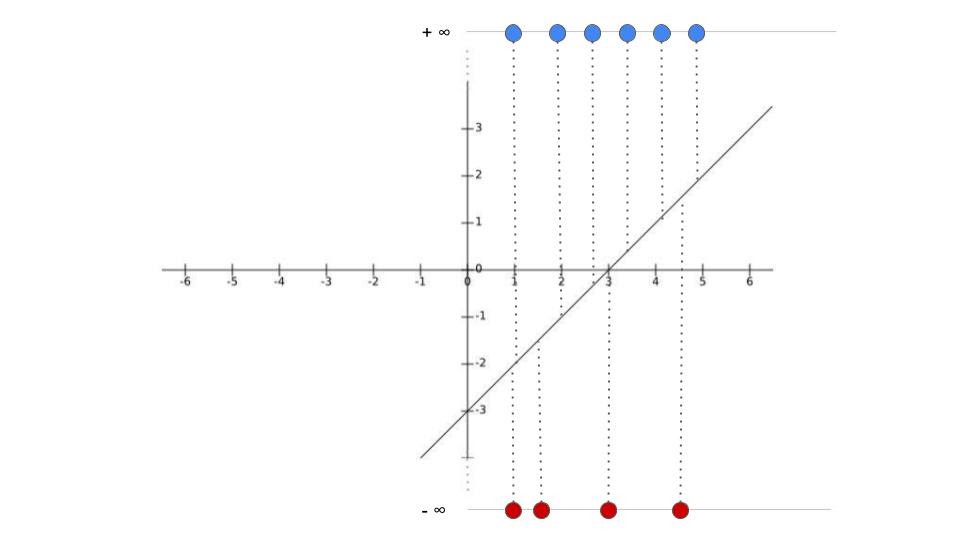
Maximum likelihood estimation
- We need find where points lie on line and get corresponding logits
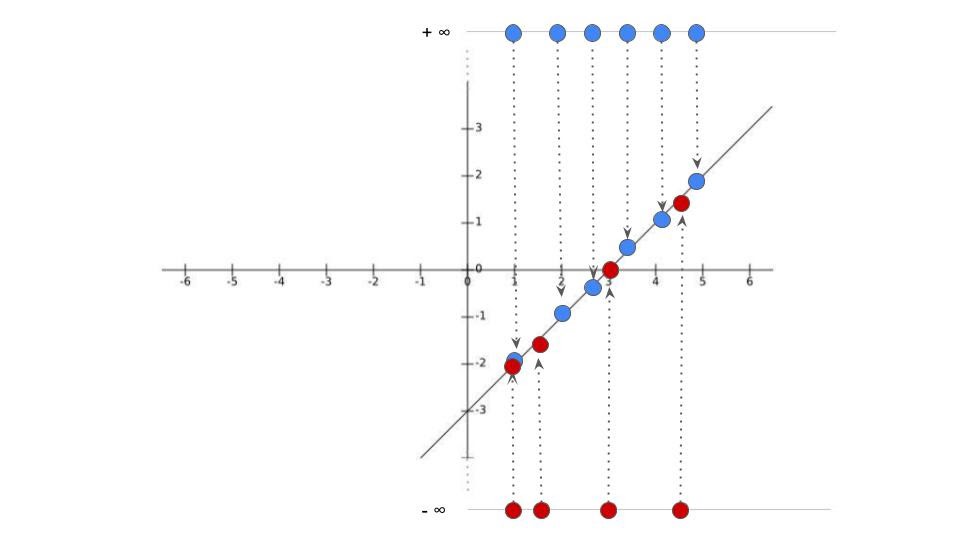
ML: Logistic Regression
- Plot them as a function of probability
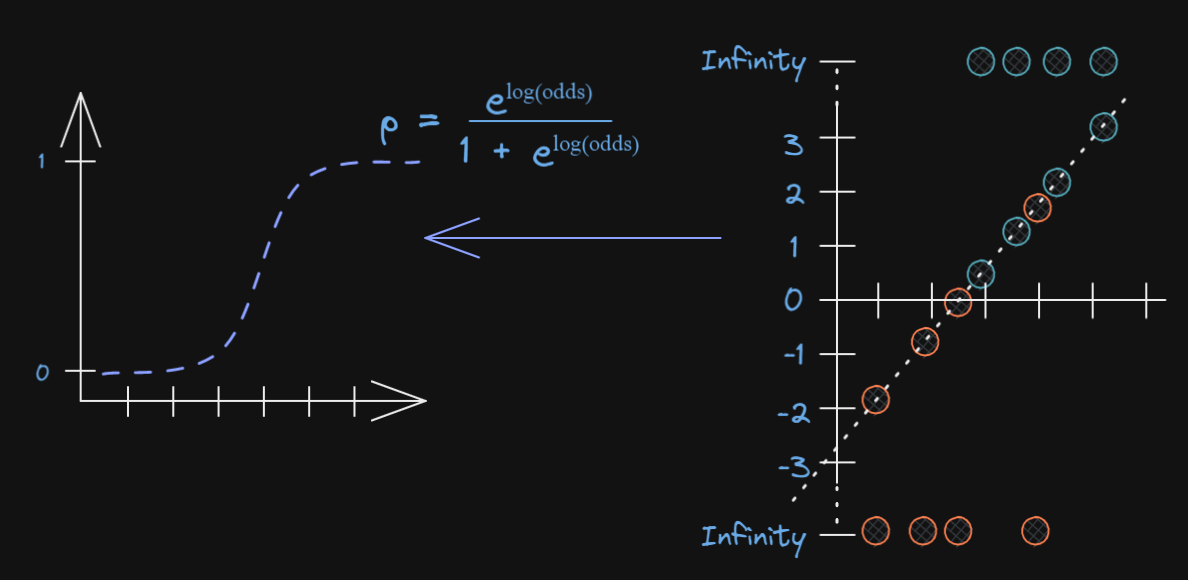
Now what?
