I Dont Likert You: Ordinal Regression
Princeton University
2024-02-25
This is a cat, not a dog?

- Very likely to be a dog
- Somewhat likely to be a dog
- As likely to be cat or dog
- Somewhat likely to be a cat
- Very likely to be a cat
“Analyzing ordinal data with metric models: What could possibly go wrong?”
Three main shortcomings of metric models:
- Response categories may not be (e.g. psychologically) equidistant

“Analyzing ordinal data with metric models: What could possibly go wrong?”
Response categories may not be (e.g. psychologically) equidistant
Responses can be non-normally distributed
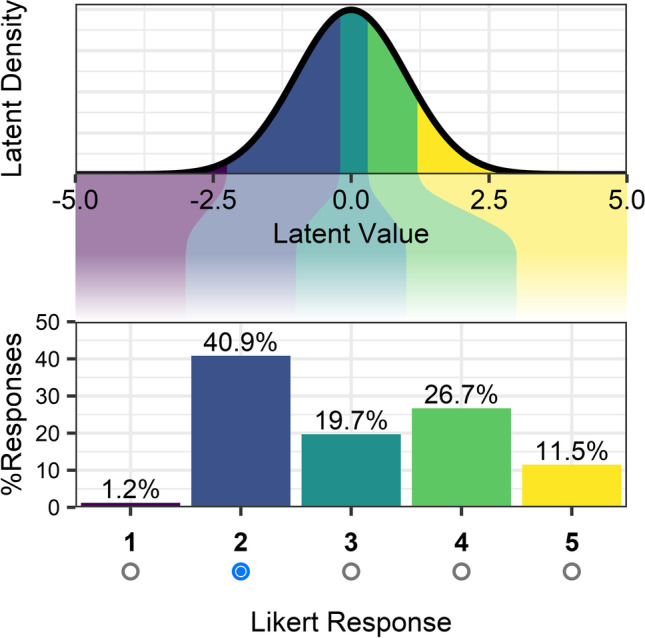
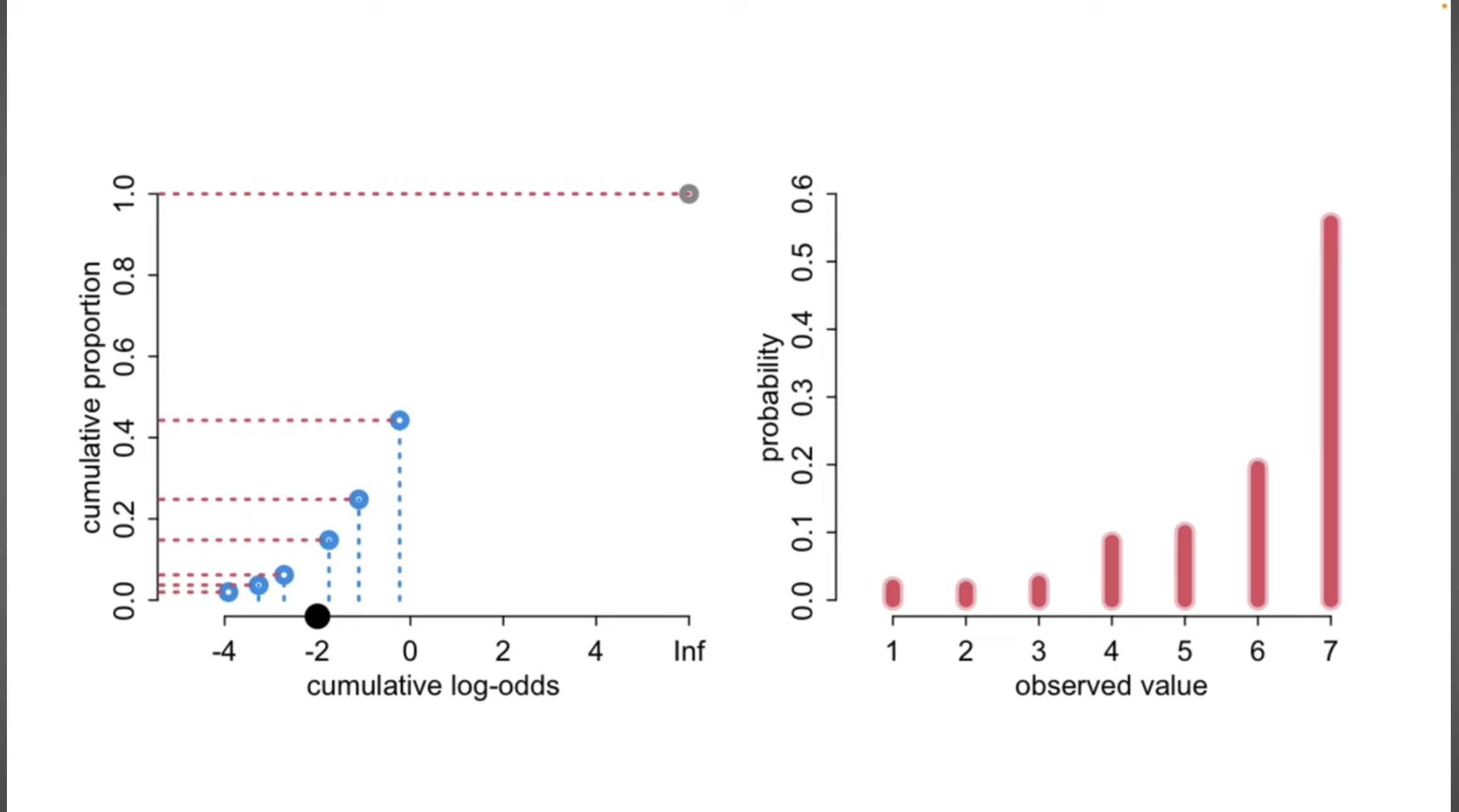
Cumulative model: Latent variable interpretation
A simple motivation
You have a continuous latent variable \(\tilde{Y}\) that can be be categorized into bins (K