Introduction to Structural Equation Modeling in R
Princeton University
2024-04-14
Structural equation modeling

You already know how to do it!
It is regression on steroids
Model many relationships at once, rather than run single regressions
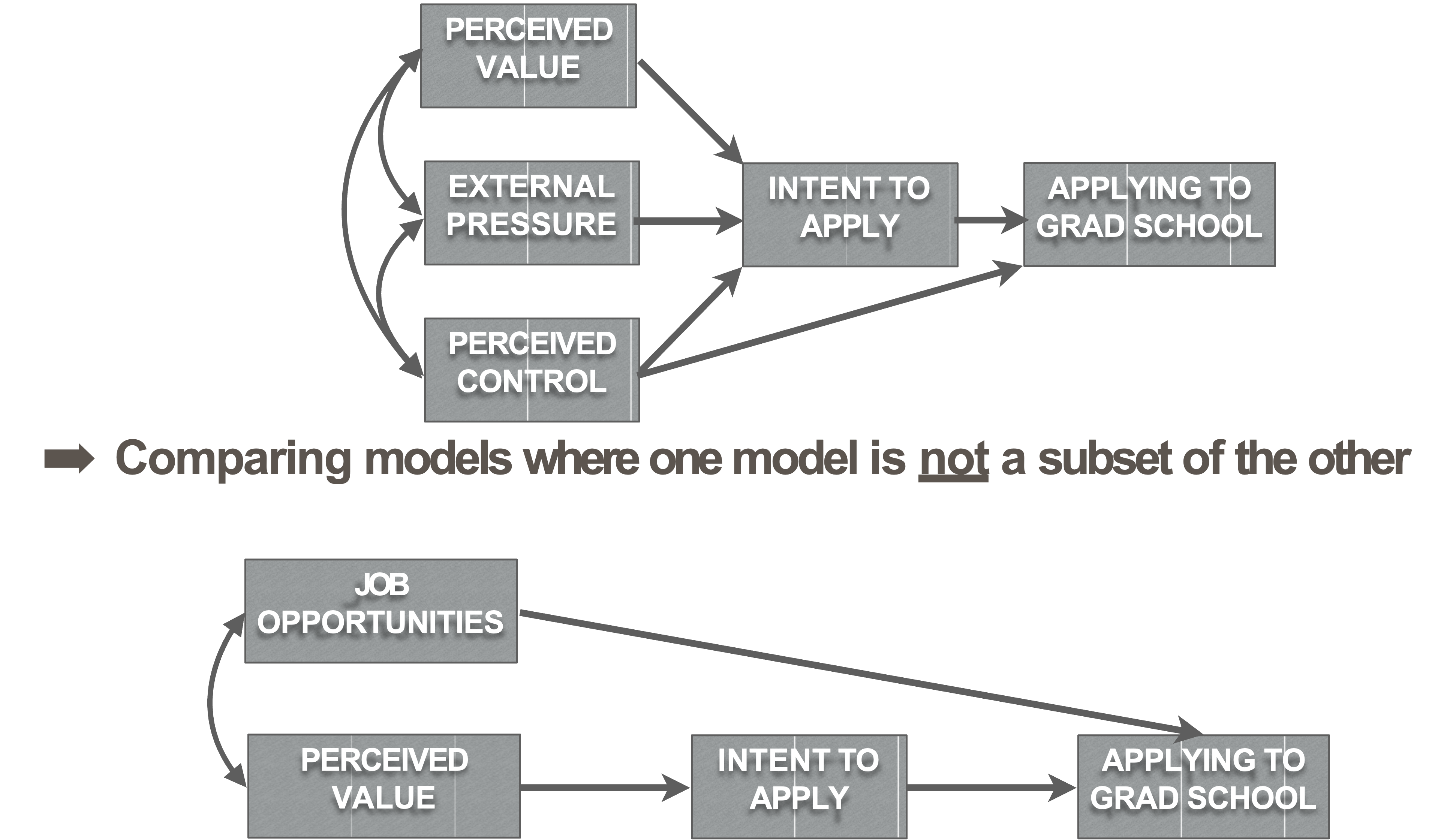
Path analysis
- A method for testing any possible relationship between measured variables
Exogenous vs. endogenous variables
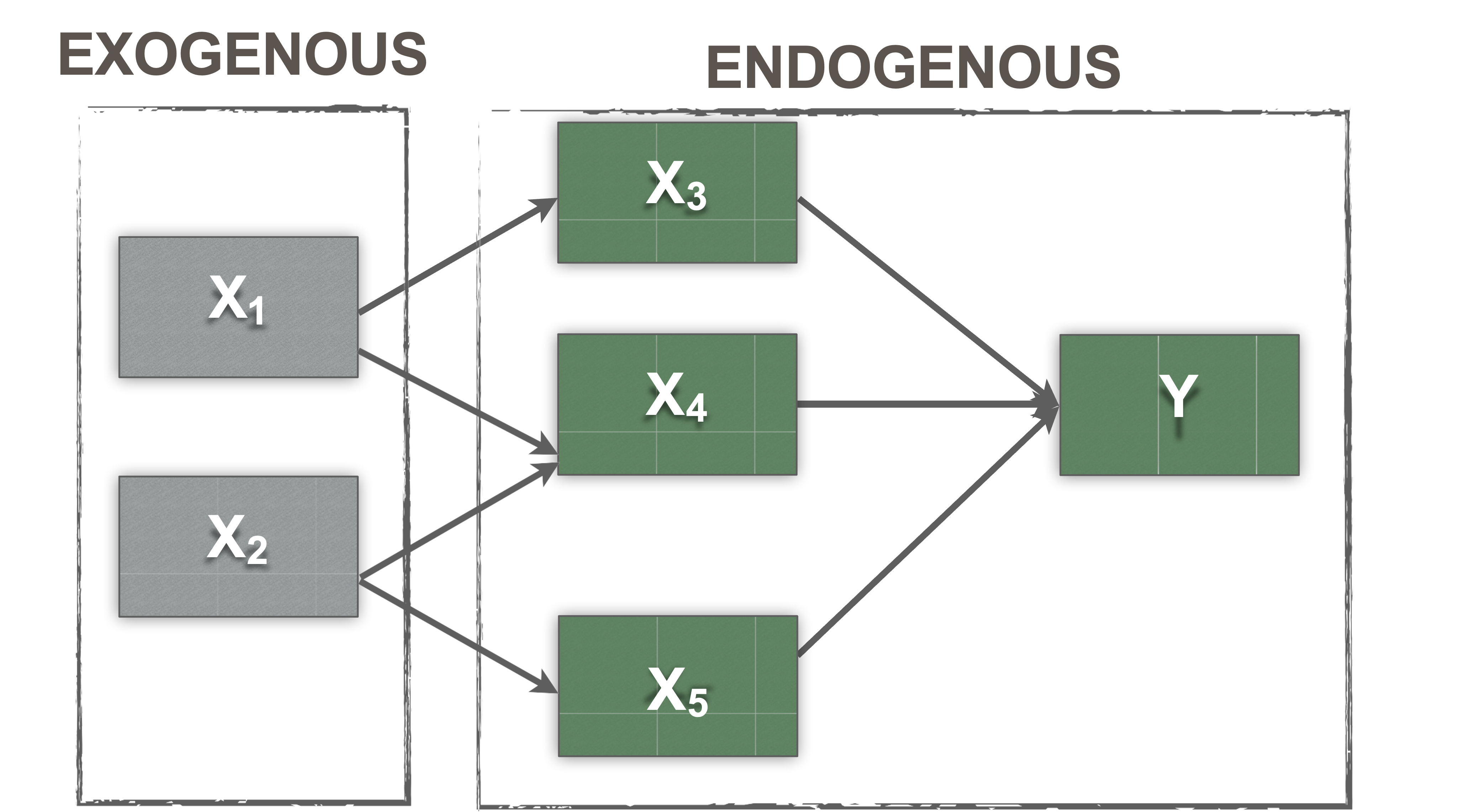
- Exogenous
- These are synonymous with independent variables
- You can find these in a model where the arrow is leaving the variable
- They are thought to be the cause of something
- Have variance