We keep rotating the log odds(line) and projecting data on to it and transforming into probabilities
- Until we find maximum likelihood!
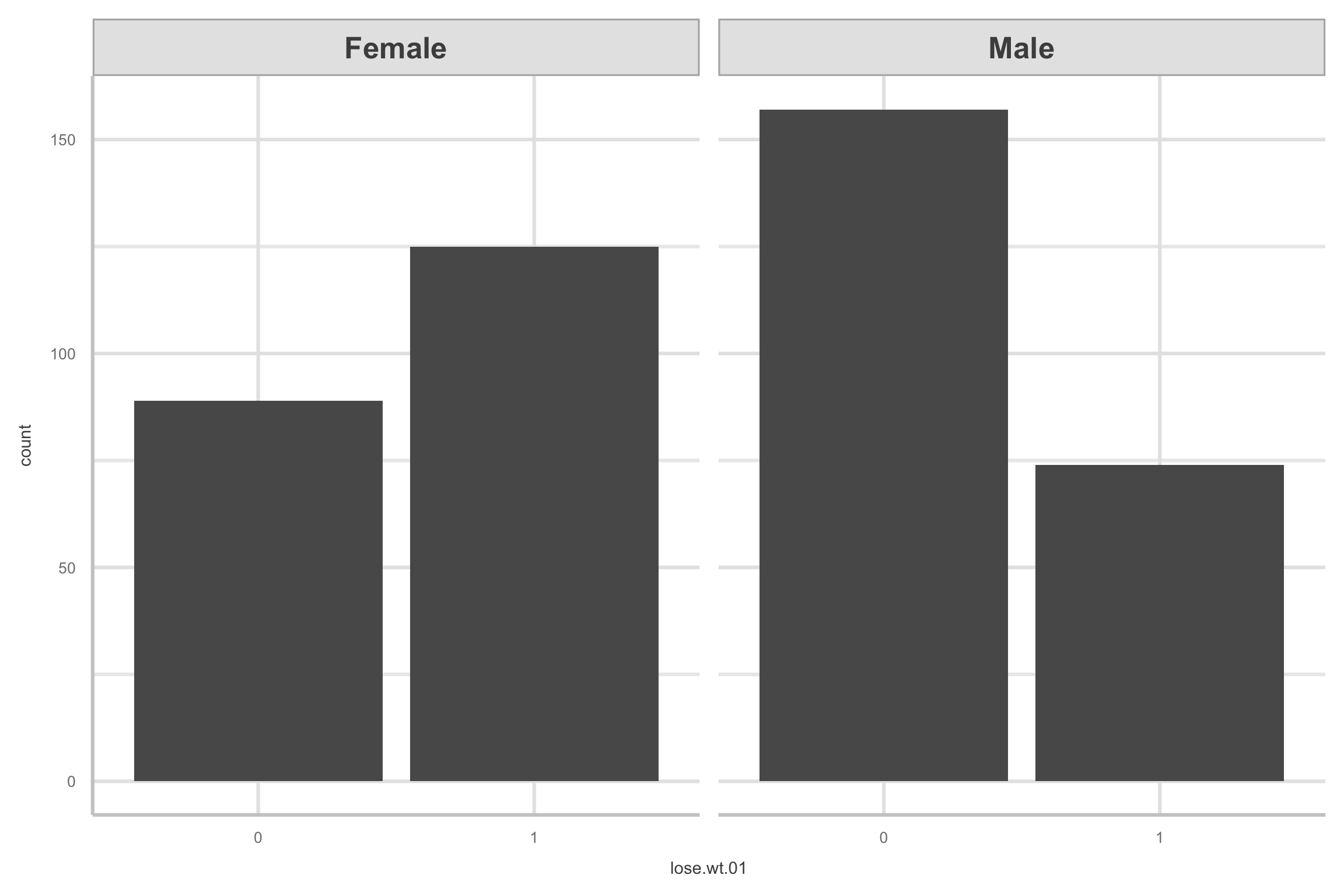
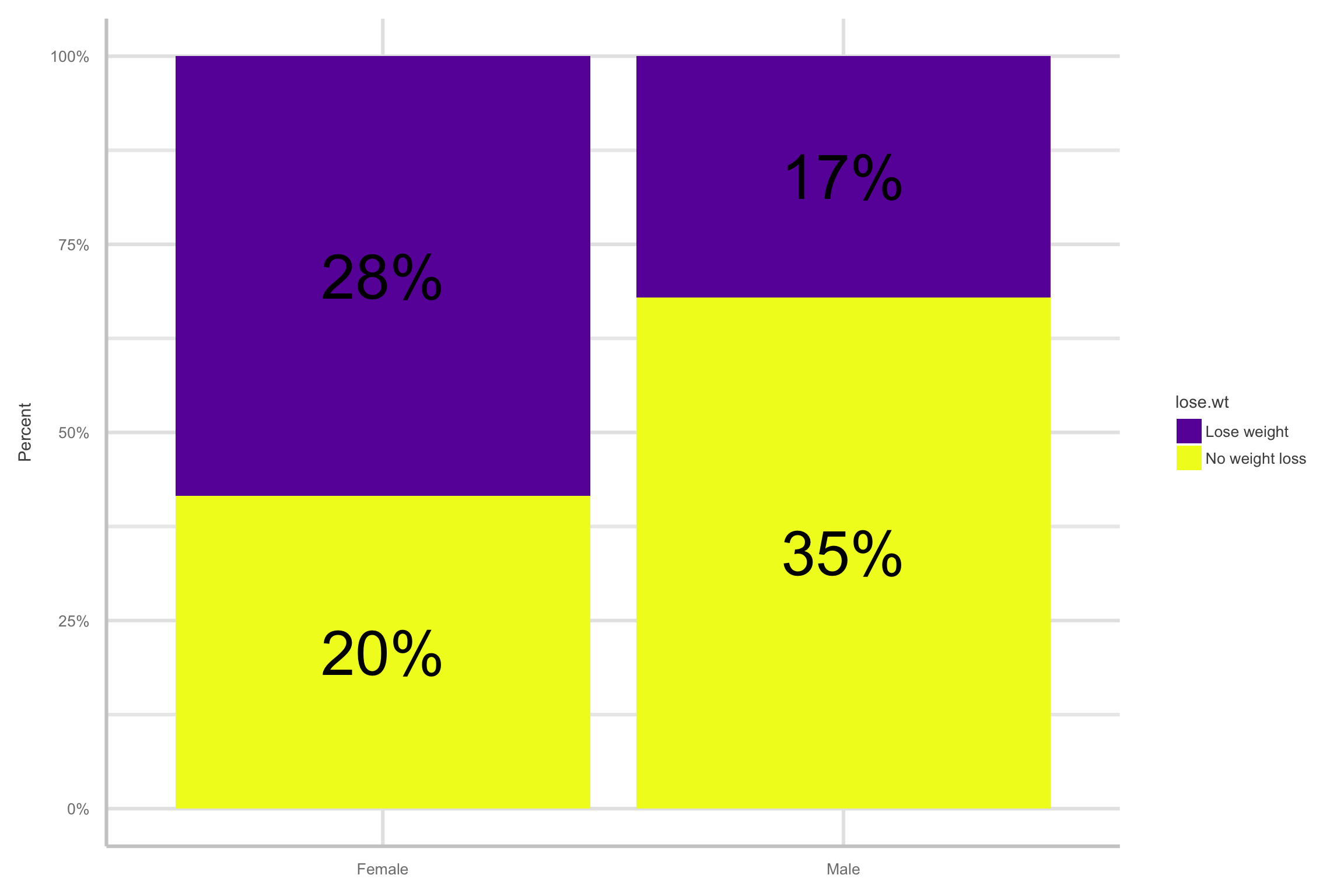