thresholds): \(\tau = (\tau_1, \dots, \tau_k)\)
- Latent Honey’s catness
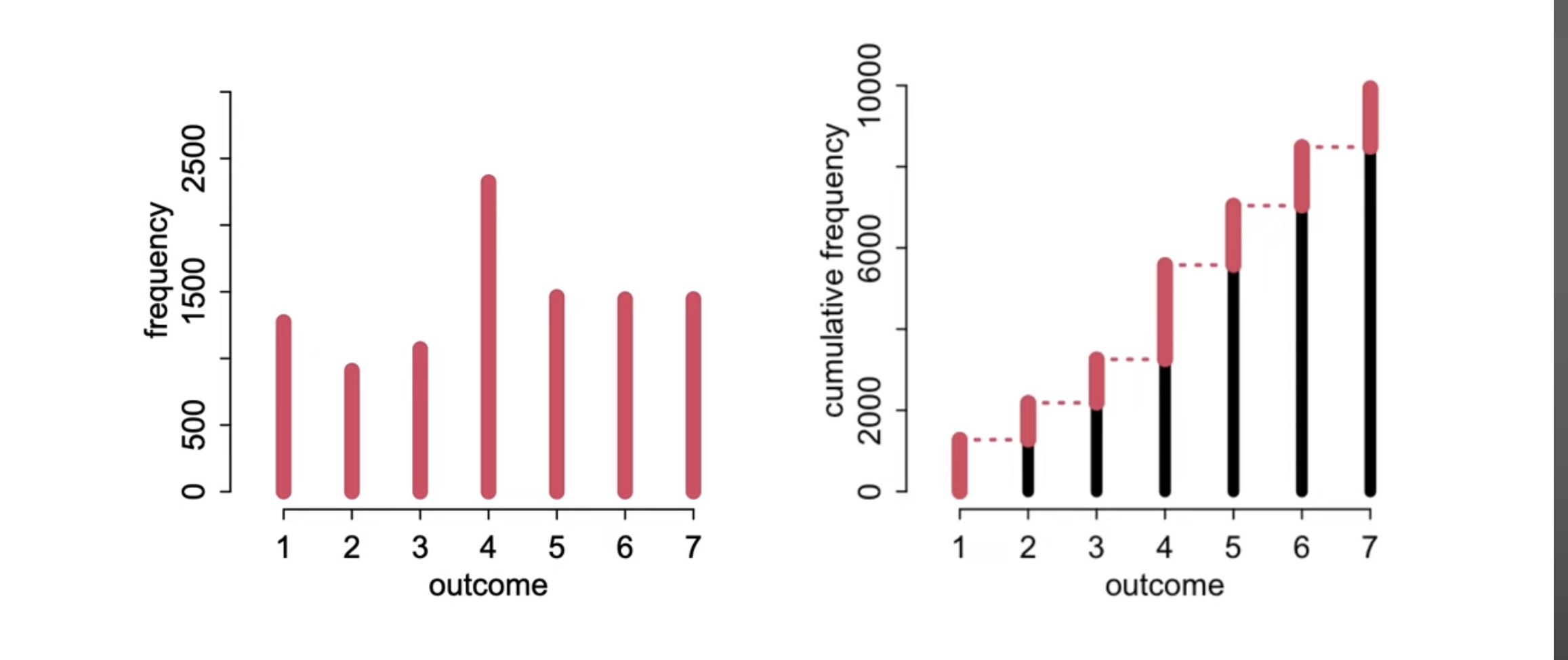
Ordered = Cumulative
- We will use the cumulative distribution to model our ordered categories
Cumulative probability
- \(F(x) = P(X \leq x)\)
- Preserves order