- Covary with other exogenous variables (default)
Exogenous vs. endogenous variables
- Endogenous
- These are synonymous with dependent variables
- They are caused by the exogenous variables
- In a model diagram, the arrow will be coming into the variable
- Have error terms (disturbances)
Manifest variables vs. latent variables
Manifest or observed variables
Represented by squares ❏
Measured from participants, business data, or other sources
While most measured variables are continuous, you can use categorical and ordered measures as well
Manifest variables vs. latent variables
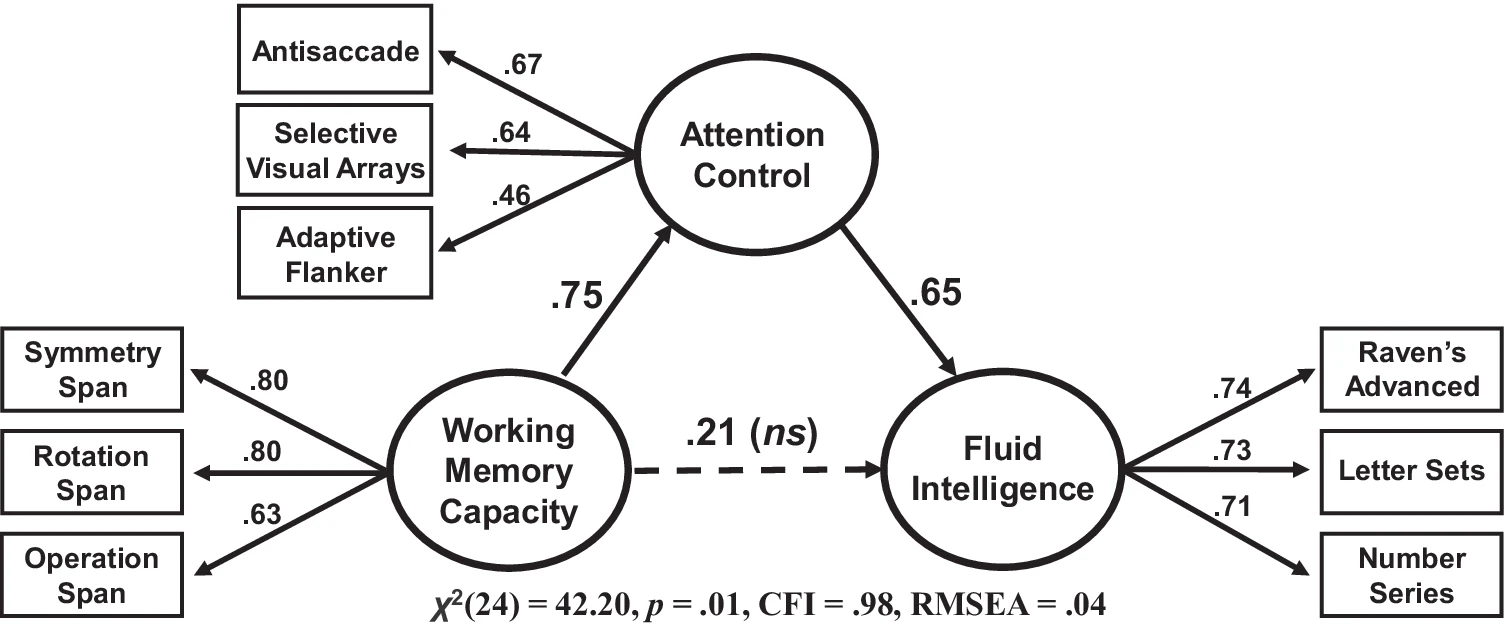
Latent variables
Represented by circles ◯