Exploratory data analysis
- Here are two versions of comparing
lose.wt.01bysex
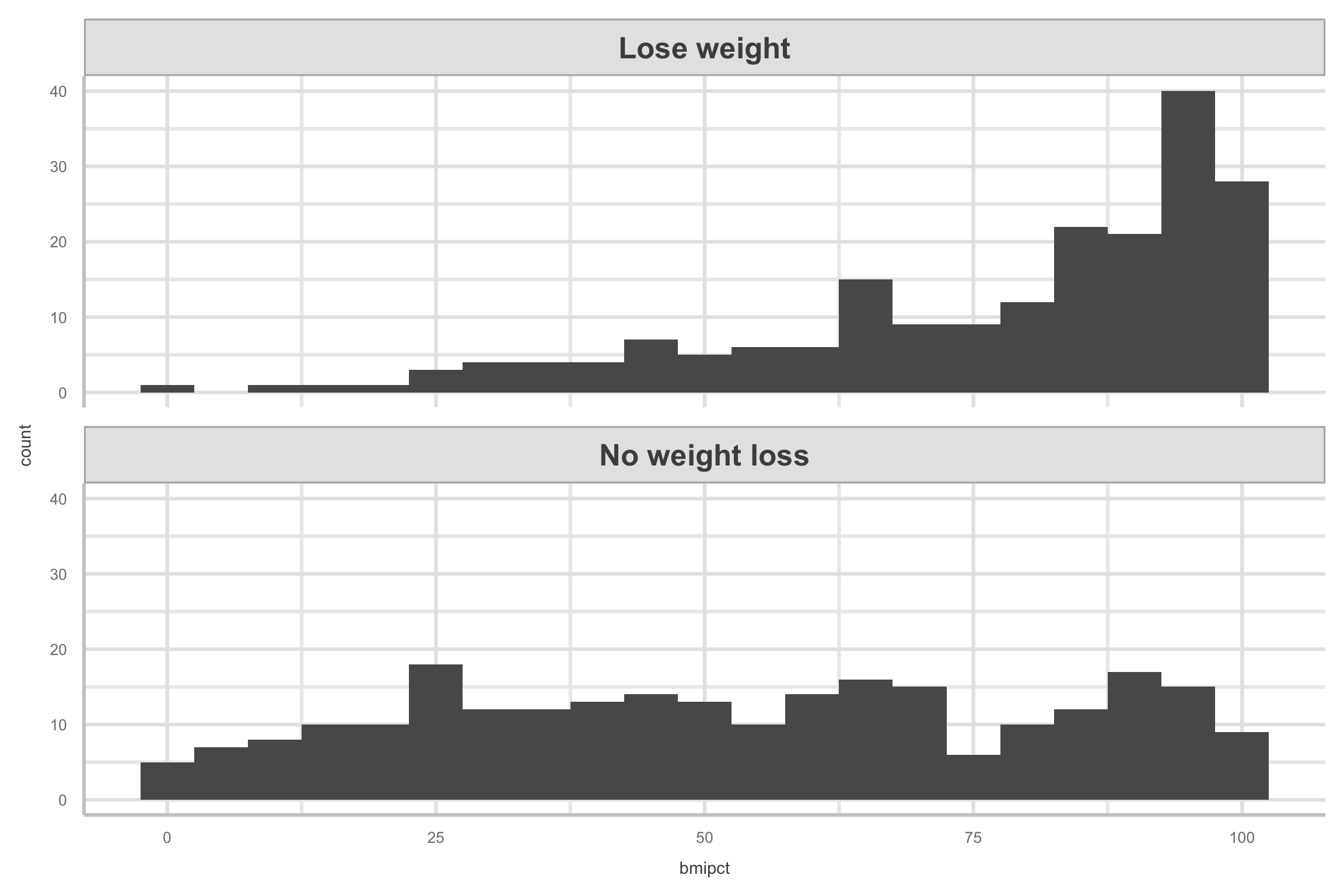
Exploratory data analysis
- Here are the histograms for
bmipct, faceted bylose.wt.