- \(F(x) = P(X \leq x)\)
Cumulative logit model
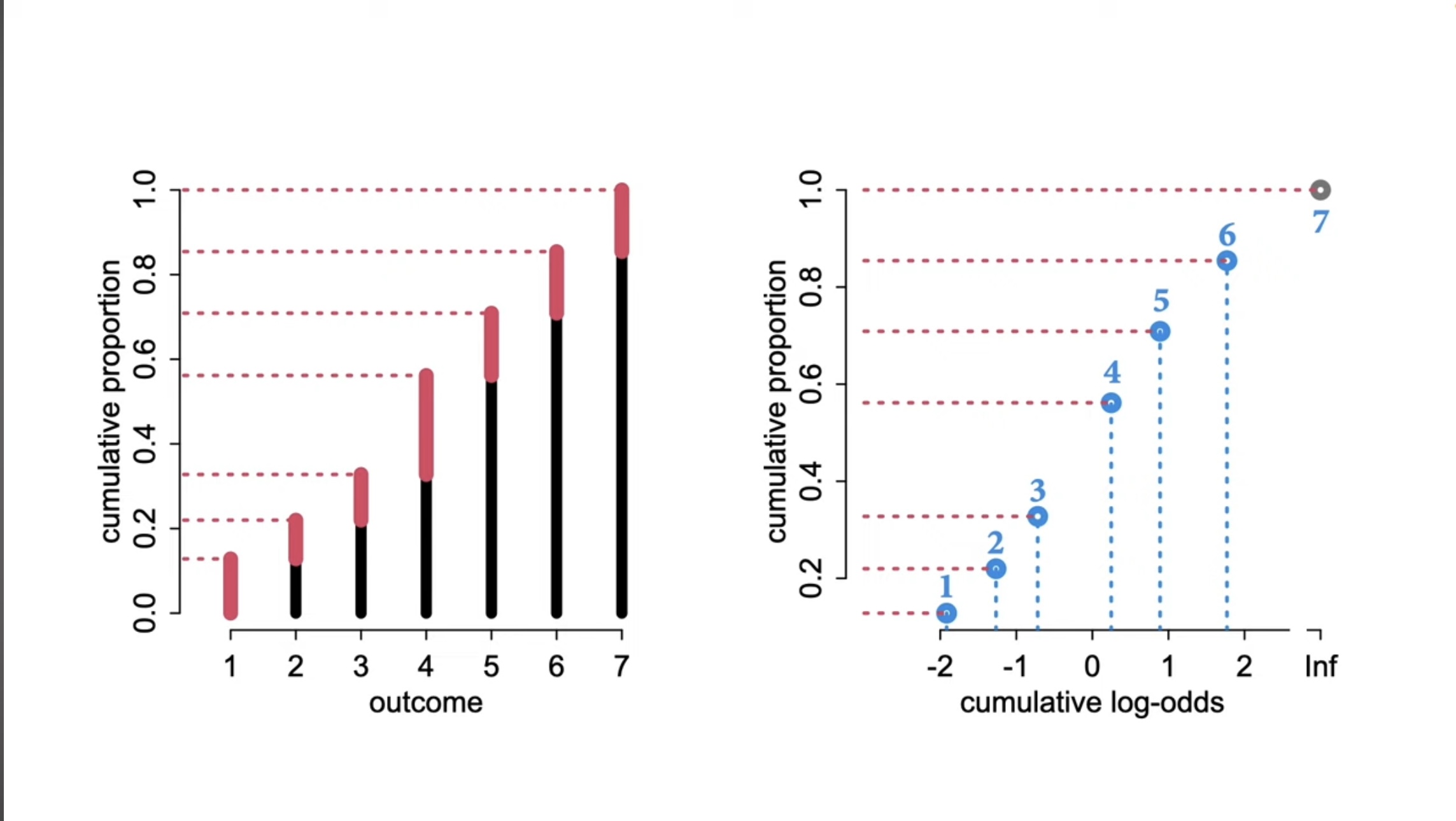
Richard McElreath
Cumulative logit model
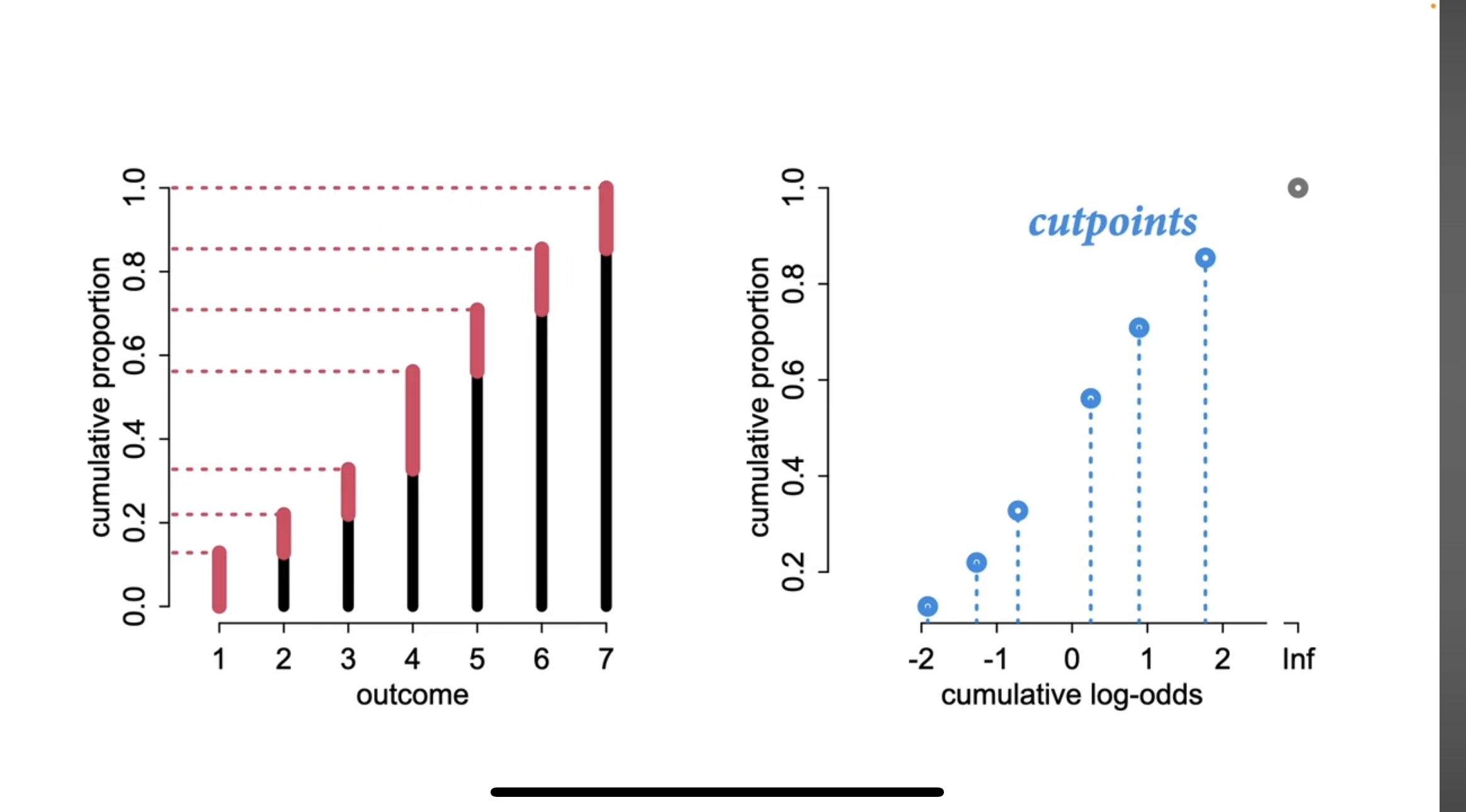
Richard McElreath
Cumulative logit model
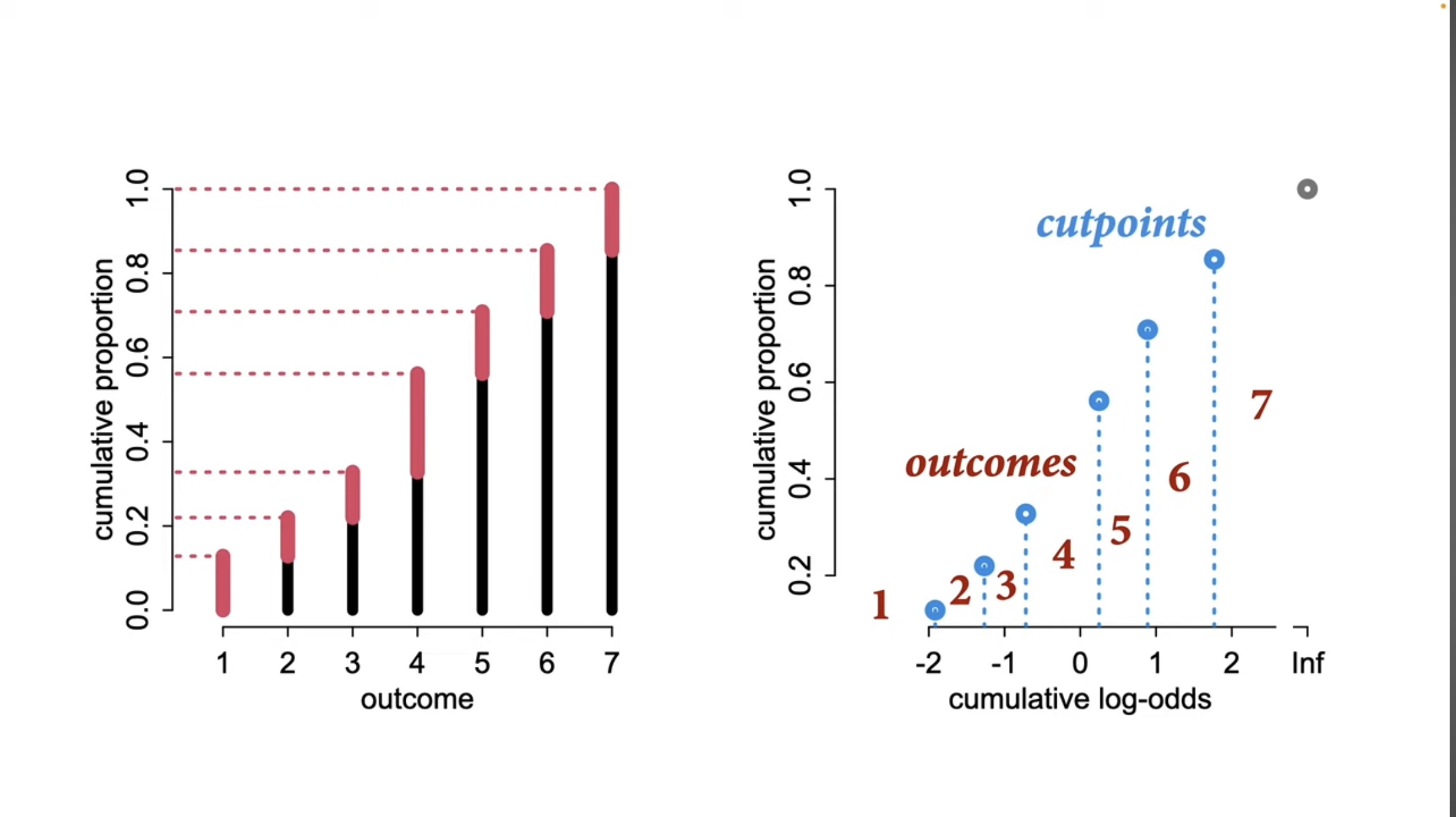
Richard McElreath
Cumulative logit ordinal regression model