Abstract phenomena you are trying to model
Are not represented by a number in the dataset
Linked to the measured variables
Represented indirectly by those variables
Remember
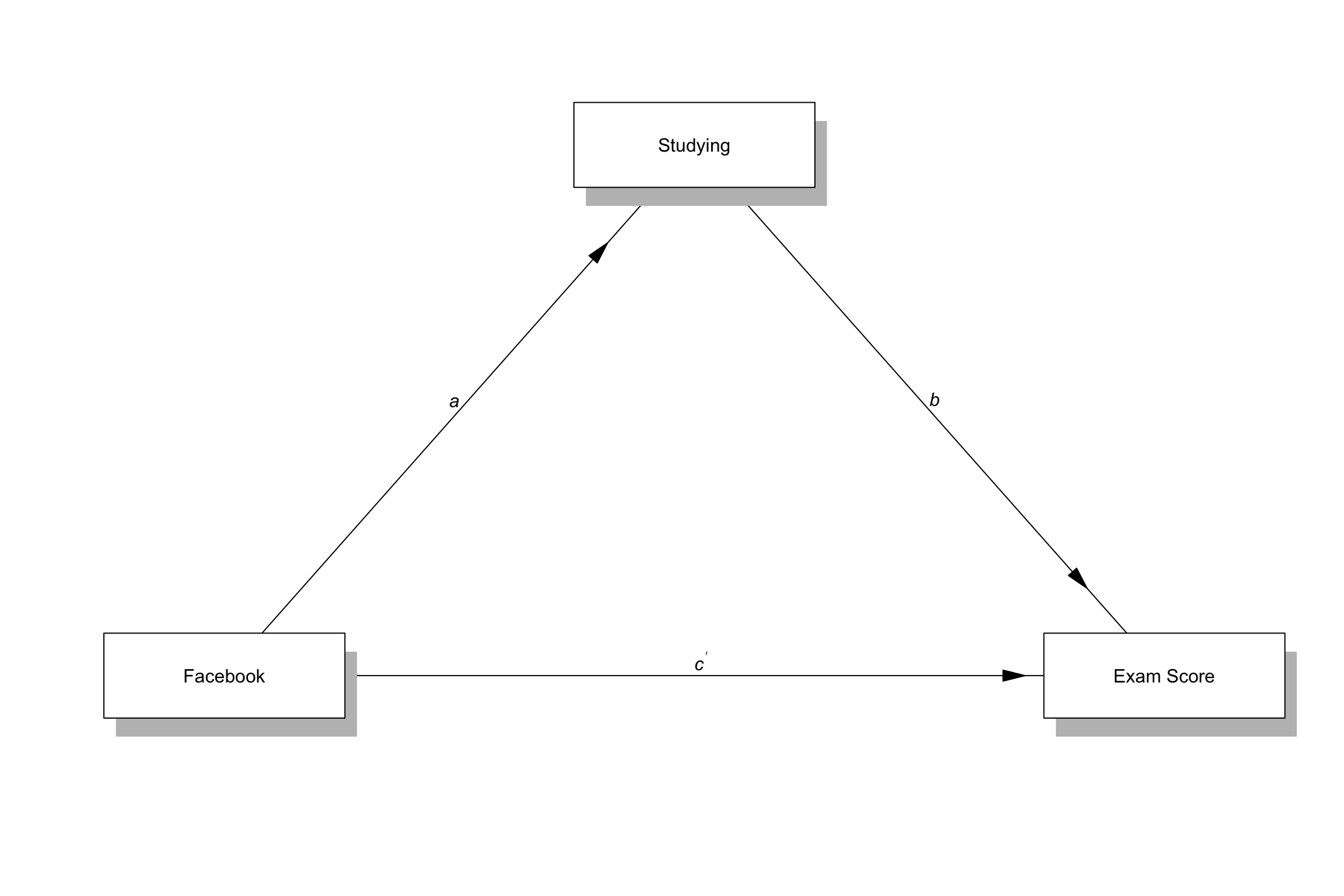
Y~X + ResidualHere that is
Endogenous ~ Exogenous + disturbance
Variances, covariances, and disturbances
- Variance
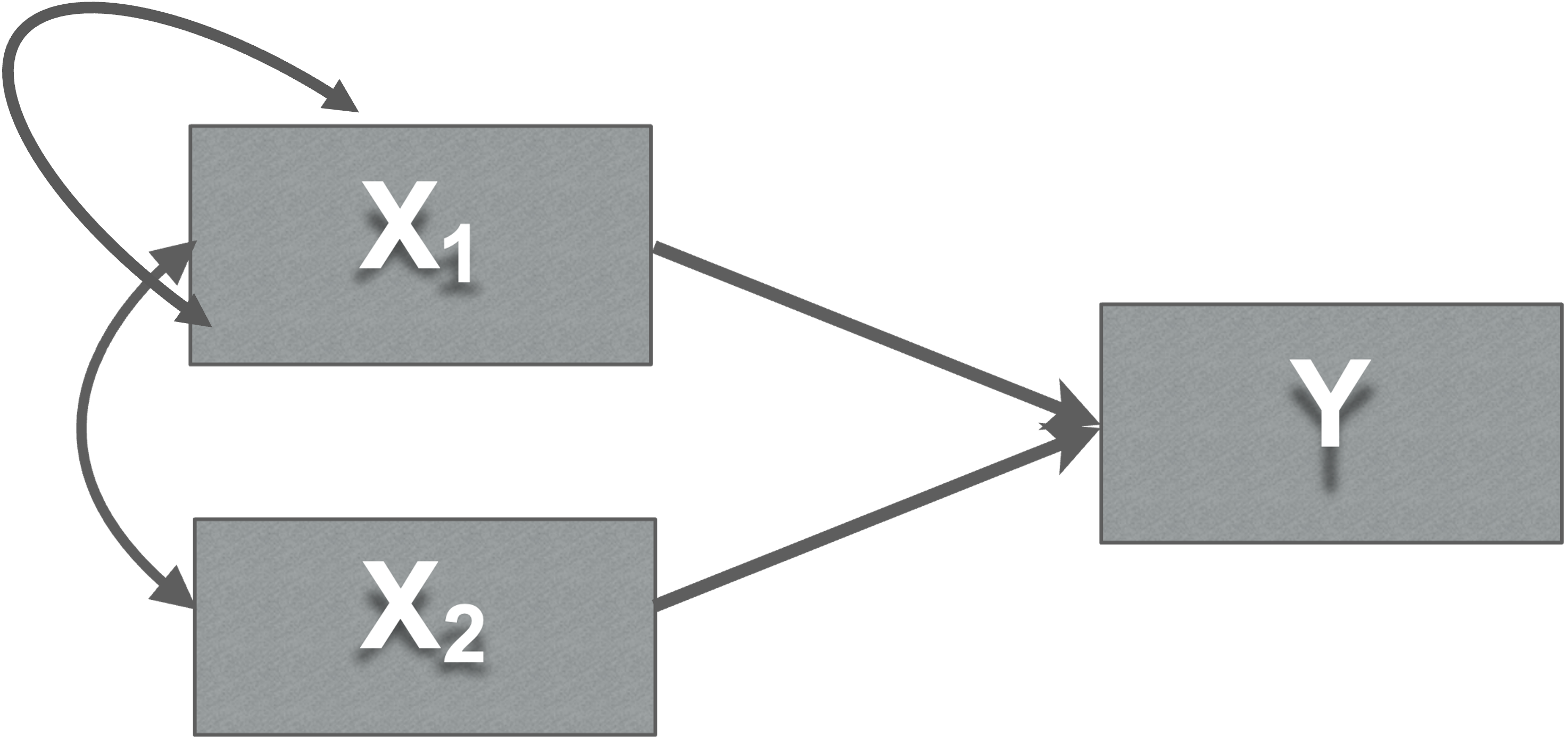
- Double headed arrows
- To itself
Variances, covariances, and disturbances
- Covariance paths
- Double headed arrows (Covariance paths)
- Exogenous variables may be correlated with each other, but not always…
Covariance meaning
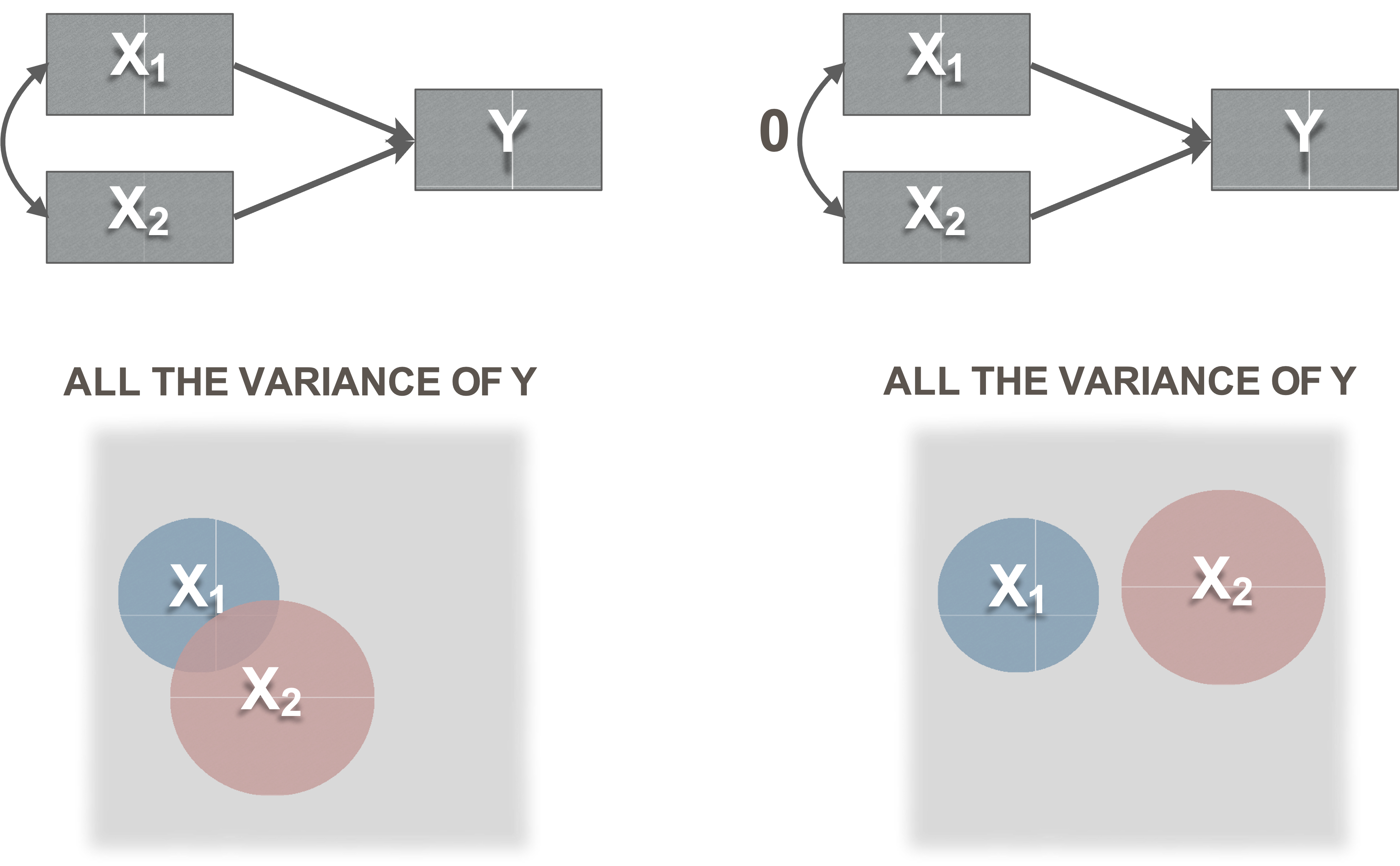