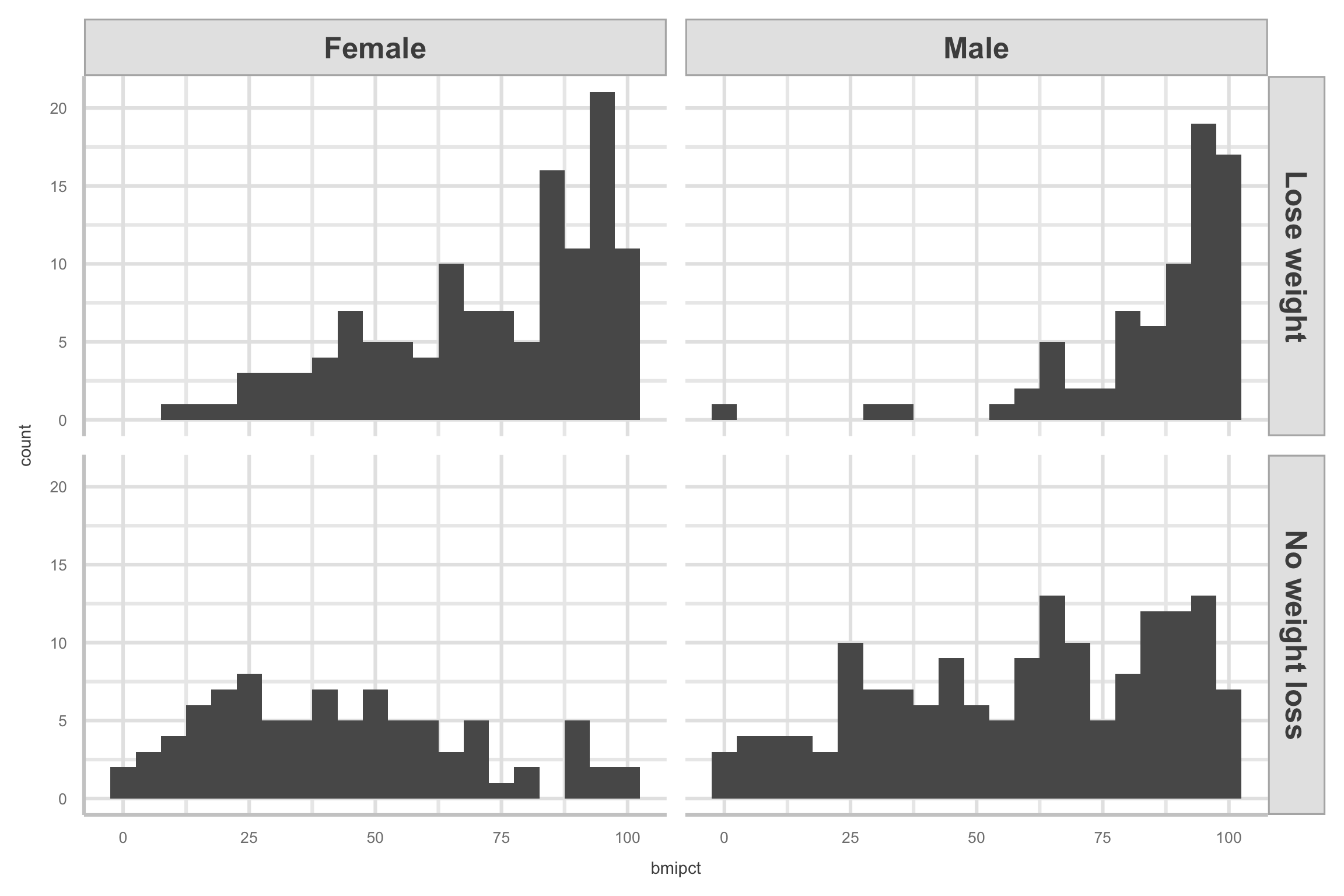
Exploratory Data Analysis
- Here are the histograms for
bmipct, faceted by bothlose.wtandsex
Model Comparisons
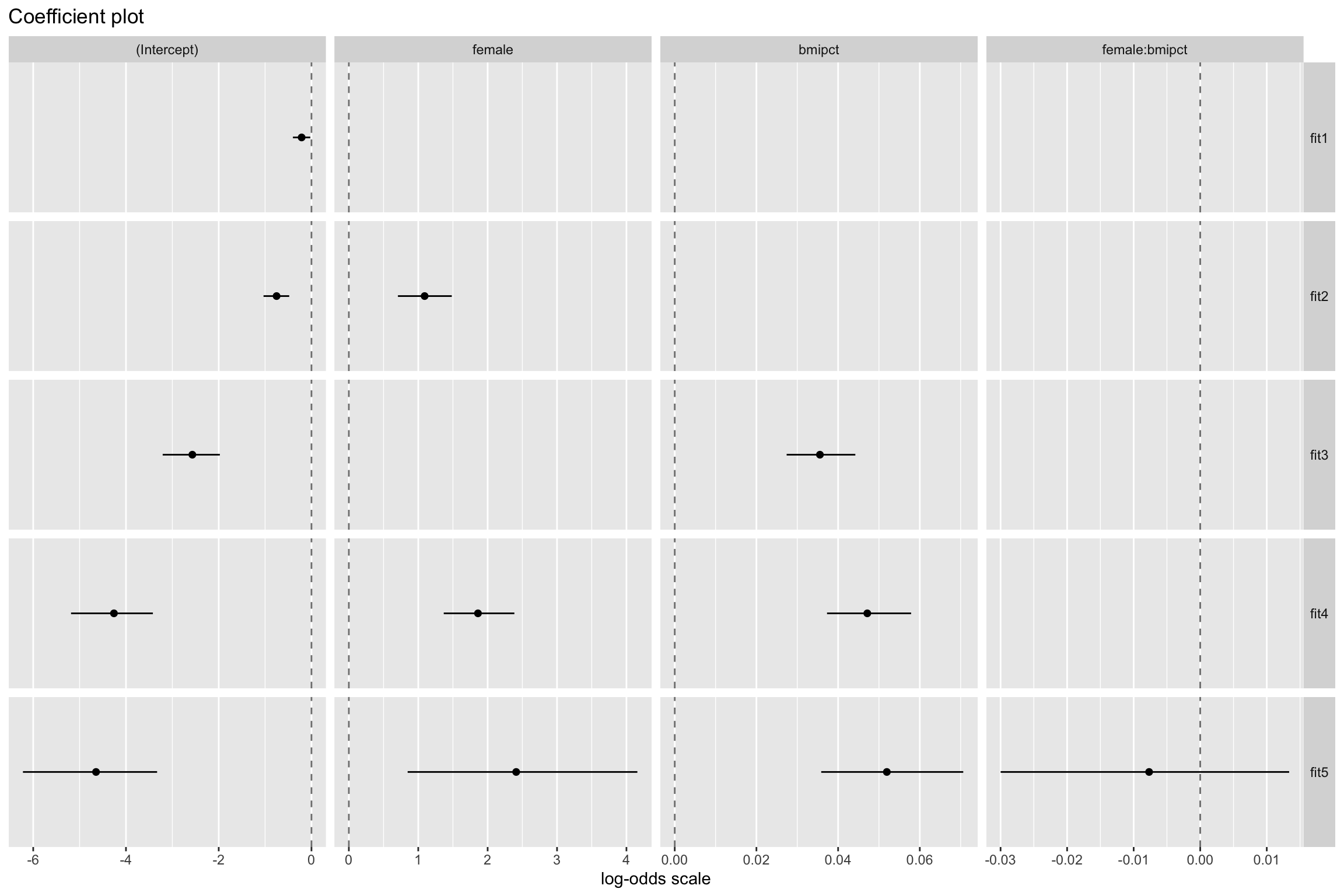