- Normal parametrization (with addition)
- Higer coefs = higher probability of being in lower categories
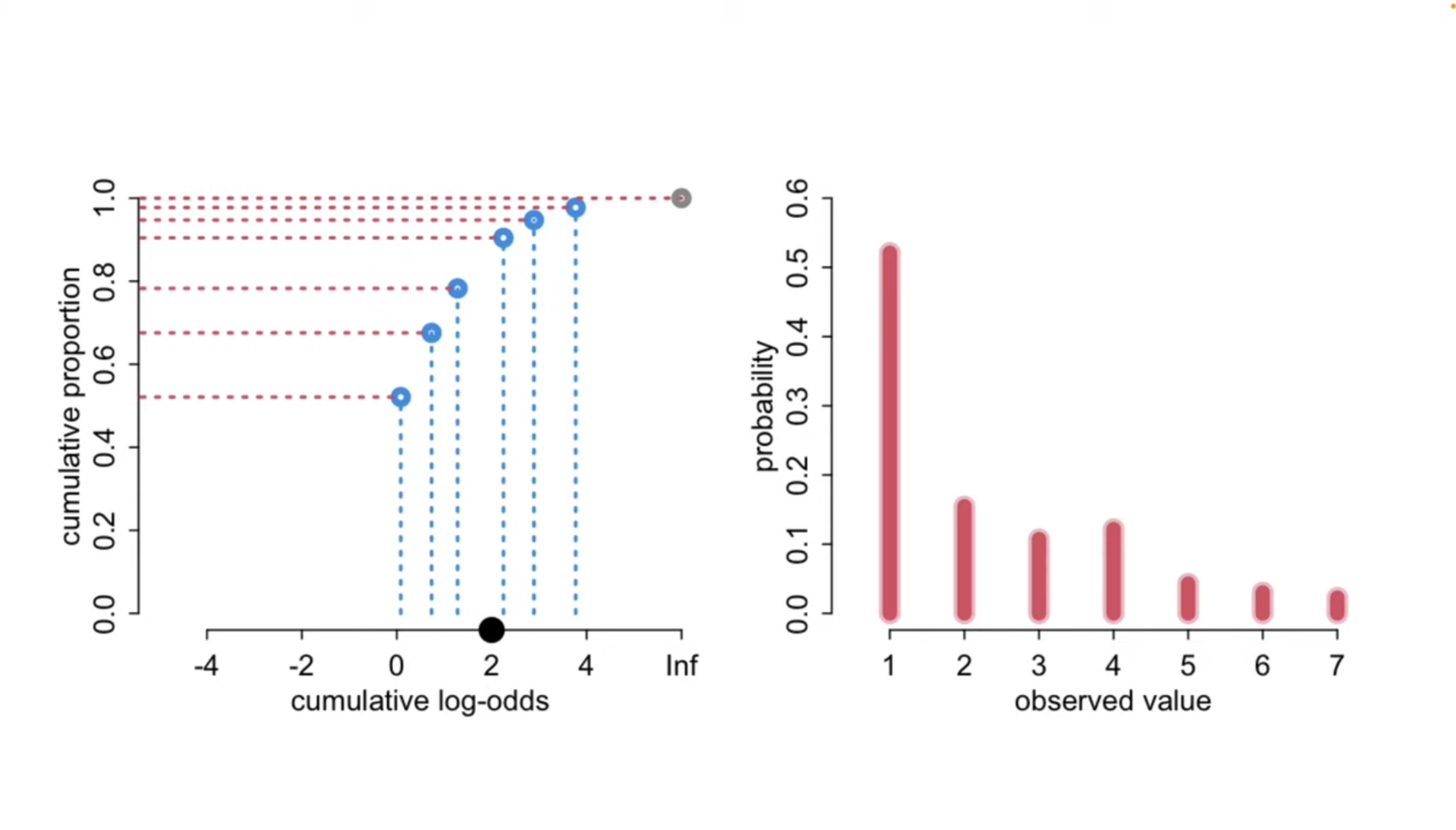
- lower coefs = lower probablity in lower categories
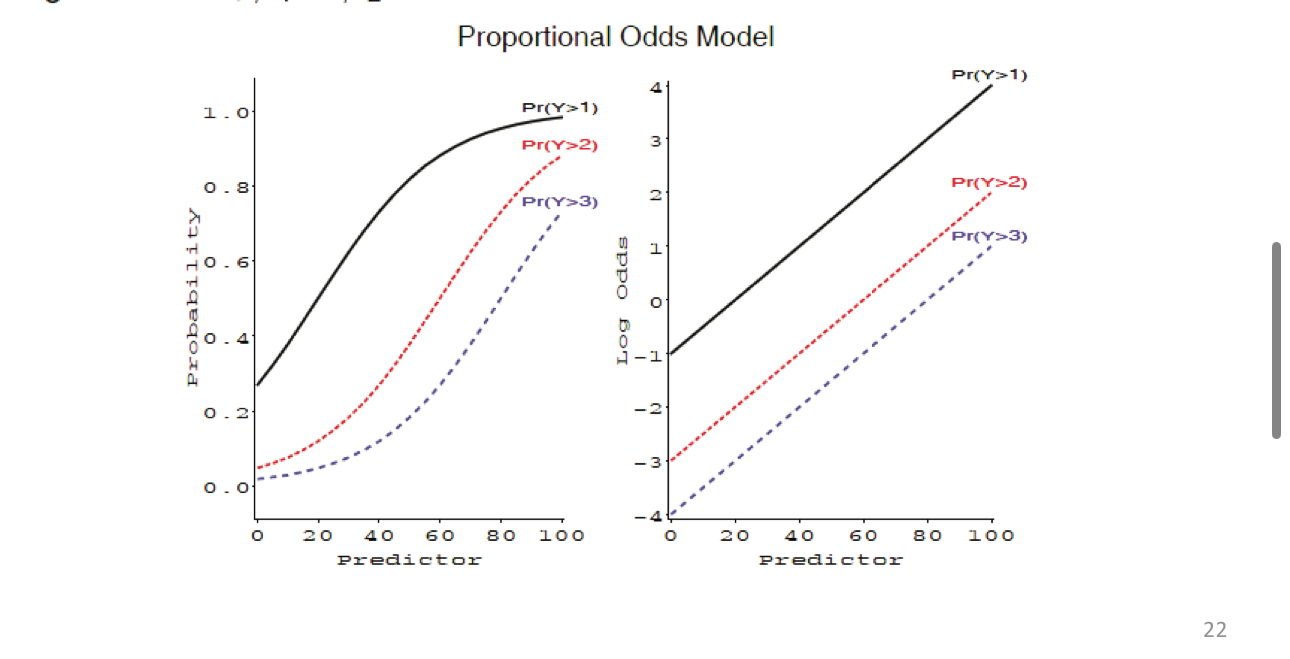
Proportional odds assumption