Variances, covariances, and disturbances
- Disturbances
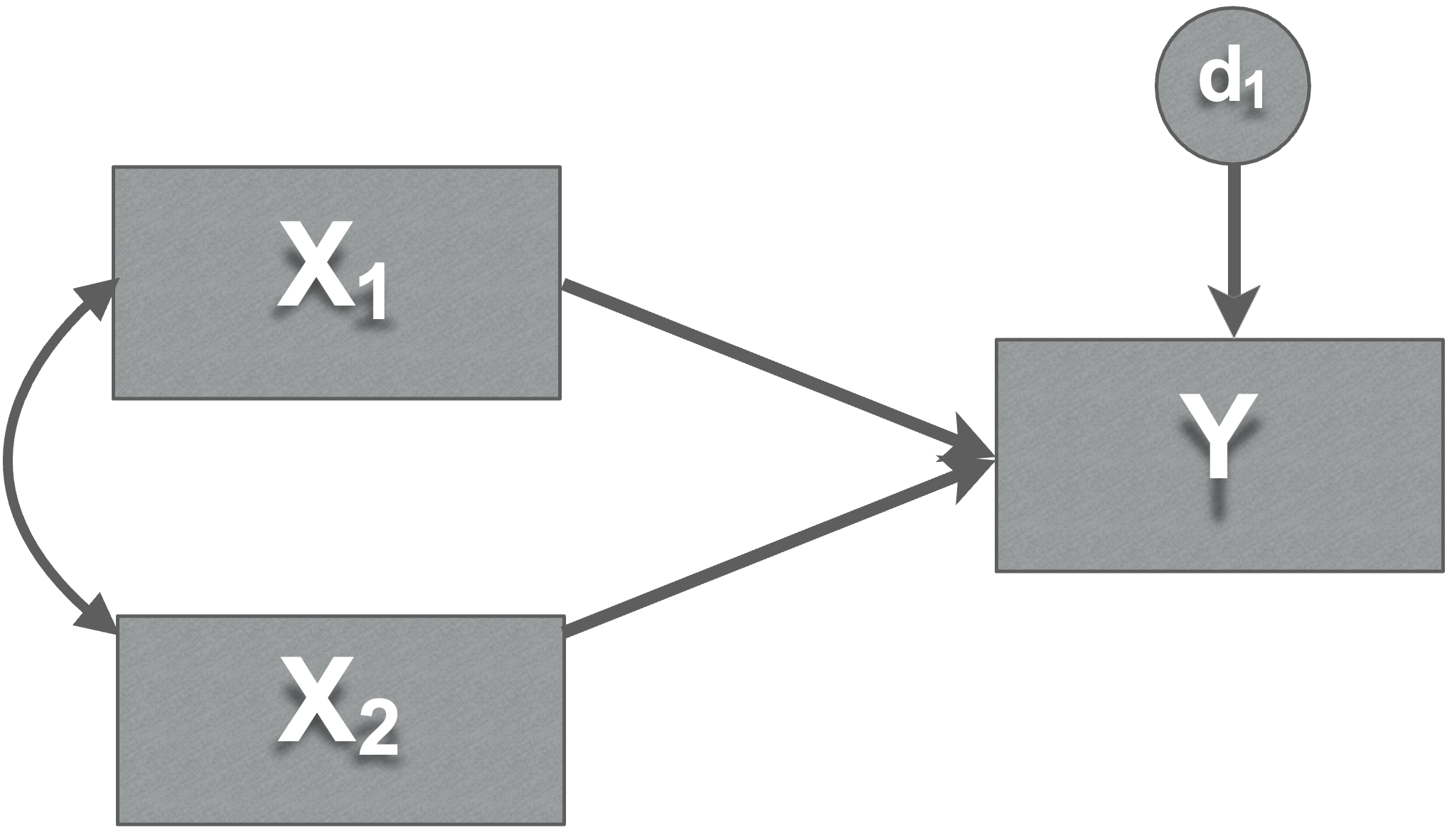
Represent the influence of factors not included in model
error in your prediction of each endogenous variable
Every endogenous variable has a disturbance
SEM models
Straight arrows are “causal” or directional
- Non-standardized solution -> these are your b or slope values
- Standardized solution -> these are your beta values
Curved arrows are non-directional
- Non-standardized -> covariance
- Standardized -> correlation
Cheat sheet
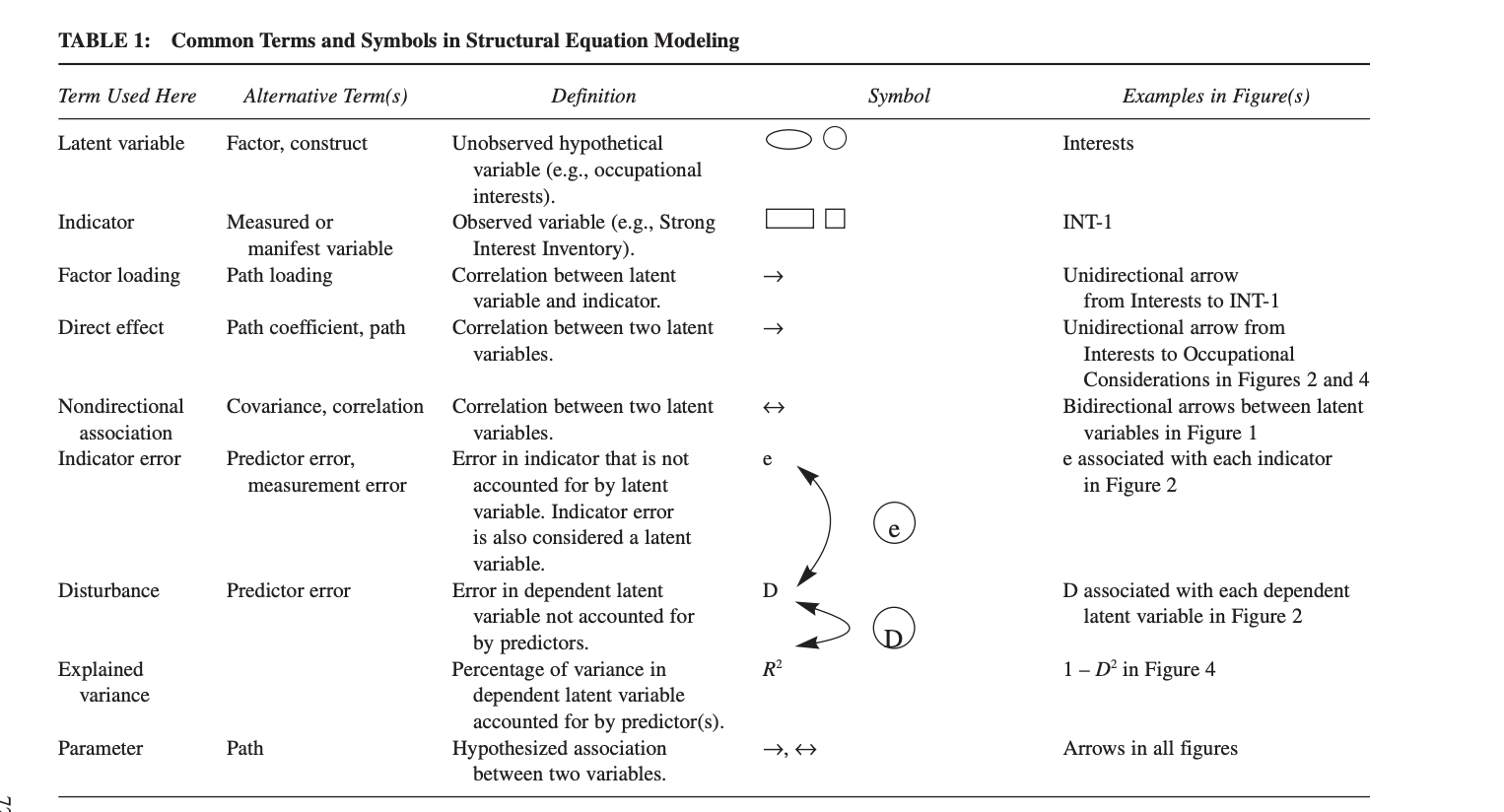
- Also here: https://davidakenny.net/cm/basics.htm
Why is it just regression?