- The interaction term
female:bmipct(i.e., \(\beta_3\)) would not be statistically significant
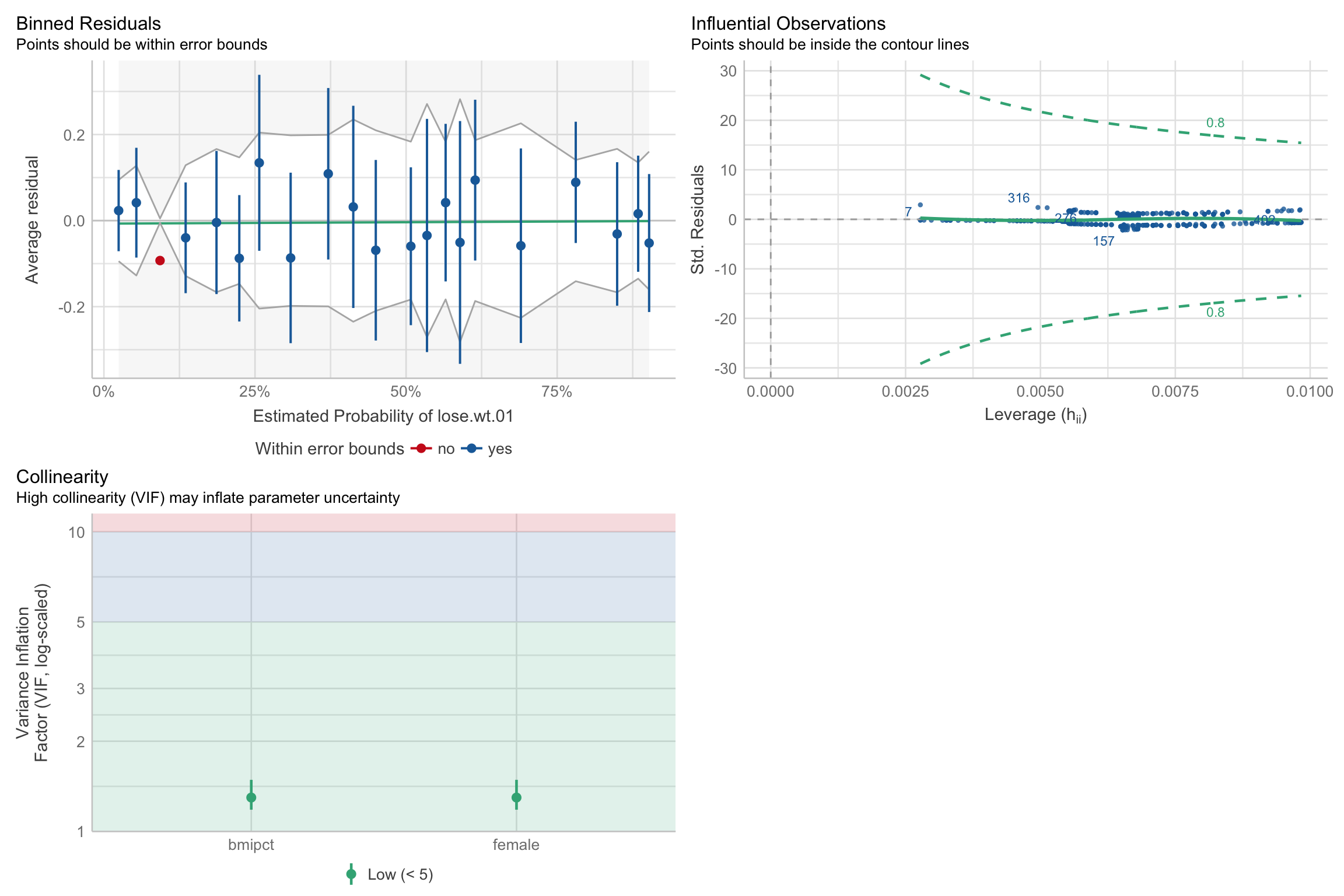
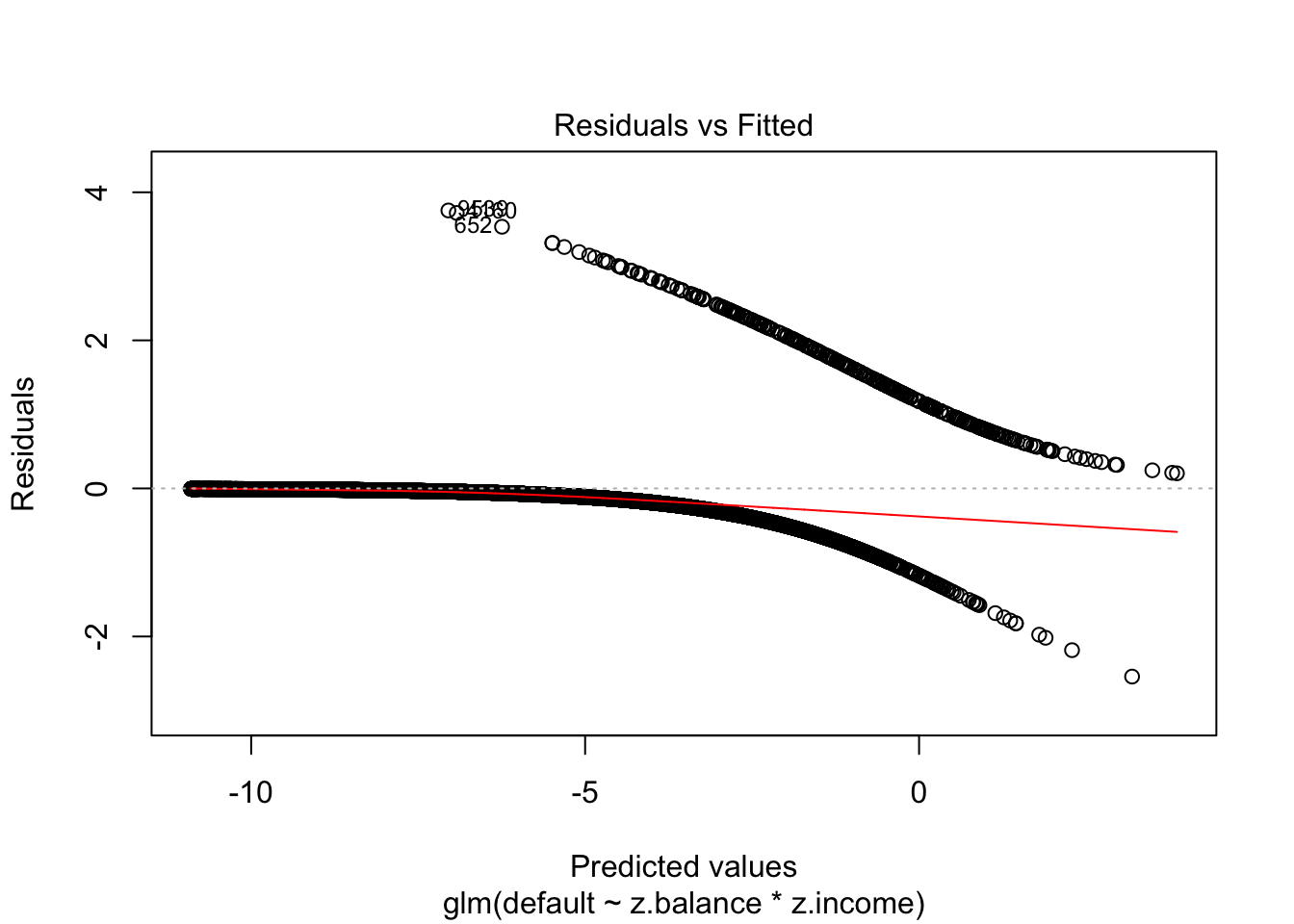
Model fit