- Assumes slope is equal between categories
- Critical for interpretation!
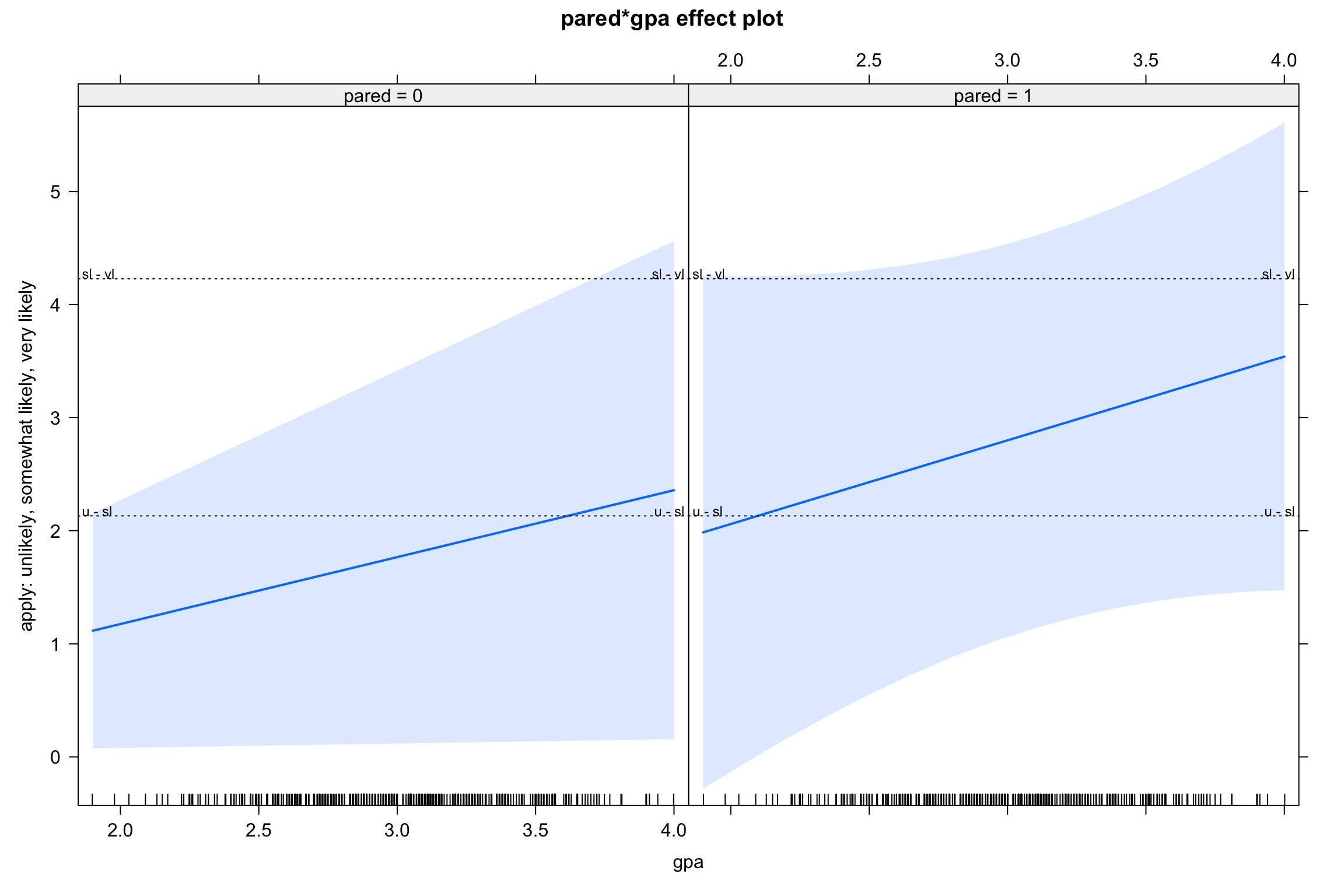
Model visualizations
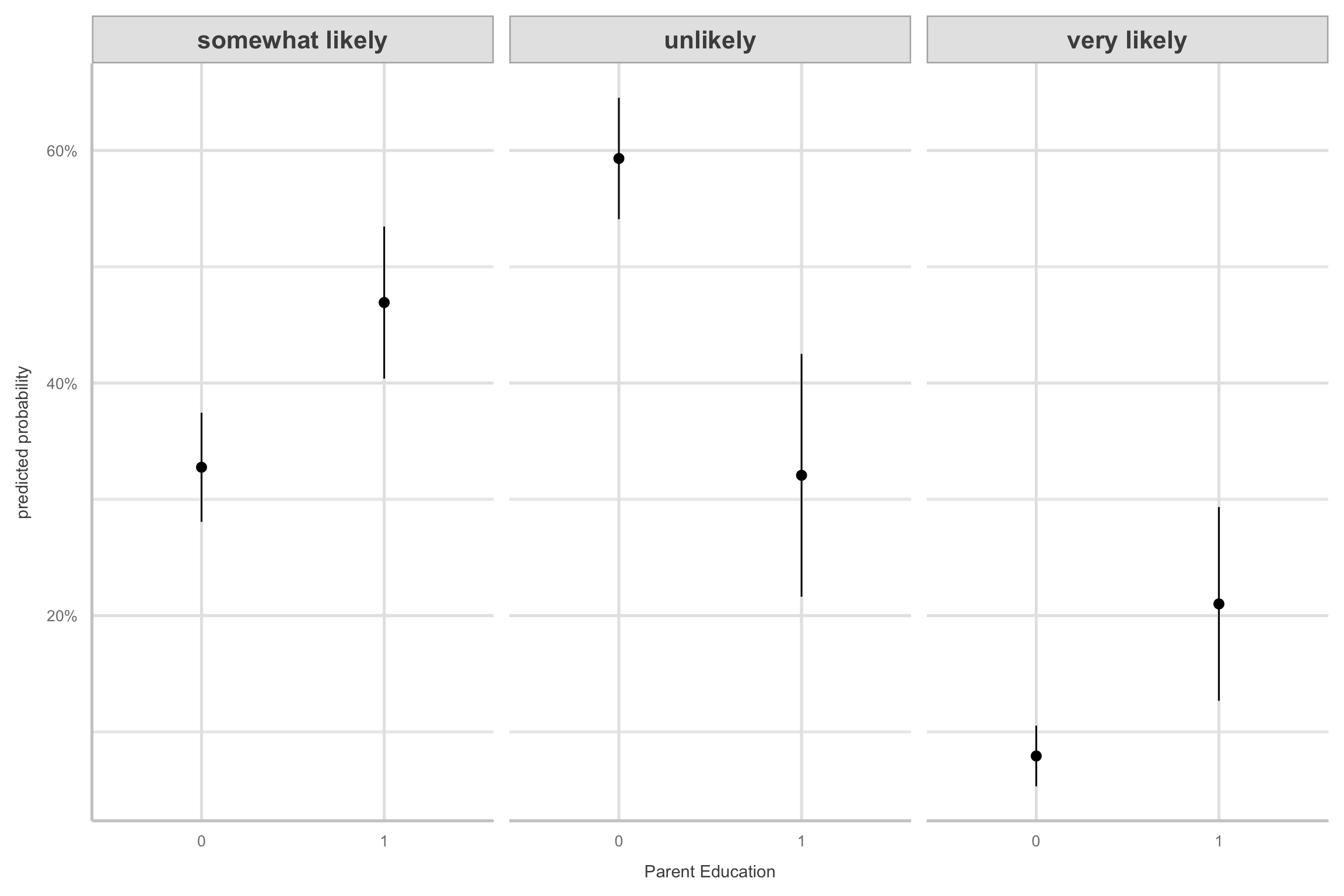
- How could we make the figure better?
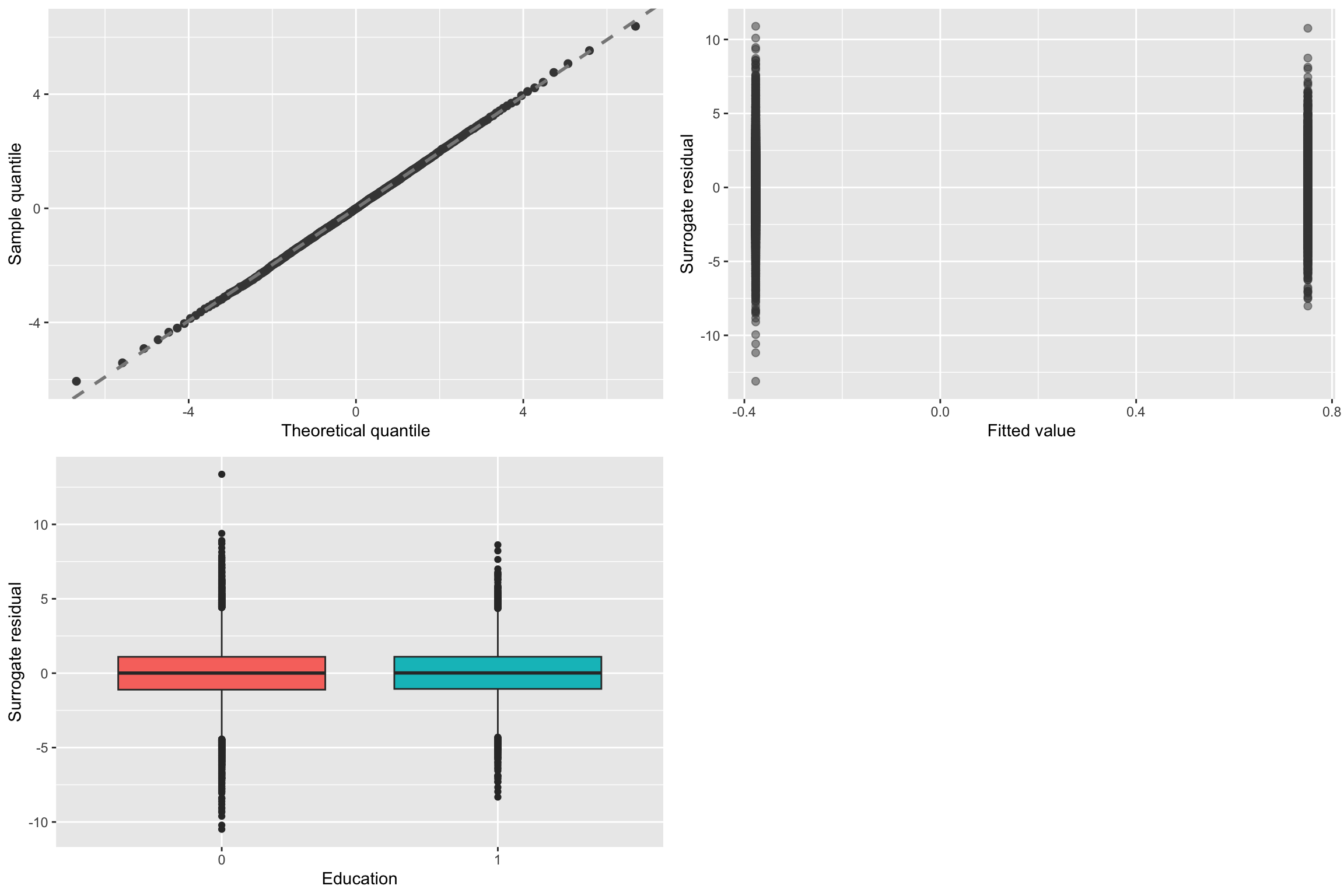
Test ordinal assumptions