Each endogenous variable is regressed on all exogenous variables that are connected in the chain that leads directly to it
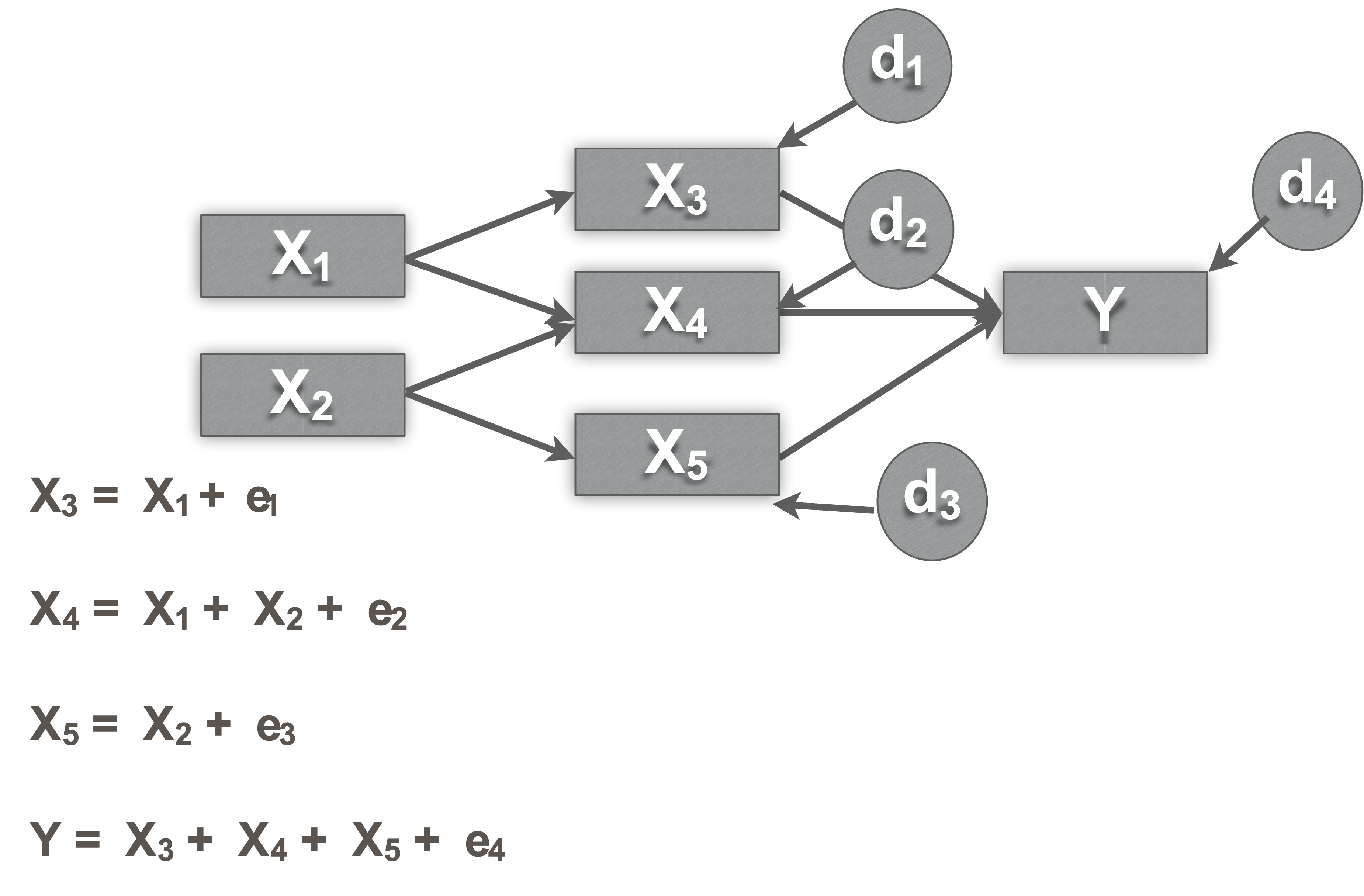
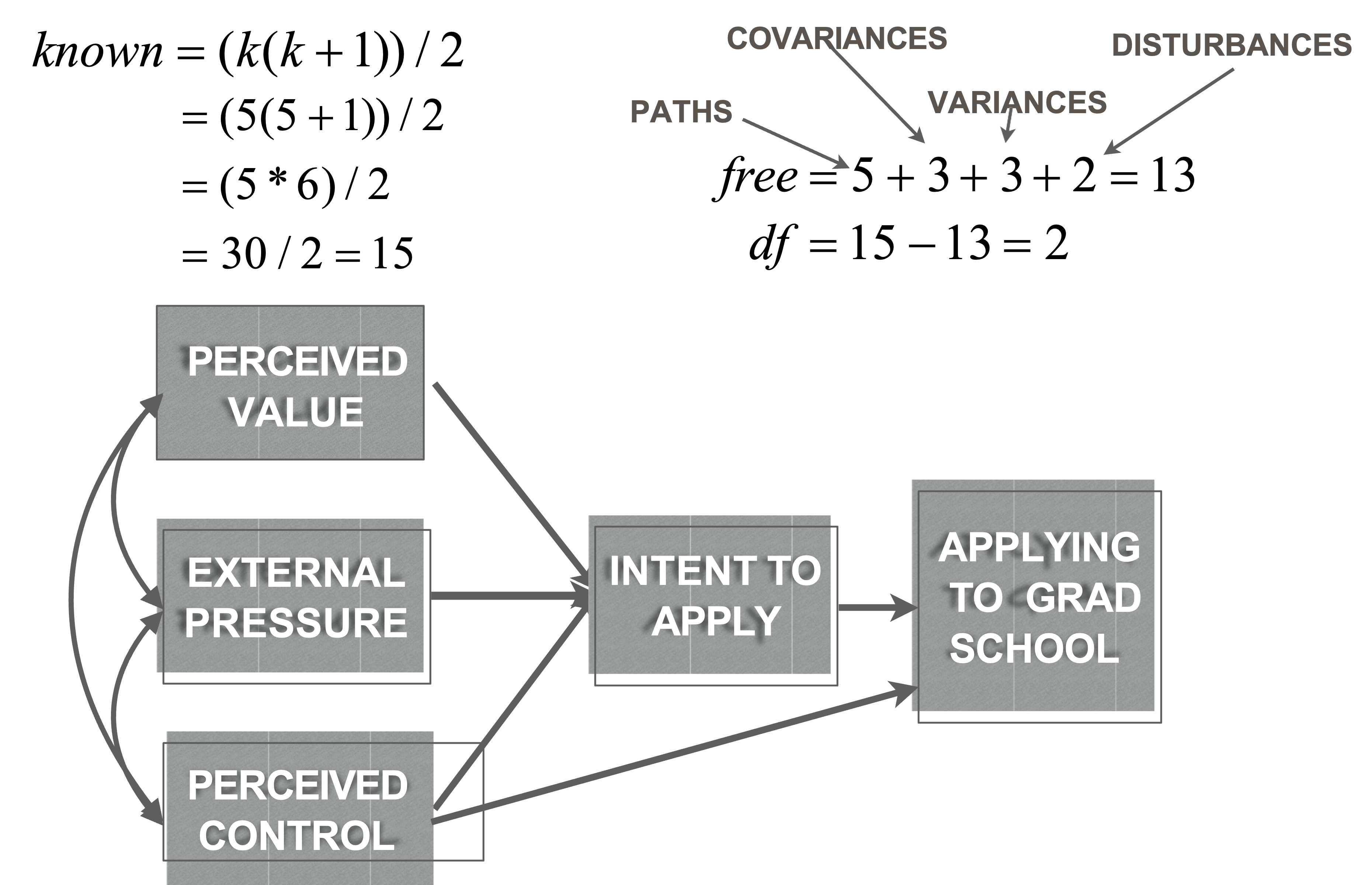
Identification
Over-identified - mathematical analogy
10=2x+y
2 = x-y
5 = x + 2y
- Several possible approximate solutions to solve all 3 equations
- Several unique but imperfect solutions means multiple models can be tested or compared