- Plotting normal residuals are not really informative/useful
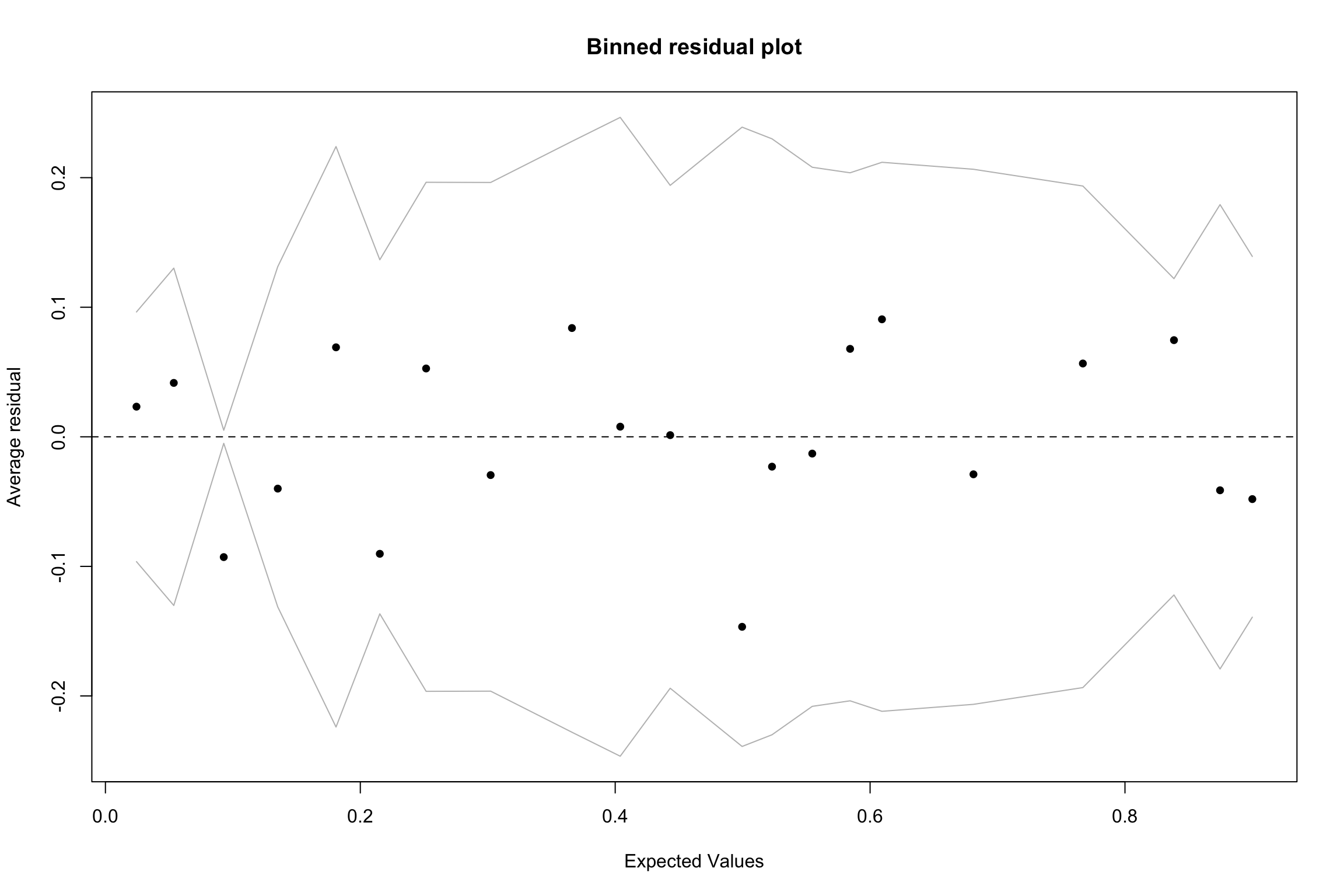
Binned residuals
Binned residuals
- Calculate raw residuals
- Order observations (probabilities of DV or predictor variable)