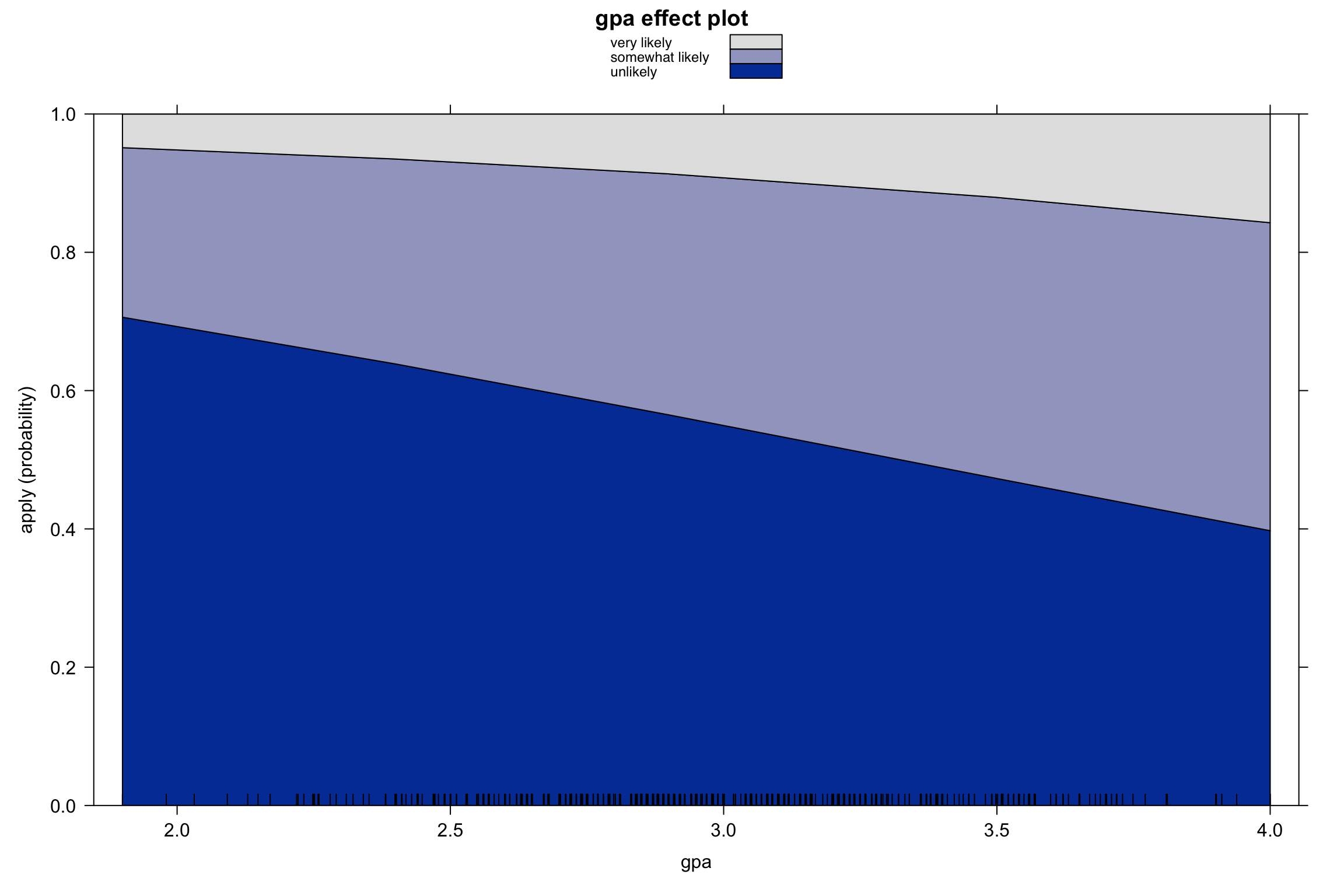
Visualization: stacked area plots (continuous predictors)
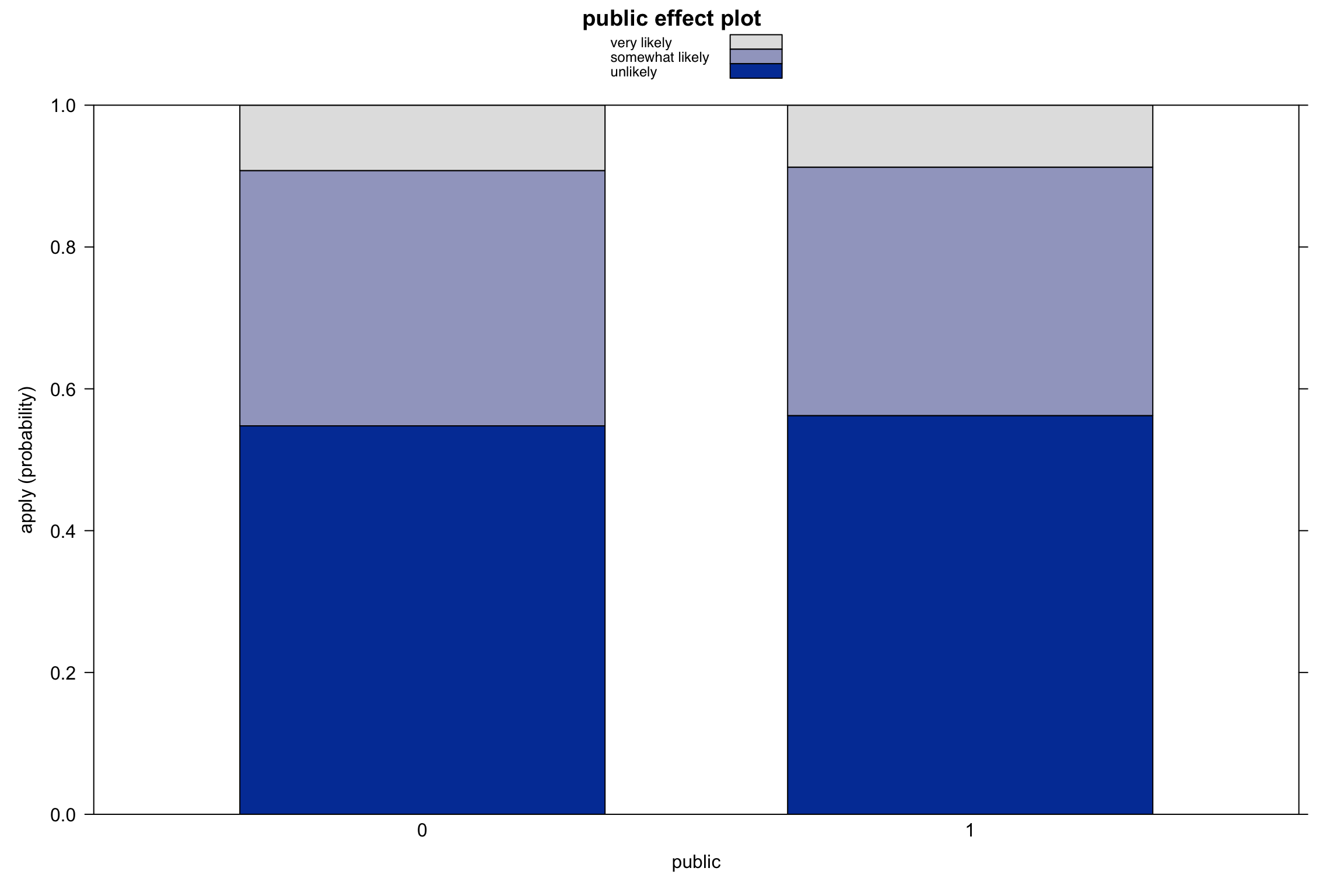
Visualization: stacked area plots (categorical predictors)
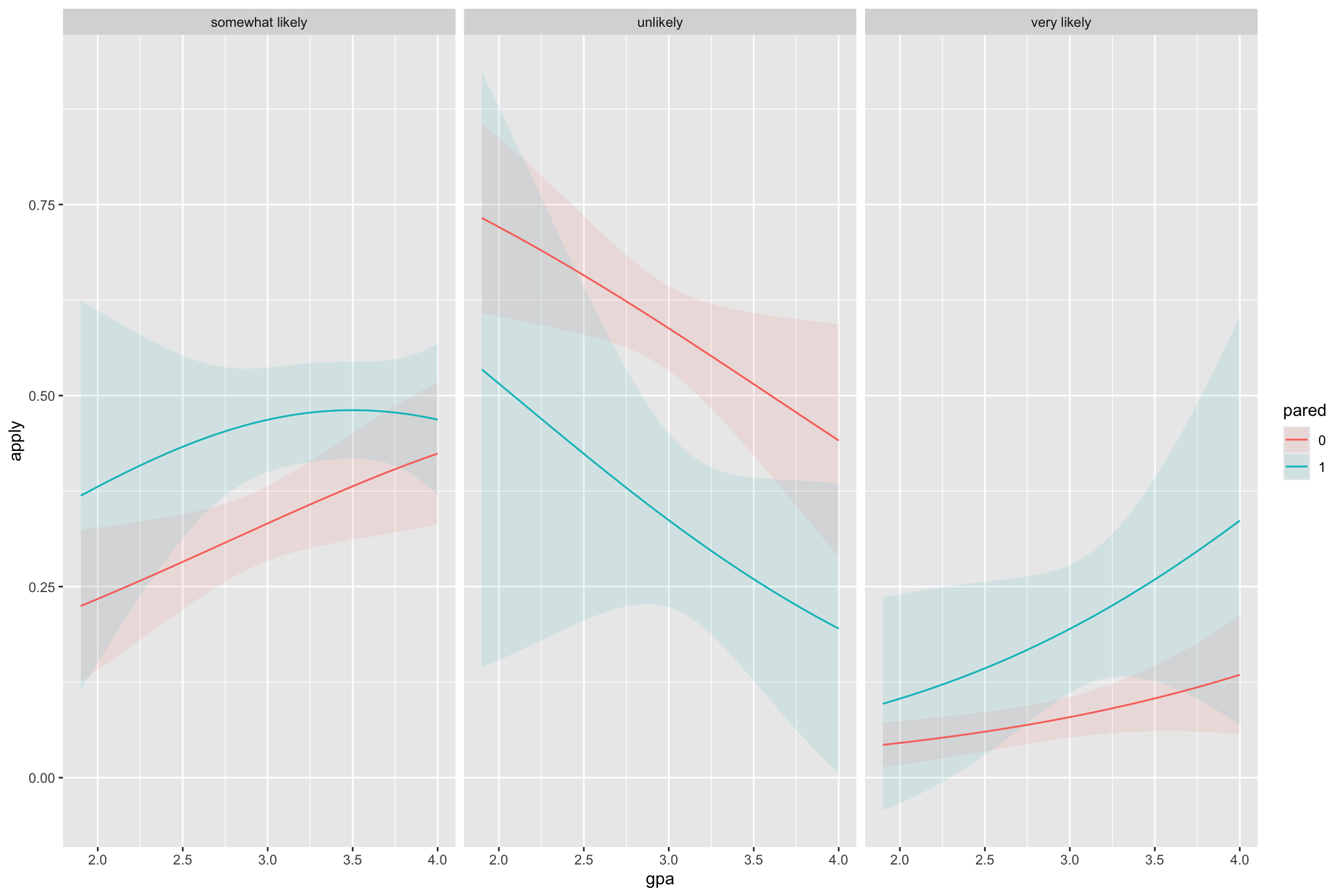
Visualization: Interactions
Latent scale