- You can’t evaluate fit without alternatives

Estimate DFs
- Let’s play a game

03:00
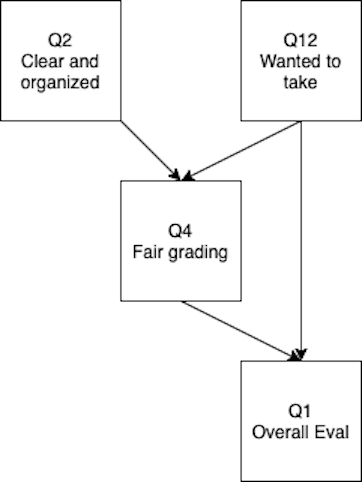
SEM steps

Model specification
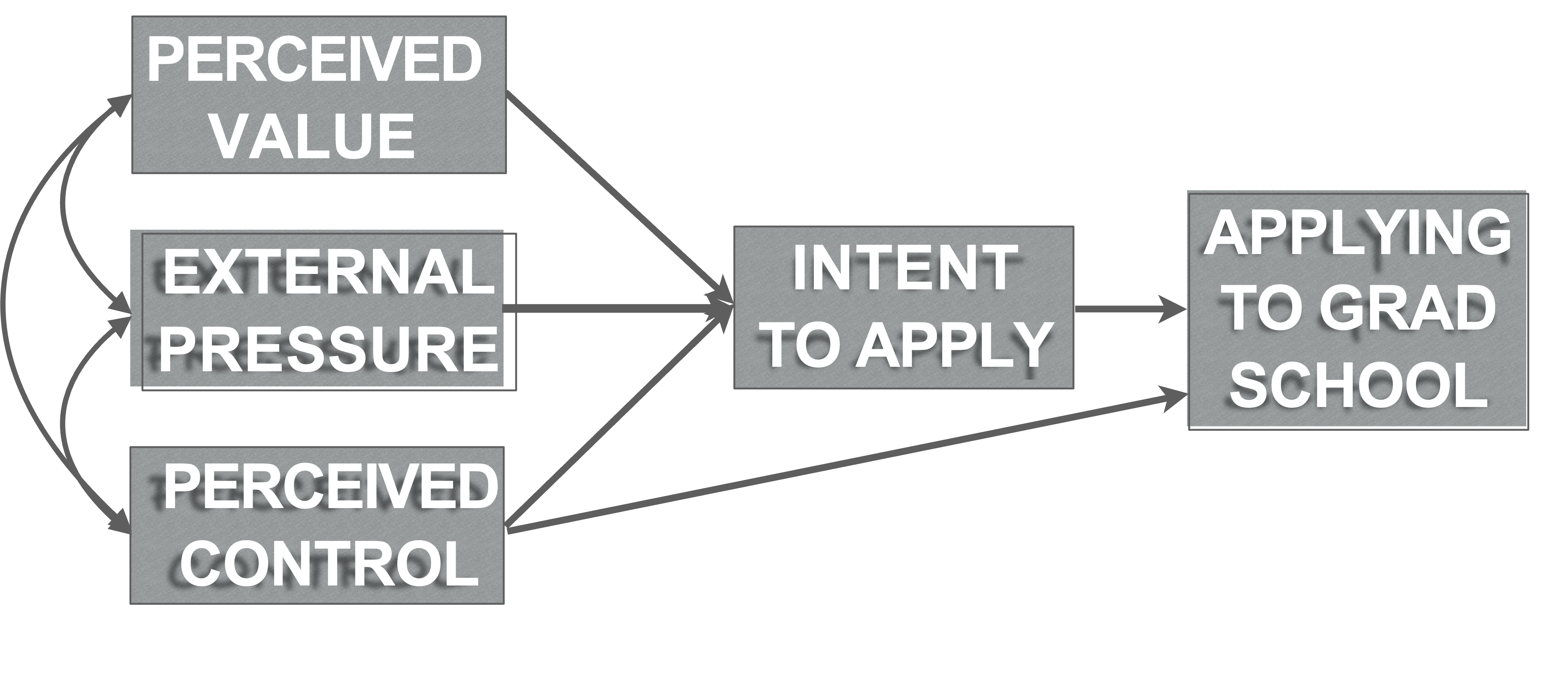
- Theory of planned behavior
Data screening
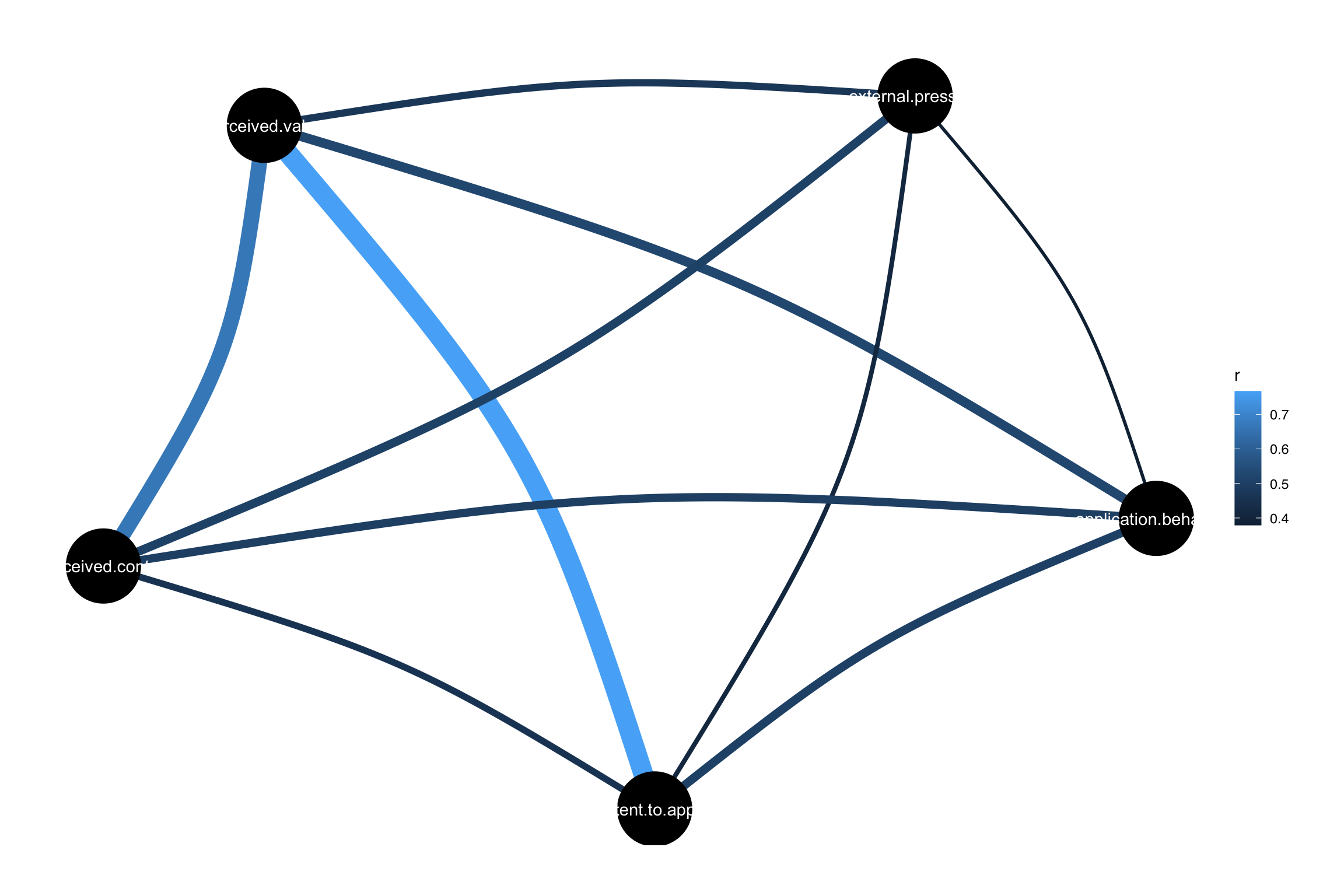
Identification
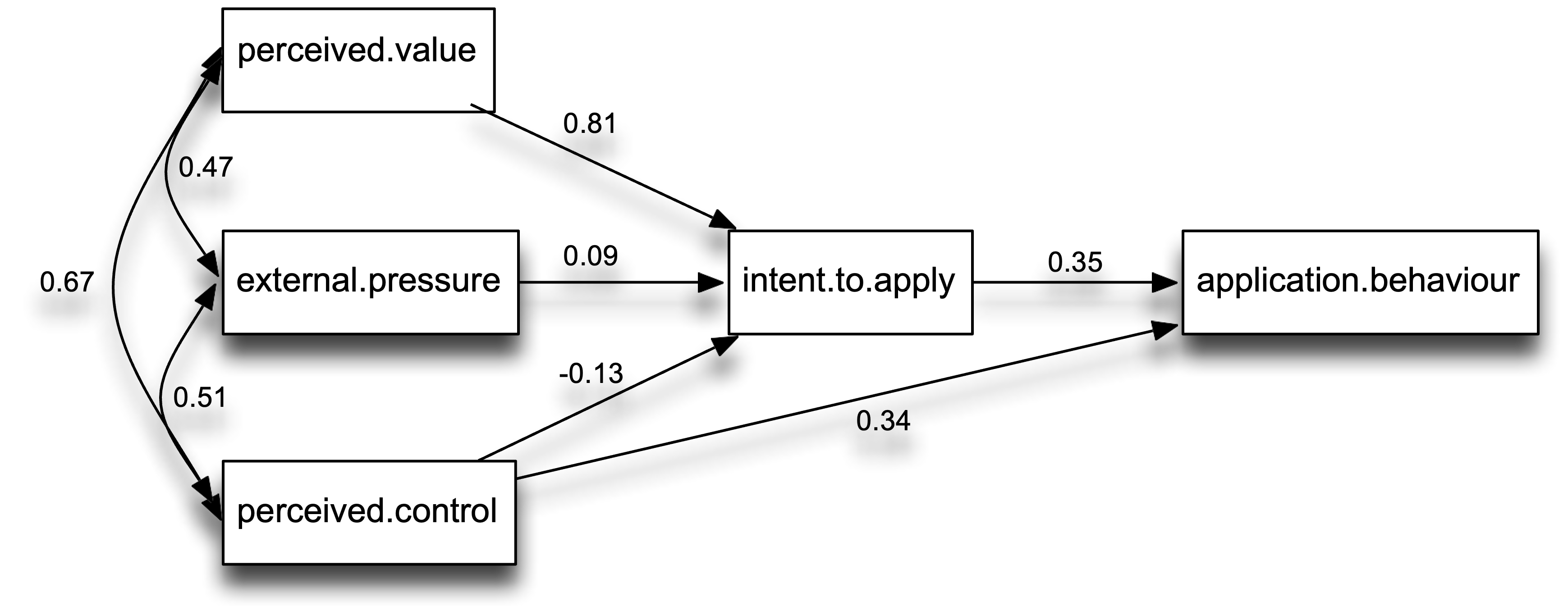
Visualize model
Visualize model
library(semPlot)
# Example of plotting the variables in specific locations
locations = matrix(c(0, 0, .5, 0, -.5, .5, -.5, 0, -.5, -.5), ncol=2, byrow=2)