- Create g bins of approximate equal size \(\sqrt(n)\)
- Calculate average residuals
- Plot average residuals vs. average predicted probability (or predictor value)
Visualizing
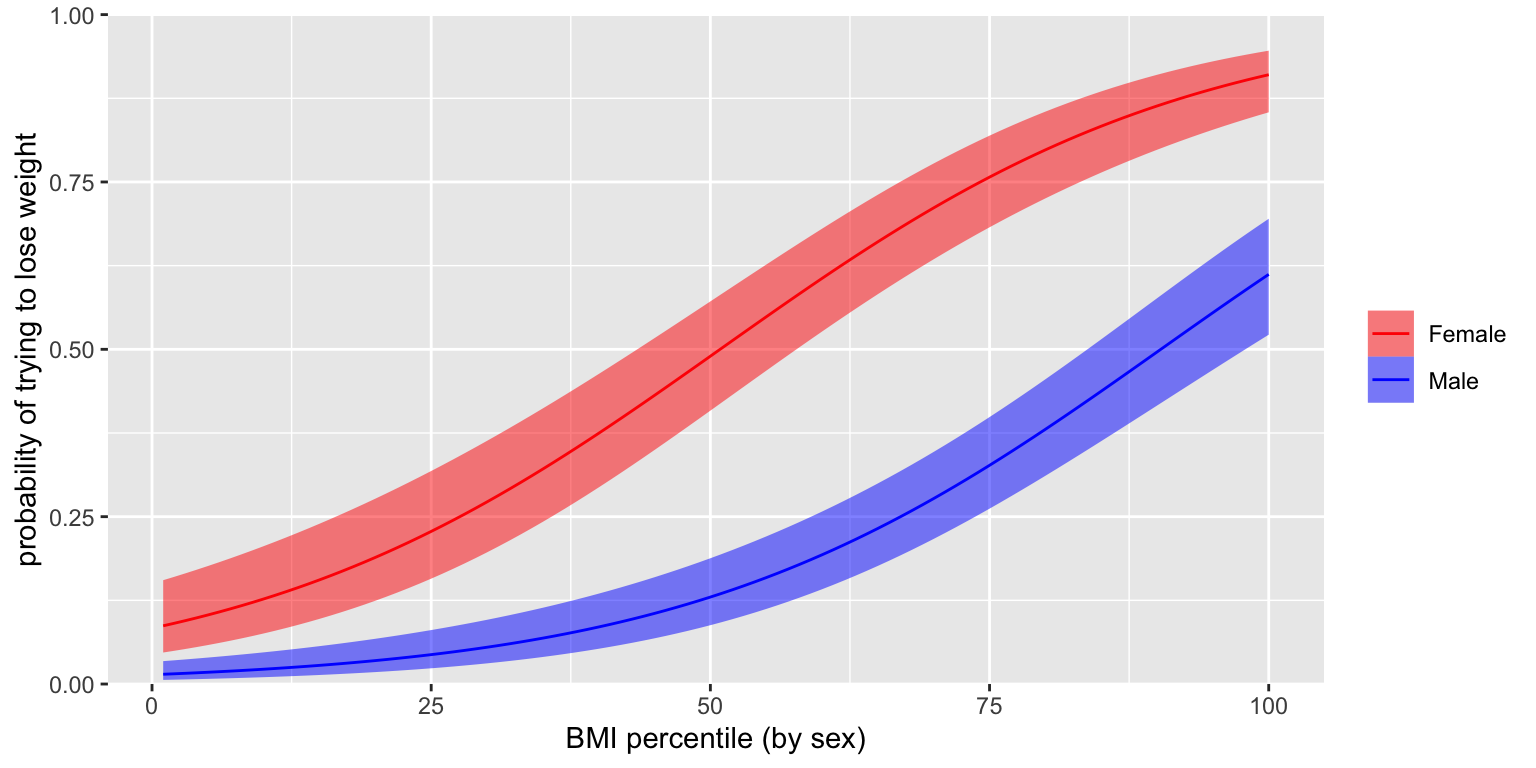
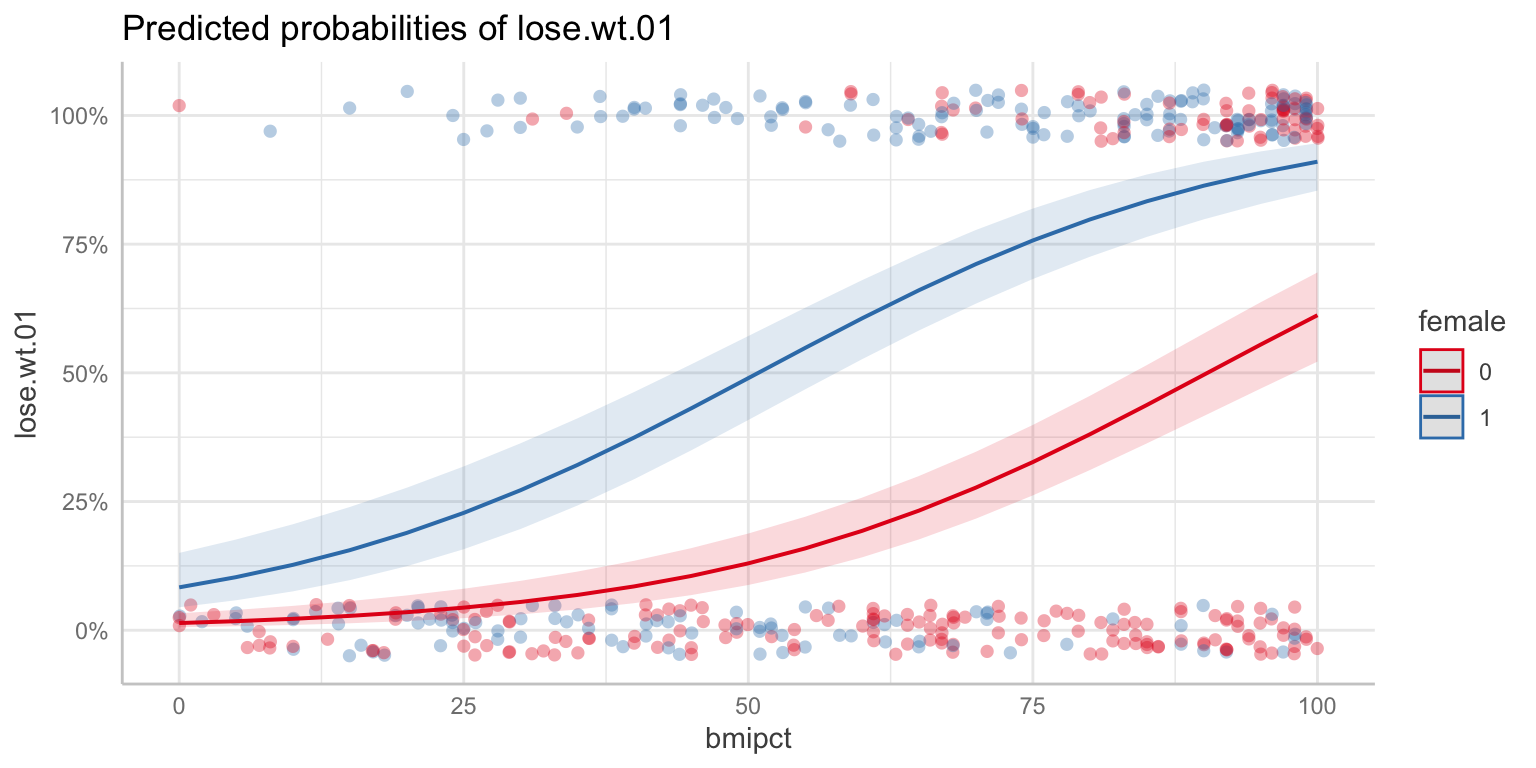
Logistic regression assumptions
Can plot with
easystats:)Note
- Should check binned residuals of the predictor variables as well