labels = c("Intent\nTo Apply","Application\nBehaviour","Perceived\nValue","External\nPressure","Perceived\nControl")
diagram = semPaths(fit, whatLabels="std", nodeLabels = labels, layout=locations, sizeMan = 12, rotation=2)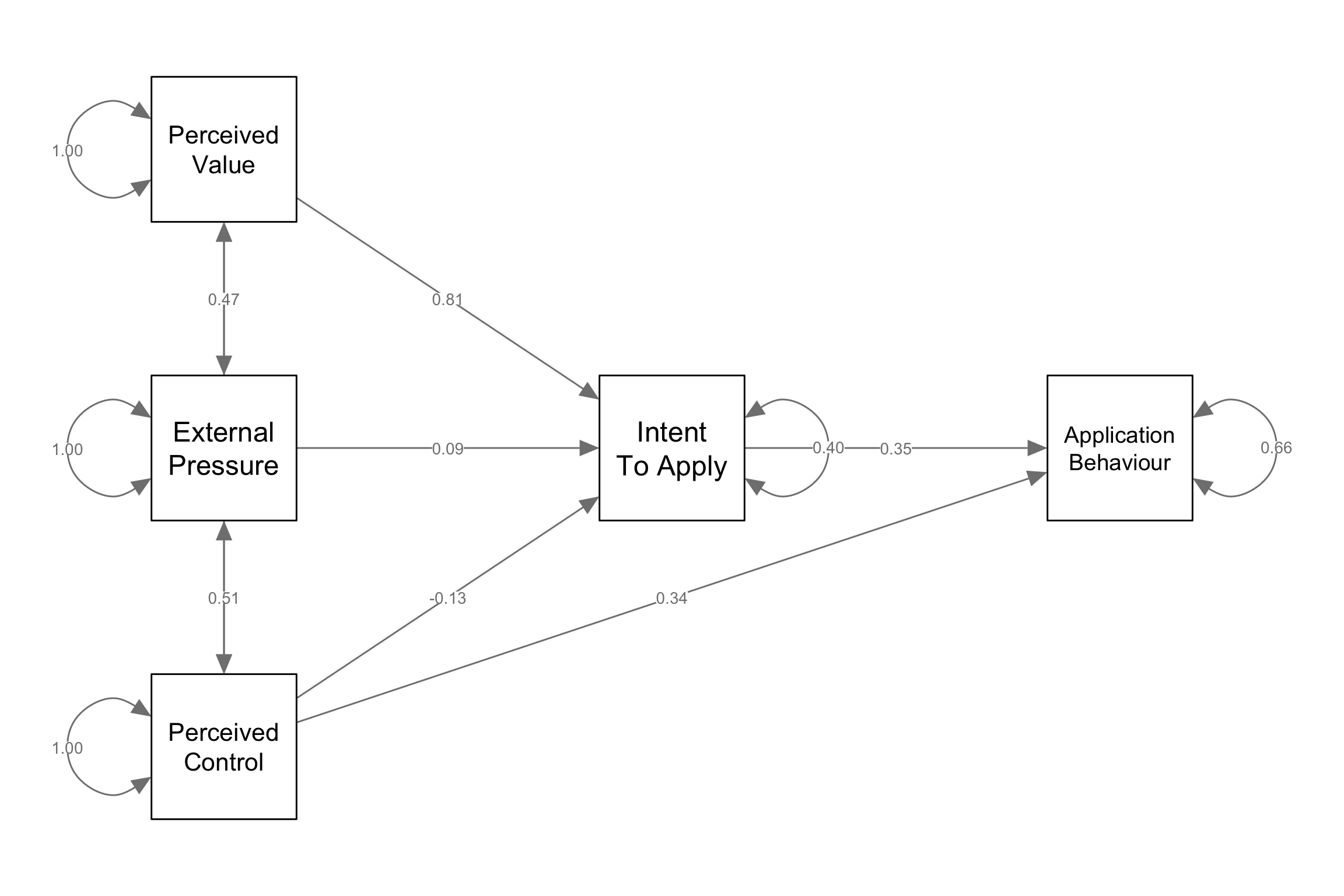
Constraining paths
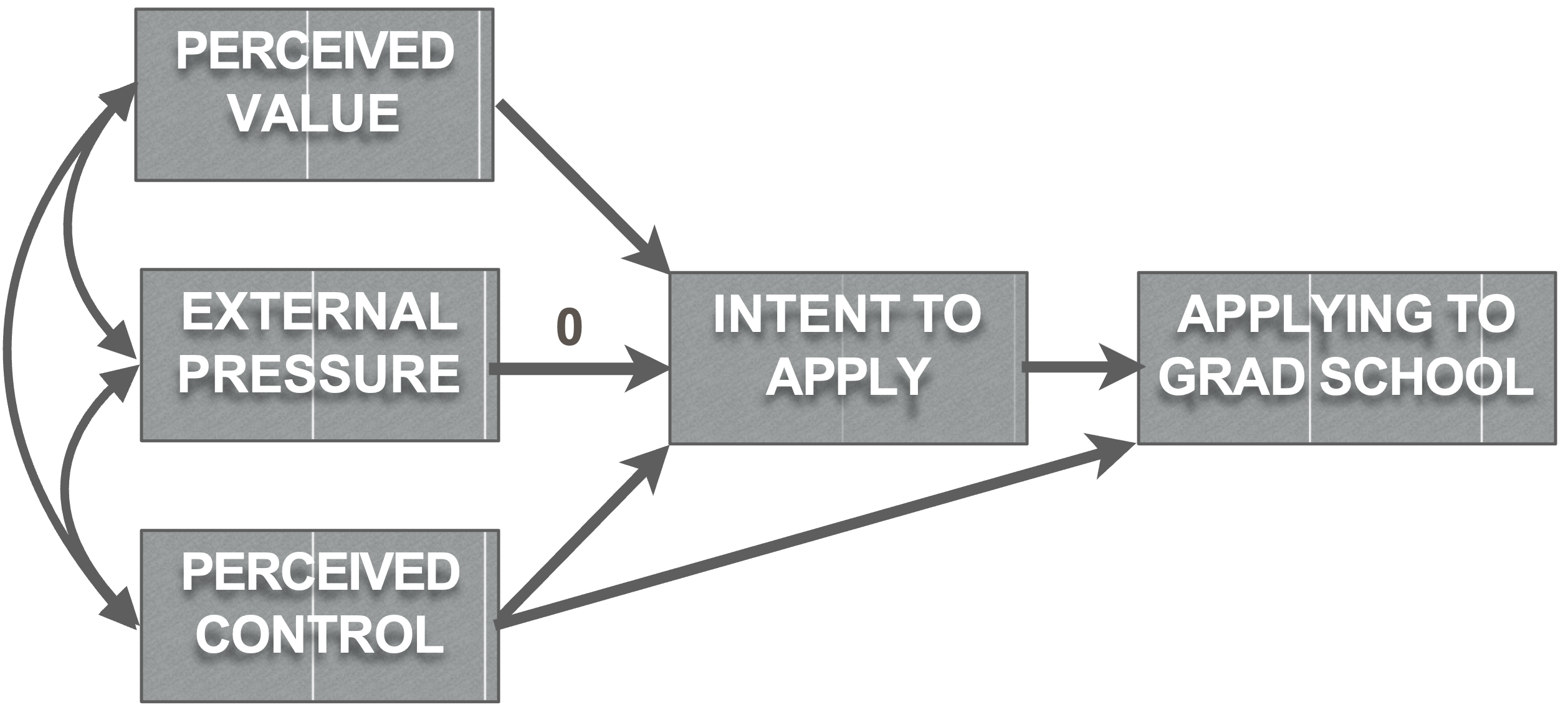
grad_model_constrained = '
intent.to.apply ~ a*perceived.value + 0*external.pressure + c*perceived.control
application.behaviour ~ d*intent.to.apply + perceived.control
perceived.control ~~ perceived.value # These are covariance paths
perceived.control ~~ external.pressure # These are covariance paths
external.pressure ~~ perceived.value # These are covariance paths
value.through.intent:=a*d
control.through.intent:=c*d
'
grad_analysis_constrained =
sem(grad_model_constrained, data=grad, se="bootstrap")Non-nested model comparisons